VMware平台的Ubuntu部署完全分布式Hadoop环境
笔记哥 /
04-15 /
21点赞 /
0评论 /
821阅读
# 前言:
此文章是本人初次部署Hadoop的过程记录以及所遇到的问题解决,这篇文章只有实际操作部分,没有理论部分。因本人水平有限,本文难免存在不足的地方,如果您有建议,欢迎留言或私信告知于我,非常感谢。
部分参考网络资料,如有侵权,联系删除。
# 环境准备(需提前下载好):
1.VMware workstation 17.5,作为虚拟化平台
(官网下载地址:[vmware workstation17.5(需登录)](https://www.vmware.com/products/desktop-hypervisor/workstation-and-fusion))
2.Ubuntu20.04 (18.04,22.04,24.04应该也可以)
(清华源镜像地址:[Ubuntu20.04](https://mirrors.tuna.tsinghua.edu.cn/ubuntu-releases/20.04/ubuntu-20.04.6-desktop-amd64.iso))
3.JDK8(其他版本不适配)
(官网下载链接(需登录):[下载页面(选x64 Compressed Archive)](https://www.oracle.com/java/technologies/downloads/#java8))
(清华源的openjdk下载链接: [openjdk8](https://mirrors.tuna.tsinghua.edu.cn/Adoptium/8/jdk/x64/linux/OpenJDK8U-jdk_x64_linux_hotspot_8u442b06.tar.gz))
4.Hadoop-3.3.6
(官网下载链接:[Hadoop-3.3.6](https://dlcdn.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz))
# 1.安装Ubuntu
(1)点击创建新的虚拟机
(如果没有这一页,可以点击上面的选项卡,再点击转到主页)

(2)点击自定义,下一步

(3)默认即可,点下一步

(4)点稍后安装操作系统,下一步

(5)这里选Linux,版本Ubuntu 64位

(6)点击浏览选择合适的存储位置

(7)处理器数量和内核数量选 1

(8)内存4GB,可根据个人情况调整(如果物理机只有16G,可改为3GB(3072MB))。

(9)均默认,点下一步




(10)建议磁盘大小30G,避免后续使用时空间不足,可根据个人情况调整
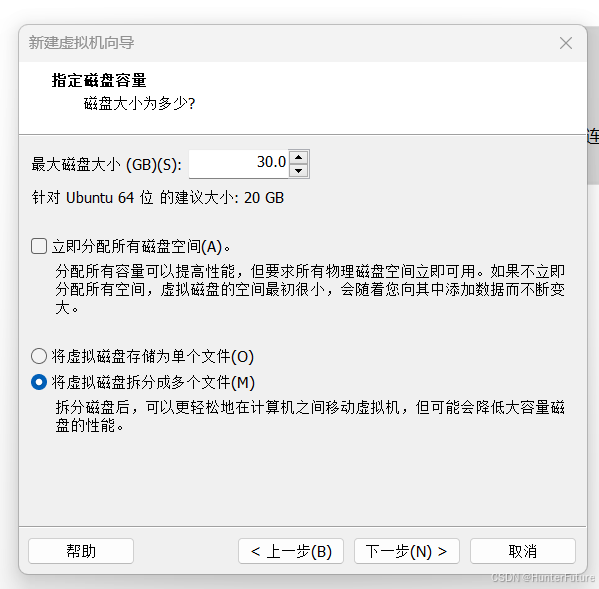
(11)默认,点下一步

(12)点击完成

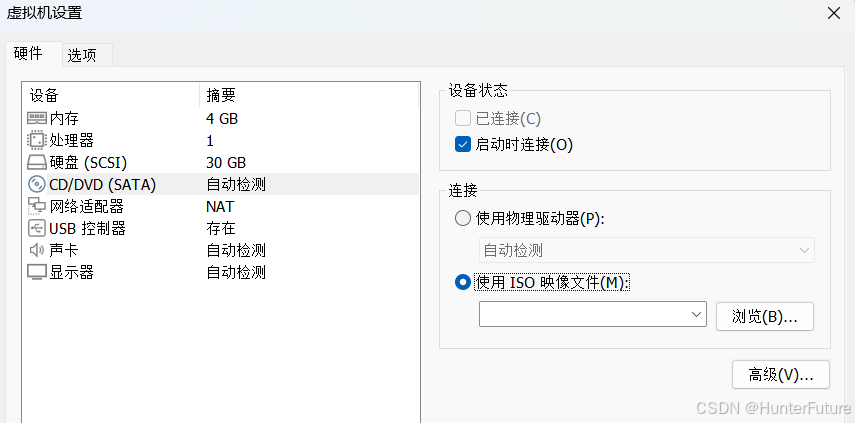
(13)点编辑虚拟机设置

(14)点击CD/DVD,点击“使用ISO镜像文件”,再点击浏览,找到刚刚下载的Ubuntu20.04镜像
(15)点击Install Ubuntu ,建议使用英文,避免中文报错。

