Redis主从复制详解
笔记哥 /
05-30 /
28点赞 /
0评论 /
566阅读
## 概述
Redis 的主从复制(Master-Slave Replication)是实现数据备份、读写分离和水平扩展的核心机制之一。通过主从复制,一个主节点(Master)可以将数据同步到多个从节点(Slave),从节点还可以级联创建自己的从节点,从而形成树状结构。
注意,Redis的主从复制是实现高可用的核心机制,并不能实现高可用
## Redis主从复制作用
### 数据冗余:
主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
### 故障恢复
当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。
### 负载均衡:
在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
### 读写分离:
可以用于实现读写分离,主库写、从库读,读写分离不仅可以提高服务器的负载能力,同时可根据需求的变化,改变从库的数量。
### 高可用基石
除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础。
## Redis主从复制搭建
### 搭建主服务器
>
>
> 参考这篇文章:[Redis6.2.x版本安装](https://www.cnblogs.com/huangSir-devops/p/18884655#_label4 "Redis6.2.x版本安装")
>
### 搭建从服务器
>
>
> 参考这篇文章:[Redis6.2.x版本安装](https://www.cnblogs.com/huangSir-devops/p/18884655#_label4 "Redis6.2.x版本安装")
>
需要注意从服务器配置文件的修改:
```csharp
# 第75行,修改远程访问地址
75:bind 0.0.0.0
# 第98行,修改端口号
98:port 6379
# 第259行,守护进程运行,默认位前台运行,需要修改为yes
259:daemonize yes
# 第304行,指定redis的日志
304:logfile "/var/log/redis/redis.log"
# 第329行,指定数据库的数量,默认是16个
329:databases 16
# 第433行,持久化的文件
433:dbfilename dump.rdb
# 第456行,设置redis的数据目录,和我们上面创建的路径保持一致
456:dir /data00/data/redis/
# 第903行,设置密码,建议不要使用弱密码
903:requirepass 123456
# 第479行,主库的IP和端口
479:replicaof 127.0.0.1 6379
# 第486行,如果主服务器设置了密码,需要配置认证
486:masterauth !Xinxin123
# 其它配置
# 从服务器是否可写(默认只读)
replica-read-only yes
# 复制缓冲区大小
repl-backlog-size 1mb
# 复制超时时间(秒)
repl-timeout 60
# 当主从断开时,从服务器是否继续提供服务
replica-serve-stale-data yes
```
启动主库之后再启动从库
```csharp
[root@node01 ~]# redis-server /data00/data/redis/redis.conf
[root@node01 ~]# ss -lntup | grep 6379
tcp LISTEN 0 511 127.0.0.1:6379 0.0.0.0:* users:(("redis-server",pid=1001533,fd=6))
tcp LISTEN 0 511 [::1]:6379 [::]:* users:(("redis-server",pid=1001533,fd=7))
```
### 验证主从复制是否成功
在主从分别执行`INFO REPLICATION`命令
```csharp
# 主库执行
127.0.0.1:6379> INFO REPLICATION
# Replication
role:master
connected_slaves:1
slave0:ip=10.37.99.63,port=6379,state=online,offset=98,lag=0
master_failover_state:no-failover
master_replid:2f61b8be8cbf19e45882f77bea61b55862bf74e5
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:98
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:98
# 从库执行
127.0.0.1:6379> INFO REPLICATION
# Replication
role:slave
master_host:10.37.97.56
master_port:6379
master_link_status:up
master_last_io_seconds_ago:4
master_sync_in_progress:0
slave_read_repl_offset:238
slave_repl_offset:238
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:2f61b8be8cbf19e45882f77bea61b55862bf74e5
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:238
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:238
```
验证主库写入数据,从库是否能获取到
```csharp
# 主库写入数据
127.0.0.1:6379> set rep rep
OK
# 从库查询数据
127.0.0.1:6379> get rep
"rep"
```
验证从库写数据,预期应该报错
```csharp
127.0.0.1:6379> set slave 1
(error) READONLY You can't write against a read only replica.
```
## Redis主从复制原理
主从复制过程大体可以分为3个阶段:连接建立阶段(即准备阶段)、数据同步阶段、命令传播阶段。
在从节点执行 slaveof 命令后,复制过程便开始运作,下面图示可以看出复制过程大致分为6个过程。

1. 保存主节点信息
执行slaveof后 Redis会打印如下日志:

1. 从节点与主节点建立网络连接
从节点(slave)内部通过每秒运行的定时任务维护复制相关逻辑,当定时任务发现存在新的主节点后,会尝试与该节点建立网络连接。
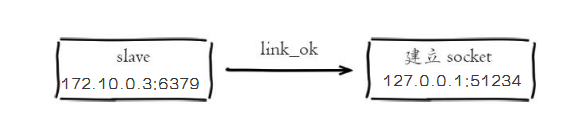
从节点会建立一个 socket 套接字,从节点建立了一个端口为51234的套接字,专门用于接受主节点发送的复制命令。从节点连接成功后打印如下日志:

