Python 实现小说网站数据爬取
笔记哥 /
04-30 /
6点赞 /
0评论 /
258阅读
# 项目场景:
利用python爬取某小说网站,主要爬取小说名字,作者,类别,将其保存为三元组形式:(xxx, xxx, xxx)并将其保存至excel表格中。本文从爬取目的到爬取的各步骤都尽量详细的去复现。
(学习爬虫1个月,python两个月,记录自己的学习过程。只要爬成功一次后,之后就会更得心应手。)
本文中不恰当之处还望指正。
* * *
# 复现过程
**1.审查相关数据元素标签:**
比如我要爬取的内容都在下图红框标签中:
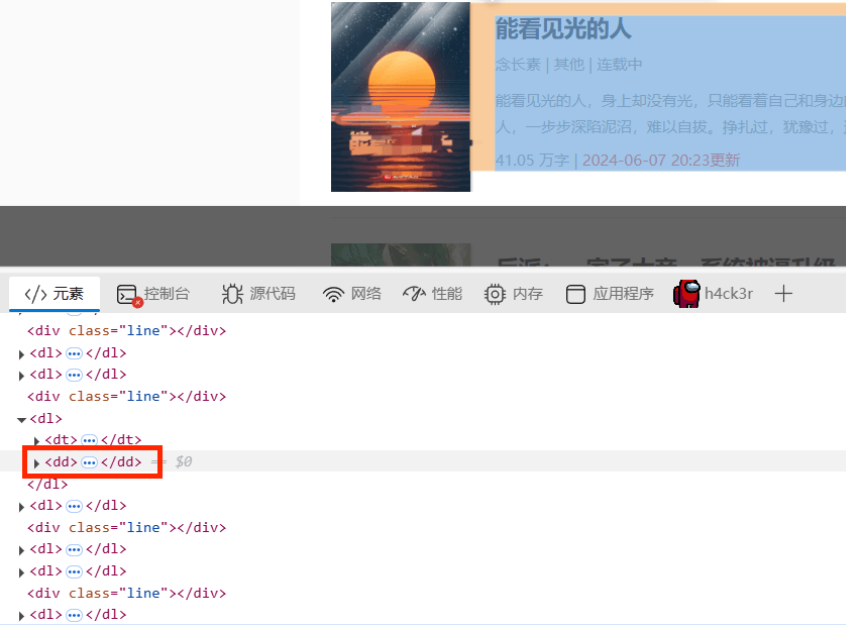
更细分一点呢,我要爬取的是标题,作者和类别,我们发现这三组数据在该页面中都可以找到,就在这个页面中进行爬取吧。接下来寻找数据对应的元素标签。
(打开开发者工具,F12,或在设置里打开也可。找到找个小图标:
点击你想要爬取的内容就可以找到其对应的标签了。)
下面我们来查看一下我们想要爬取的数据的标签吧。
小说名称对应的元素:

作者对应的元素标签:

类别对应的元素标签:

**2.下面开始编写代码:**
**a.导入库:**
```python3
import requests
from bs4 import BeautifulSoup
import pandas as pd
```
**b.这里我就编写一个爬虫类NovelSpider了:**
```python3
class NovelSpider:
"""
全书网小说爬虫爬取小说名称
"""
def __init__(self, url: str = None, page: int = 2):
self.url = url
self.headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60'
}
self.page = page
```
这是编写类最基本的内容了,用\_\_init\_\_定义一个类的基本属性。
**c.下面我们开始在类中编写一个具体的实现代码了:**
```python3
def get_novel(self, url: str):
"""获取文章信息的方法"""
try:
response = requests.get(url, headers=self.headers)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'lxml')
novel_list = []
dl_tag = soup.find_all('dl')
for dl in dl_tag:
# 获取小说名称
a_title_tag = dl.find('a', class_="bigpic-book-name")
title = a_title_tag.text if a_title_tag.text else ""
# 获取小说作者
a_author_tag = dl.find('a', href=lambda href: href and '/search/' in href)
author = a_author_tag.text if a_author_tag.text else ""
# 获取小说的类别
a_type_tag = dl.find('a', href=lambda href: href and '/lists/' in href)
type_ = a_type_tag.text if a_type_tag.text else ""
if title and author and type_:
novel_list.append([title, author, type_])
return novel_list
except Exception as e:
print(f'出现{e}错误!!!')
```
>
>
> 在编写python代码中使用try-except模块几乎是约定俗成的规定:
>
>
> 因为爬虫面临的不确定性很多:比如:网络问题(连接超时、DNS解析失败、SSL错误等),
>
> 目标网站变更(HTML结构调整、标签属性变化),反爬机制(IP封禁、验证码、请求频率限制),数据异常(缺失字段、格式不符预期)。
>
>
> *"宁可失败也要明确原因,不要沉默地继续运行错误状态"*
>
**try-except块:**
```python
try:xxx
except requests.RequestException as e:print(f'请求出现 {e} 错误!!!')
except Exception as e:print(f'出现{e}错误!!!')
```
**在编写好最基本的爬虫语句后,着重处理我们想要爬取的特定标签:**
我们知道,关于小说的内容都在以下元素中:
```html
-

- 能看见光的人
能看见光的人,身上却没有光,只能看着自己和身边的人,一步步深陷泥沼,难以自拔。挣扎过,犹豫过,逃避过,反抗过,最终抛弃信念,沉默地沉沦在现实的漩涡里。那些有光的人,终究才是世界的中心。也许,怪他不够努力,不够聪明,不够坚定吧...
41.05 万字 | 2024-06-07 20:23更新
本文来自投稿,不代表本站立场,如若转载,请注明出处:http//www.knowhub.vip/share/2/3033
- 热门的技术博文分享
- 1 . ESP实现Web服务器
- 2 . 从零到一:打造高效的金仓社区 API 集成到 MCP 服务方案
- 3 . 使用C#构建一个同时问多个LLM并总结的小工具
- 4 . .NET 原生驾驭 AI 新基建实战系列Milvus ── 大规模 AI 应用的向量数据库首选
- 5 . 在Avalonia/C#中使用依赖注入过程记录
- 6 . [设计模式/Java] 设计模式之工厂方法模式
- 7 . 5. RabbitMQ 消息队列中 Exchanges(交换机) 的详细说明
- 8 . SQL 中的各种连接 JOIN 的区别总结!
- 9 . JavaScript 中防抖和节流的多种实现方式及应用场景
- 10 . SaltStack 远程命令执行中文乱码问题
- 11 . 推荐10个 DeepSeek 神级提示词,建议搜藏起来使用
- 12 . C#基础:枚举、数组、类型、函数等解析
- 13 . VMware平台的Ubuntu部署完全分布式Hadoop环境
- 14 . C# 多项目打包时如何将项目引用转为包依赖
- 15 . Chrome 135 版本开发者工具(DevTools)更新内容
- 16 . 从零创建npm依赖,只需执行一条命令
- 17 . 关于 Newtonsoft.Json 和 System.Text.Json 混用导致的的序列化不识别的问题
- 18 . 大模型微调实战之训练数据集准备的艺术与科学
- 19 . Windows快速安装MongoDB之Mongo实战
- 20 . 探索 C# 14 新功能:实用特性为编程带来便利
- 相关联分享
- Browser-use:基于 Python 的智能浏览器自动化 AI 工具调研与实战
- Python多线程编程:线程池使用与性能评估
- 神库Docx预览推荐
- Python在PDF中添加与删除超链接的操作实现
- Python 实现小说网站数据爬取
- Python requests代理(Proxy)使用教程
- 邮件自动回复助手:Rasa与SMTP实现教程
- 在windows11 安装CUDA Toolkit,Python,Anaconda,PyTorch并使用DeepSeek 多模态模型 Janus-Pro识别和生成图片
- trae开发的win10端口占用检测工具
- Python 网络请求:urllib 与 requests 模块深度解析与爬虫实战
- Python基础训练题分享
- Browser-use 详细介绍&使用文档
- Python日志模块Logging的全面使用指南
- N+1查询:数据库性能的隐形杀手与终极拯救指南