(16)点continue,
这里如果窗口太小,看不到按钮,同时按Alt + F7,然后会出现一个手的标志,可以移动窗口,再点击鼠标左键来固定
(17)点Minimal installation,点continue

(18)默认,点Install Now

(19)点击 continue

(20)默认,点击continue

(21)
Your name 填Hadoop
Your conputer's name 填master
设置好密码后,点continue

(22)等待安装

(23)安装完成,点击Restart Now

(24)这里直接按回车即可

(25)点击Hadoop,输入密码
注意:Ubuntu安装之后,数字小键盘默认关闭,按键盘上NumLock打开。

(26)进入之后的设置,全部点击右上角的skip和next即可

(27)会有版本更新弹窗,点击Don't Upgrade,再点击OK


(28)右上角会有一个红色圆圈,点击,再点Show update,然后点击Install Now,之后输入密码,更新即可。




(29)如果窗口太小,按Ctrl+Alt+T打开终端,输入下面两行代码,运行结束之后再重启一下虚拟机。
```bash
sudo apt update
```
```bash
sudo apt install open-vm-tools-desktop -y
```
注:输入 sudo apt update后,如果第(28)的更新未完成的话,会报错,等待更新完成再输入即可

(30)现在第一个虚拟机以及创建完毕。
创建第二个和第三个虚拟机时,只有第(21)不一样,
第二个虚拟机的Your conputer's name 填slave01
第三个虚拟机的Your conputer's name 填slave02
# 2.配置hosts网络映射(三个机器均需要)
(1)输入命令,安装网络工具
注:Ubuntu中,Ctrl + Shift + C 是复制,Ctrl + Shift + V 是粘贴
```bash
sudo apt install net-tools
```
(2)输入命令查看ip地址
```bash
ifconfig
```
图中第三行的192.168.61.142为本机IP,每个人电脑不相同。
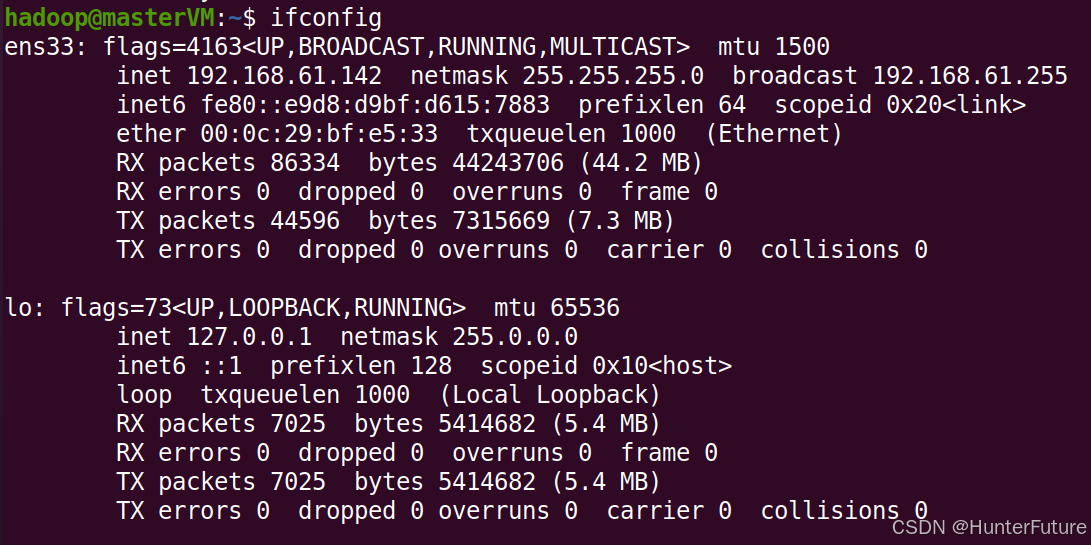
(3)在slave01机器和slave02机器执行相同操作,并记下IP。
我的slave01的IP:192.168.61.143

