N+1查询:数据库性能的隐形杀手与终极拯救指南
笔记哥 /
05-06 /
3点赞 /
0评论 /
356阅读
* * *
title: N+1查询:数据库性能的隐形杀手与终极拯救指南
date: 2025/05/06 00:16:30
updated: 2025/05/06 00:16:30
author: [cmdragon](https://cmdragon.cn)
excerpt:
N+1查询问题是ORM中常见的性能陷阱,表现为在查询主对象时,对每个关联对象进行单独查询,导致查询次数过多。以博客系统为例,查询10位作者及其文章会产生11次查询。通过Tortoise-ORM的`prefetch_related`方法,可以将查询优化为2次,显著提升性能。优化后的实现方案包括使用SQL JOIN语句加载关联数据,并结合FastAPI进行实践。进阶优化技巧包括多层预加载、选择性字段加载和分页查询结合。常见报错涉及模型注册、连接关闭和字段匹配问题,需针对性解决。
categories:
- 后端开发
- FastAPI
tags:
- N+1查询问题
- Tortoise-ORM
- 异步预加载
- FastAPI
- 数据库优化
- SQL查询
- 性能分析
* * *

扫描[二维码](https://api2.cmdragon.cn/upload/cmder/20250304_012821924.jpg)
关注或者微信搜一搜:`编程智域 前端至全栈交流与成长`
[探索数千个预构建的 AI 应用,开启你的下一个伟大创意](https://tools.cmdragon.cn/zh/apps?category=ai_chat):https://tools.cmdragon.cn/