如果从节点无法建立连接,定时任务会无限重试直到连接成功或者执行 slaveofnoone 取消复制。
关于连接失败,可以在从节点执行 info replication 查看 master\_link\_down\_since\_seconds 指标,它会记录与主节点连接失败的系统时间。从节点连接主节点失败时也会每秒打印如下日志,方便发现问题:

1. 发送ping命令
连接建立成功后从节点发送 ping 请求进行首次通信, ping 请求主要目的如下:
- 检测主从之间网络套接字是否可用。
- 检测主节点当前是否可接受处理命令。
如果发送 ping 命令后,从节点没有收到主节点的 pong 回复或者超时,比如网络超时或者主节点正在阻塞无法响应命令,从节点会断开复制连接,下次定时任务会发起重连。

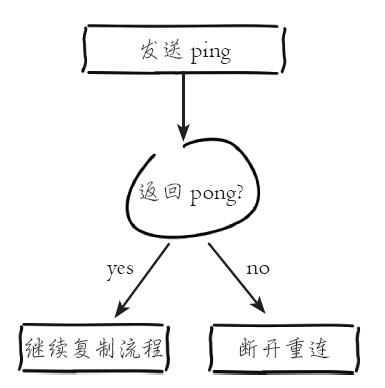
从节点发送的 ping 命令成功返回,Redis 打印如下日志,并继续后续复制流程:

1. 权限验证
如果主节点设置了 requirepass 参数,则需要密码验证,从节点必须配置 masterauth 参数保证与主节点相同的密码才能通过验证。如果验证失败复制将终止,从节点重新发起复制流程。
1. 同步数据集
主从复制连接正常通信后,对于首次建立复制的场景,主节点会把持有的数据全部发送给从节点,这部分操作是耗时最长的步骤。
1. 命令持续复制
当主节点把当前的数据同步给从节点后,便完成了复制的建立流程。接下来主节点会持续地把写命令发送给从节点,保证主从数据一致性。
## 主从复制数据同步原理
Redis支持主从复制,Redis的主从结构可以采用一主多从或者级联结构,Redis主从复制可以根据是否是全量分为全量同步和增量同步。下图为级联结构。

### 全量同步阶段
Redis全量同步一般发生在Slave初始化阶段,这时Slave需要将Master上的所有数据都复制一份。具体步骤如下:
- 从服务器配置主服务器的连接信息(slaveof属性);
- 从服务器连接上主服务器,发送SYNC命令
- 主服务器判断是否为全量复制:如果是全量复制,则进入下一步;否则可以看增量复制的子流程。
- 主服务器接收到SYNC命名后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记录此后执行的所有写命令;
- 主服务器BGSAVE执行完后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命令;
- 从服务器收到快照文件后丢弃所有旧数据,载入收到的快照;
- 主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令;
- 从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令;

### 增量同步阶段
Redis增量复制是指Slave初始化后开始正常工作时主服务器发生的写操作同步到从服务器的过程。
增量复制的过程主要是主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令。
## 开启无磁盘同步
Redis在与从数据库进行复制初始化时将不会将快照存储到磁盘,而是直接通过网络发送给从数据库,避免了IO性能差问题。
启动无磁盘复制:
```csharp
repl-diskless-sync yes
```
本文来自投稿,不代表本站立场,如若转载,请注明出处:http//www.knowhub.vip/share/2/3865
- 热门的技术博文分享
- 1 . ESP实现Web服务器
- 2 . 从零到一:打造高效的金仓社区 API 集成到 MCP 服务方案
- 3 . 使用C#构建一个同时问多个LLM并总结的小工具
- 4 . .NET 原生驾驭 AI 新基建实战系列Milvus ── 大规模 AI 应用的向量数据库首选
- 5 . 在Avalonia/C#中使用依赖注入过程记录
- 6 . [设计模式/Java] 设计模式之工厂方法模式
- 7 . 5. RabbitMQ 消息队列中 Exchanges(交换机) 的详细说明
- 8 . SQL 中的各种连接 JOIN 的区别总结!
- 9 . JavaScript 中防抖和节流的多种实现方式及应用场景
- 10 . SaltStack 远程命令执行中文乱码问题
- 11 . 推荐10个 DeepSeek 神级提示词,建议搜藏起来使用
- 12 . C#基础:枚举、数组、类型、函数等解析
- 13 . VMware平台的Ubuntu部署完全分布式Hadoop环境
- 14 . C# 多项目打包时如何将项目引用转为包依赖
- 15 . Chrome 135 版本开发者工具(DevTools)更新内容
- 16 . 从零创建npm依赖,只需执行一条命令
- 17 . 关于 Newtonsoft.Json 和 System.Text.Json 混用导致的的序列化不识别的问题
- 18 . 大模型微调实战之训练数据集准备的艺术与科学
- 19 . Windows快速安装MongoDB之Mongo实战
- 20 . 探索 C# 14 新功能:实用特性为编程带来便利