我的slave02的IP:192.168.61.144

(4)三个机器都下载vim,方便后续使用。
```bash
sudo apt install vim -y
```
(5)编辑修改hosts文件,使节点之间通信方便
```bash
sudo vim /etc/hosts
```
进入之后,如下图所示
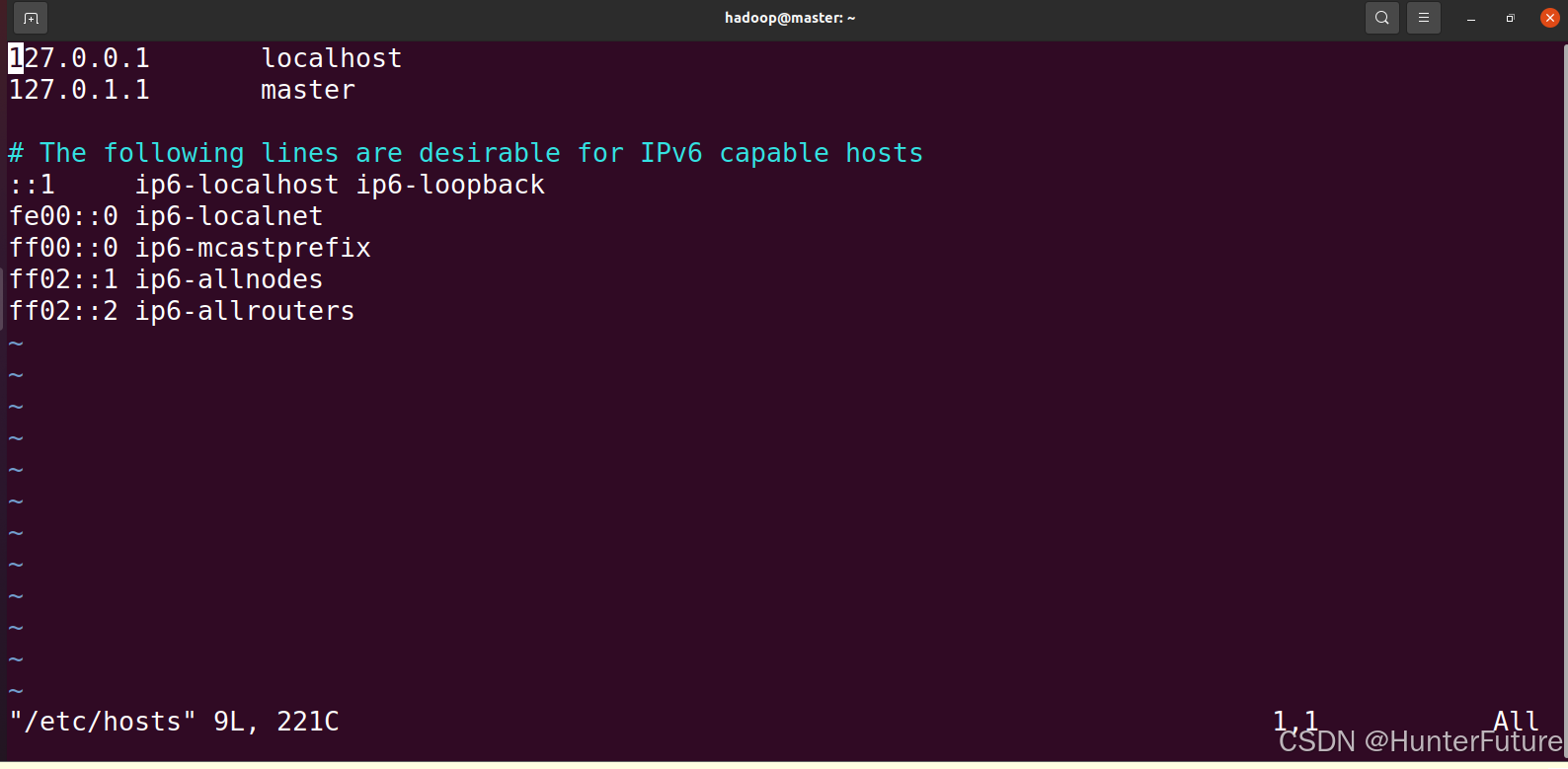
按键盘“ i ”进入编辑模式(插入模式),然后用上下左右方向键移动光标到第三行,输入刚刚查询到的IP,然后加上机器名(@后面的)
例:【hadoop@master:~$】,中,master是机器名。
编辑好后如图所示(ip地址不相同,根据自己Ubuntu的IP来修改)

编辑好之后,按键盘左上角ESC退出编辑模式,再按Shift + “;”,左下角会出现一个冒号“:”,然后输入“wq”保存并退出文件。
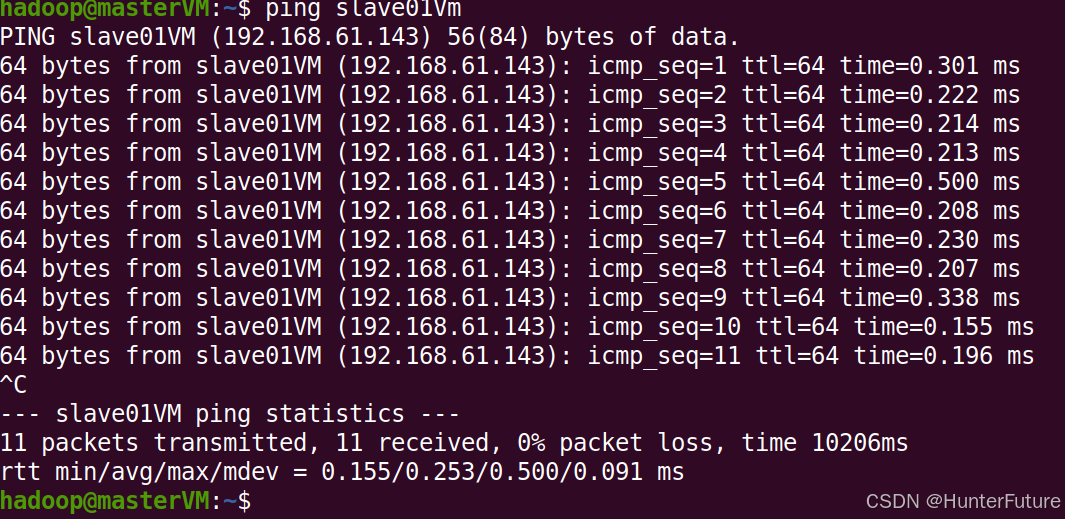
(6)配置好hosts后,使用ping命令来测试是否配置成功,之后在另外两个机器也配置。
```bash
ping slave01
ping slave02
```
出现如图类似之后,即hosts配置成功,按Ctrl + C 终止,
# 3.Java JDK8 配置(三个机器均需要)
(1)在自己电脑下载好JDK之后,粘贴到虚拟机的`Downloads`里,鼠标右键,点Paste即可粘贴。
注:打开左边第二个图标,打开之后点`Downloads`,再粘贴
(也可以复制链接到虚拟机的浏览器,直接在虚拟机下载,省的再复制粘贴)

注:如果出现类似报错,点击Retry再点击Skip。如果不行的话就等待一会再复制粘贴试试。如果还是不行,执行下面的命令之后重启虚拟机。

```bash
sudo apt update
sudo apt autoremove open-vm-tools -y
sudo apt install open-vm-tools-desktop -y
```
(2)执行命令,解压jdk
注:这里`jdk-8u441-linux-x64.tar.gz`不一定相同,根据个人情况修改,可以输入jdk之后,按Tab键自动补全。
```bash
cd /usr/lib
sudo mkdir jvm
cd ~/Downloads //即 cd /home/hadoop/Downloads
sudo tar -zxvf jdk-8u441-linux-x64.tar.gz -C /usr/lib/jvm
```
(3)查看具体安装的jdk版本号,例如我的是`jdk1.8.0_441`
```bash
cd /usr/lib/jvm
ls
```

(4)配置java环境变量
```bash
sudo vim ~/.bashrc
```
进入文件后,按上下方向键,翻到最后,插入下面语句
注:第一句的jdk不一定相同,根据第三步查询的来修改。
```bash
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_441
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
```
执行命令:`source ~/.bashrc`,然后关闭终端,再重新打开,输入`java -version`,如下图所示即配置成功

(5)在slave01和slave02执行相同的1~4,完成配置
# 4.SSH 配置(三个机器均需要)
(1)安装ssh
```bash
sudo apt install openssh-server -y
```
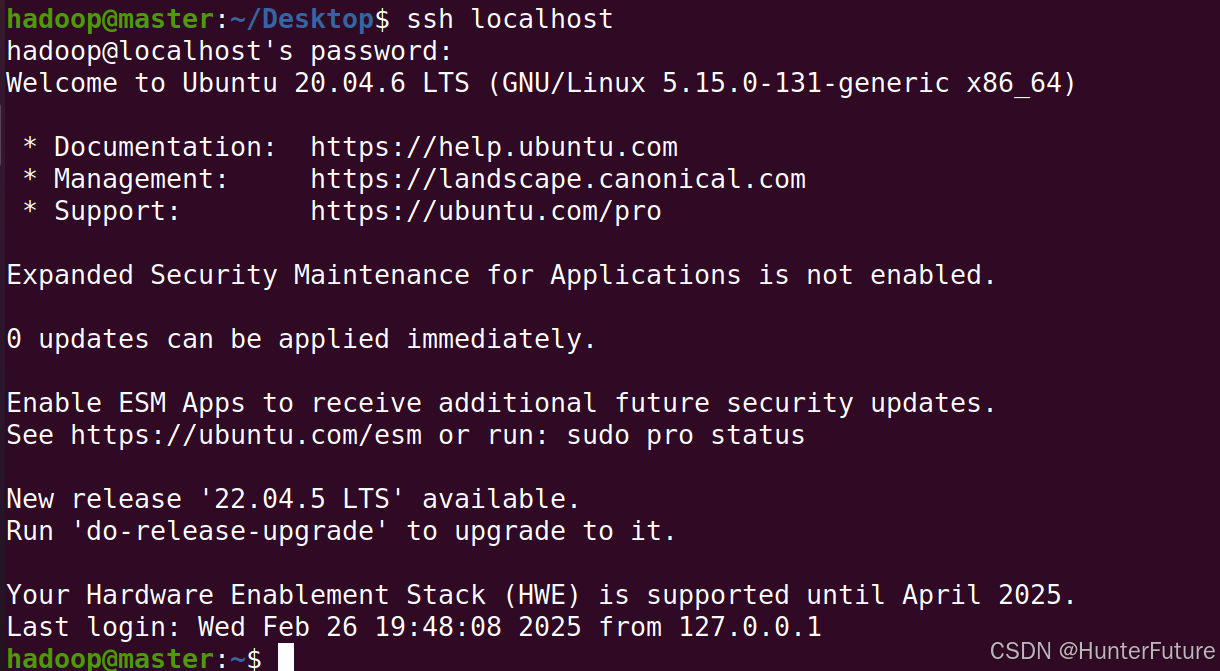
(2)测试登录本地,验证是否成功。
```bash
ssh localhost
```
输入之后,会停顿一下,如下图,然后输入`yes`,之后会让输入本机密码。

成功登录如图
然后输入`exit` 会出现退出登录信息

(3)前两步骤三个机器均需下载,下载完成之后在进行第四步。
(4)在master节点生成公钥
```bash
cd ~/.ssh
rm ./id_rsa* //如果是第一次下载ssh,可以不执行这一句
ssh-keygen -t rsa //输入之后有停顿,全部按回车即可
```
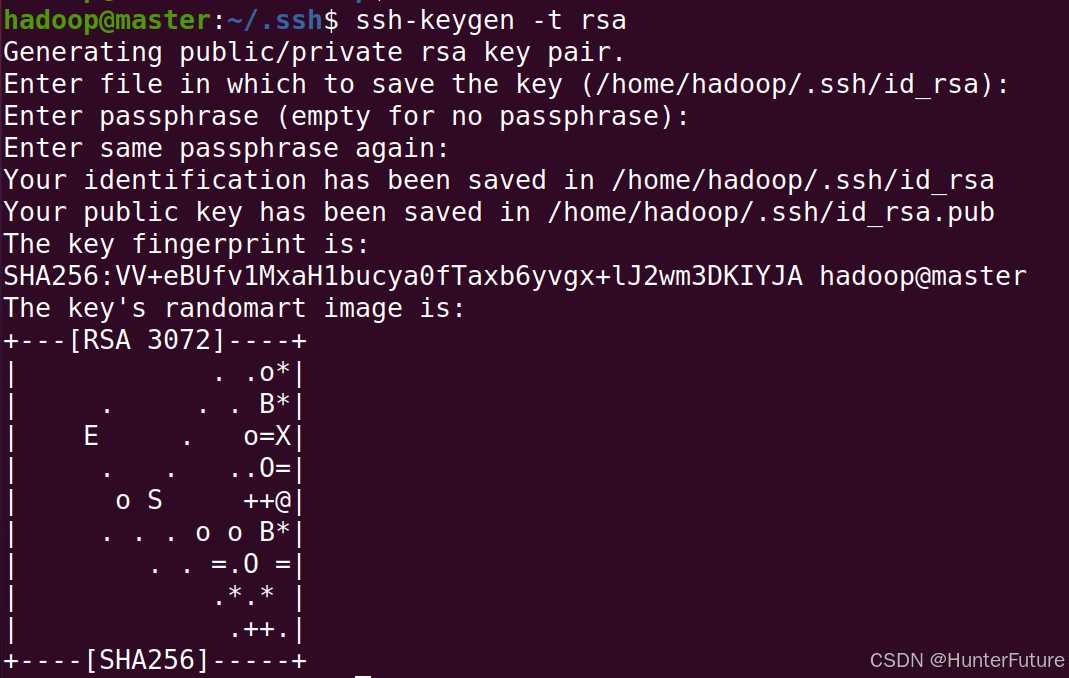
(5)在本机节点上设置免密登录并测试
```bash
cat ./id_rsa.pub >> ./authorized_keys
ssh localhost
```
会发现,再次执行ssh连接不再需要密码

(6)将公钥传到slave01、slave02(只在master机器上操作)
注:第二个命令中`hadoop@slave01`需要根据自己Ubuntu的用户名和机器名进行修改,如果你的用户名+机器名是`zhangsan@slave01`,那么命令中的`hadoop@slave01`就需要修改为`zhangsan@slave01`,同理`/home/hadoop`也一样改为`/home/zhangsan`,如果与示例相同则不需要更改
```bash
cd ~/.ssh
scp ~/.ssh/id_rsa.pub hadoop@slave01:/home/hadoop //将公钥给slave01
scp ~/.ssh/id_rsa.pub hadoop@slave02:/home/hadoop //将公钥给slave02
```
注:第二个和第三个命令之后需要输入密码,这个密码是登录slave01和slave02机器的密码
(7)在slave节点中将公钥保存(此步骤只在slave01和slave02上操作)
```bash
cat ~/id_rsa.pub>>~/.ssh/authorized_keys
rm ~/id_rsa.pub
```
(8)验证免密连接(只在master机器上执行)
```bash
ssh slave01
```
注:如果你的用户名和master机器的用户名不一样,那这里需要输入完整的用户名+机器名
例 : slave节点用户名和机器名是`zhangsan@slave01`,那你这里需要输入`ssh zhangsan@slave01`
这一次不需要密码就能连接上,并且会看到用户名和机器名由`hadoop@master`变成`hadoop@slave01`。
然后输入`exit`退出连接,再测试slave02
```bash
ssh slave02
```
成功连接后,输入`exit`退出连接
# 5.Hadoop安装配置
## 5.1master机器执行部分
(1)在自己电脑下载好Hadoop文件之后,粘贴到虚拟机的Downloads里,鼠标右键,点Paste即可粘贴。
注:打开左边第二个图标,打开之后点Downloads,再粘贴
(如果下载速度过慢,可以搜索“磁力下载软件”,找个顺眼的安装,这里不再推荐,将下载链接粘贴到磁力工具中再下载,速度会快点)

(2)解压
注:我下载的是Hadoop-3.3.6的版本,根据自己下载的版本修改`~/Downloads/hadoop-3.3.6.tar.gz`这一部分,
```bash
sudo tar -zxvf ~/Downloads/hadoop-3.3.6.tar.gz -C /usr/local
cd /usr/local
sudo mv ./hadoop-3.3.6 ./hadoop //如果你的不是3.3.6,根据实际修改
sudo chown -R hadoop ./hadoop
```
(3)配置环境变量
```bash
sudo vim ~/.bashrc
```
进入文件后,按上下方向键,翻到最后,插入下面语句
```bash
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lin/native
export PATH=${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
```
执行命令:`source ~/.bashrc`,然后关闭终端,再重新打开一个终端,输入`hadoop version`,如下图即配置成功
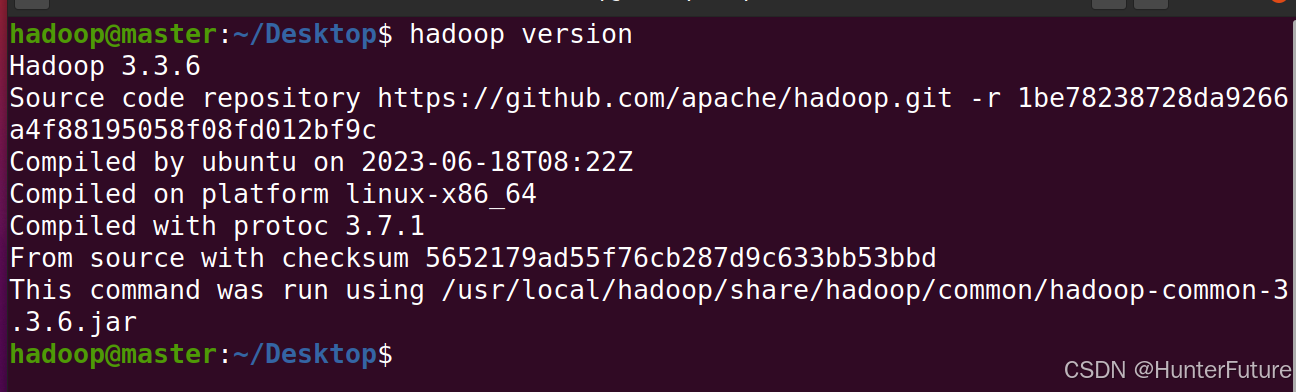
(4)文件配置
文件1
```bash
cd /usr/local/hadoop/etc/hadoop
vim core-site.xml
```
打开文件后,翻到最后一行,先将文件自带的``和` `删除,(`` 是XML文件的根元素,只能出现一次,必须唯一!)
再将下面内容粘贴到文件中
```bash
fs.defaultFS hdfs://master:9000 io.file.buffer.size 131072 hadoop.tmp.dir file:/usr/local/hadoop/tmp Abasefor other temporary directories. hadoop.proxyuser.spark.hosts * hadoop.proxyuser.spark.groups *
`和` `删除,再将内容粘贴到文件上
```bash
dfs.namenode.secondary.http-address master:9001 dfs.namenode.name.dir file:/usr/local/hadoop/dfs/name dfs.datanode.data.dir file:/usr/local/hadoop/dfs/data dfs.replication 2 dfs.webhdfs.enabled true
`和` `删除,再将下面代码粘贴到文件里
```bash
yarn.nodemanager.aux-services mapreduce_shuffle yarn.nodemanager.aux-services.mapreduce.shuffle.class org.apache.hadoop.mapred.ShuffleHandler yarn.resourcemanager.address master:8032 yarn.resourcemanager.scheduler.address master:8030 yarn.resourcemanager.resource-tracker.address master:8035 yarn.resourcemanager.admin.address master:8033 yarn.resourcemanager.webapp.address master:8088
`和` `删除,再将下面代码粘贴到文件里
```bash
mapreduce.framework.name yarn mapreduce.jobhistory.address master:10020 mapreduce.jobhistory.webapp.address master:19888
`和` `,直接将下面代码粘贴到文件最后,可以按方向键上面的PgDn/PageDown按键加快翻动
注:jdk版本根据自己下载的更改,此处与刚刚Java环境变量配置的路径一样。
```bash
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_441
```
文件6:
```bash
sudo vim workers
```

打开之后默认是localhost,删除,然后将下面内容粘贴到里面。
```bash
hadoop@slave01
hadoop@slave02
```
注:此处是两个slave节点的完整用户名和机器名,如果你的用户名或机器名与示例不同,需要修改。
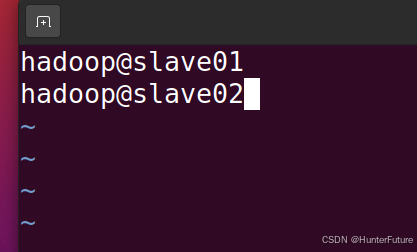
(5)压缩文件
```bash
cd /usr/local
sudo rm -rf ./hadoop/tmp
sudo rm -rf ./hadoop/logs
tar -zcvf ~/hadoop.master.tar.gz ./hadoop
```
(6)将压缩好的文件发送到slave机器上
```bash
scp ~/hadoop.master.tar.gz hadoop@slave01:/home/hadoop
scp ~/hadoop.master.tar.gz hadoop@slave02:/home/hadoop
```
注:此处`hadoop@slave01`是slave01虚拟机的完整用户名和机器名,如果与示例不同,根据自己的用户名和机器名修改,`/home/hadoop`的hadoop同理。
## 5.2 slave机器执行部分(slave01和slave02均需要执行一遍)
(1)在slave节点上解压hadoop.master.tar.gz文件,并给予授权
```bash
sudo rm -rf /usr/local/hadoop
sudo tar -zxvf ~/hadoop.master.tar.gz -C /usr/local
sudo chown -R hadoop /usr/local/hadoop
```
注:-R 后面的hadoop是slave节点的用户名,如果与示例不同,根据自己的情况修改。
`/usr/local/hadoop`这部分是固定的,不需要修改。
# 6. Hadoop启动与停止
(1)格式化NameNode(只在master上操作)
```bash
hdfs namenode -format
```
注:只执行一次就行,之后再使用Hadoop,不需要再格式化!!!
运行完结果类似下图

(2)启动HDFS(只在master节点上操作)
```bash
start-dfs.sh
```
然后在master,slave01,slave02上分别输入jps,结果如下图
>
>
> master节点
>
> 
>
>
>
> slave01节点
>
> 
>
>
>
> slave02节点
>
> 
>
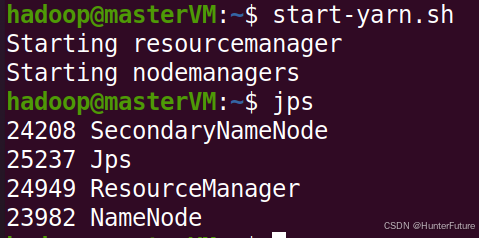
(3)启动YARN(只在master节点上操作)
```bash
start-yarn.sh
```
然后在master,slave01,slave02上分别输入jps,结果如下图
>
>
> master节点
>
> 
>
>
>
> slave01节点
>
> 
>
>
>
> salve02节点
>
> 
>
(4)网页访问(在master机器上操作)
在浏览器中打开`http://master:8088/cluster/nodes`,节点情况如下图

如果能正常打开网页,但没有节点,先stop停止进程,
执行`sudo vim /etc/hosts`,在第二行加个`#`和空格,如图,
之后再次运行进程就好了

(5)停止HDFS和YARN
```bash
stop-yarn.sh
stop-dfs.sh
```
也可以直接执行`stop-all.sh`全部关闭。
>
>
> 附录:
>
> 有小伙伴两小时急速完成,期待有新的记录产生
>
> 有小伙伴1小时17分钟急速完成,期待有新的记录产生
>
# 7.部分问题解决:
## 1.多次执行格式化操作`hdfs namenode -format`之后,导致DataNode进程或namenode看不到了。
解决:**这里给出一个适用于重启运行的方式:删除所有节点的/usr/local/hadoop/dfs中的内容,一般是name和data两个文件夹,因为这里记录了上次运行的集群ID等信息可能会导致冲突(当然这里只是部署阶段,如果运行了很久,重要的数据需要小心)。然后清一下logs数据,方便再运行查看错误问题。最后在master节点上执行hadoop namenode -format,就可以再启动Hadoop了。**
>
>
> 举个不恰当的例子,就好像第一次格式化之后,dfs的实际位置id刷新在麻辣烫,第二次格式化之后,dfs实际位置刷新到火锅,但是文件仍然保存着第一次麻辣烫的位置,实际位置与文件保存的位置不一样,命令运行的时候部分信息就乱跑了,导致datanode与namenode无法加载出来。
>
注:在执行之前,先`stop-all.sh`,将进程都停止了
(1)以下是直接操作的代码:(master和slave上都要执行)
```bash
cd /usr/local/hadoop
rm -rf /usr/local/hadoop/dfs
rm -rf /usr/local/hadoop/tmp
rm -rf /usr/local/hadoop/logs
```
(2)把第一步的代码,在master和slave机器上都执行之后,再进行下一步
(3)在master机器上执行下面代码
```bash
hdfs namenode -format //格式化
```
(4)启动HDFS(只在master节点上操作)
```bash
start-dfs.sh
```
(5)启动YARN(只在master节点上操作)
```bash
start-yarn.sh
```
(6)之后jps与查看网页步骤同上
## 2.IP自动更改
部分人的虚拟机,在再次打开后,会发现ip与上一次的ip不一样了,可以修改hosts(参考第二大步),或者参考网上设置静态IP。
本文来自投稿,不代表本站立场,如若转载,请注明出处:http//www.knowhub.vip/share/2/2288
- 热门的技术博文分享
- 1 . ESP实现Web服务器
- 2 . 从零到一:打造高效的金仓社区 API 集成到 MCP 服务方案
- 3 . 使用C#构建一个同时问多个LLM并总结的小工具
- 4 . .NET 原生驾驭 AI 新基建实战系列Milvus ── 大规模 AI 应用的向量数据库首选
- 5 . 在Avalonia/C#中使用依赖注入过程记录
- 6 . [设计模式/Java] 设计模式之工厂方法模式
- 7 . 5. RabbitMQ 消息队列中 Exchanges(交换机) 的详细说明
- 8 . SQL 中的各种连接 JOIN 的区别总结!
- 9 . JavaScript 中防抖和节流的多种实现方式及应用场景
- 10 . SaltStack 远程命令执行中文乱码问题
- 11 . 推荐10个 DeepSeek 神级提示词,建议搜藏起来使用
- 12 . C#基础:枚举、数组、类型、函数等解析
- 13 . VMware平台的Ubuntu部署完全分布式Hadoop环境
- 14 . C# 多项目打包时如何将项目引用转为包依赖
- 15 . Chrome 135 版本开发者工具(DevTools)更新内容
- 16 . 从零创建npm依赖,只需执行一条命令
- 17 . 关于 Newtonsoft.Json 和 System.Text.Json 混用导致的的序列化不识别的问题
- 18 . 大模型微调实战之训练数据集准备的艺术与科学
- 19 . Windows快速安装MongoDB之Mongo实战
- 20 . 探索 C# 14 新功能:实用特性为编程带来便利