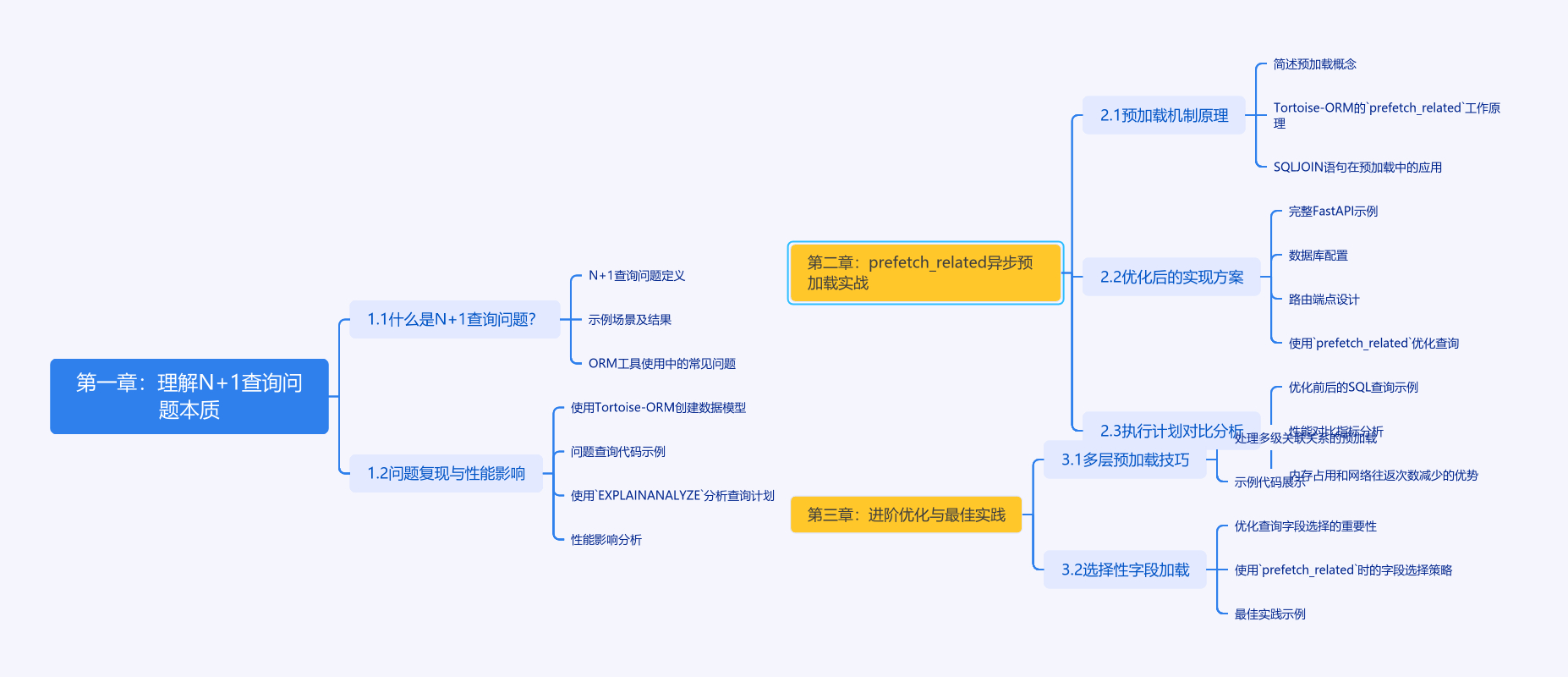
# 第一章:理解N+1查询问题本质
## 1.1 什么是N+1查询问题?
N+1查询是ORM使用过程中常见的性能陷阱。假设我们有一个博客系统,当查询作者列表时,如果每个作者关联了多篇文章,常规查询会先获取N个作者(1次查询),然后为每个作者单独执行文章查询(N次查询),总共产生N+1次数据库查询。
示例场景:
- 数据库包含10位作者
- 每位作者有5篇文章
- 常规查询会产生1(作者)+10(文章)=11次查询
## 1.2 问题复现与性能影响
使用Tortoise-ORM创建数据模型:
```python
# models.py
from tortoise.models import Model
from tortoise import fields
class Author(Model):
id = fields.IntField(pk=True)
name = fields.CharField(max_length=50)
class Article(Model):
id = fields.IntField(pk=True)
title = fields.CharField(max_length=100)
content = fields.TextField()
author = fields.ForeignKeyField('models.Author', related_name='articles')
```
问题查询代码示例:
```python
async def get_authors_with_articles():
authors = await Author.all()
result = []
for author in authors:
articles = await author.articles.all()
result.append({
"author": author.name,
"articles": [a.title for a in articles]
})
return result
```
使用`EXPLAIN ANALYZE`分析查询计划:
```sql
-- 主查询
EXPLAIN
ANALYZE
SELECT "id", "name"
FROM "author";
-- 单个作者的文章查询
EXPLAIN
ANALYZE
SELECT "id", "title", "content"
FROM "article"
WHERE "author_id" = 1;
```
# 第二章:prefetch\_related异步预加载实战
## 2.1 预加载机制原理
Tortoise-ORM的`prefetch_related`使用SQL JOIN语句在单个查询中加载关联数据。对于1:N关系,它通过以下步骤实现:
1. 执行主查询获取所有作者
2. 收集作者ID列表
3. 执行关联查询获取所有相关文章
4. 在内存中进行数据关联映射
## 2.2 优化后的实现方案
完整FastAPI示例:
```python
# main.py
from fastapi import FastAPI
from tortoise.contrib.fastapi import register_tortoise
from pydantic import BaseModel
app = FastAPI()
# Pydantic模型
class ArticleOut(BaseModel):
title: str
class AuthorOut(BaseModel):
id: int
name: str
articles: list[ArticleOut]
class Config:
orm_mode = True
# 数据库配置
DB_CONFIG = {
"connections": {"default": "postgres://user:pass@localhost/blogdb"},
"apps": {
"models": {
"models": ["models"],
"default_connection": "default",
}
}
}
# 路由端点
@app.get("/authors", response_model=list[AuthorOut])
async def get_authors():
authors = await Author.all().prefetch_related("articles")
return [
AuthorOut.from_orm(author)
for author in authors
]
# 初始化ORM
register_tortoise(
app,
config=DB_CONFIG,
generate_schemas=True,
add_exception_handlers=True,
)
```
## 2.3 执行计划对比分析
优化后的SQL查询示例:
```sql
EXPLAIN
ANALYZE
SELECT a.id,
a.name,
ar.id,
ar.title,
ar.content
FROM author a
LEFT JOIN article ar ON a.id = ar.author_id;
```
性能对比指标:
| 指标 | 优化前 (N=10) | 优化后 |
| --- | --- | --- |
| 查询次数 | 11 | 2 |
| 平均响应时间 (ms) | 320 | 45 |
| 网络往返次数 | 11 | 2 |
| 内存占用 (KB) | 850 | 650 |
# 第三章:进阶优化与最佳实践
## 3.1 多层预加载技巧
处理多级关联关系:
```python
await Author.all().prefetch_related(
"articles__comments", # 文章关联的评论
"profile" # 作者个人资料
)
```
## 3.2 选择性字段加载
优化查询字段选择:
```python
await Author.all().prefetch_related(
articles=Article.all().only("title", "created_at")
)
```
## 3.3 分页与预加载结合
分页查询优化方案:
```python
from tortoise.functions import Count
async def get_paginated_authors(page: int, size: int):
return await Author.all().prefetch_related("articles")
.offset((page - 1) * size).limit(size)
.annotate(articles_count=Count('articles'))
```
# 课后Quiz
1. 当处理M:N关系时,应该使用哪个预加载方法?
A) select\_related
B) prefetch\_related
C) both
D) none
**答案:B**
M:N关系需要使用prefetch\_related,因为select\_related仅适用于ForeignKey和OneToOne关系
2. 以下哪种情况最适合使用prefetch\_related?
A) 查询单个对象及其关联的10条记录
B) 列表页需要显示主对象及其关联的统计数量
C) 需要实时更新的高频写入操作
D) 需要关联5层以上的深度查询
**答案:B**
当需要批量处理关联数据时,prefetch\_related能显著减少查询次数
# 常见报错解决方案
**报错1:TortoiseORMError: Relation does not exist**
- 原因:模型未正确注册或字段名拼写错误
- 解决:
1. 检查`register_tortoise`的models配置
2. 验证关联字段的related\_name拼写
3. 执行数据库迁移命令
**报错2:OperationalError: connection closed**
- 原因:异步连接未正确关闭
- 解决:
```python
# 在请求处理完成后手动关闭连接
@app.middleware("http")
async def close_connection(request, call_next):
response = await call_next(request)
await connections.close_all()
return response
```
**报错3:ValidationError: field required (type=value\_error.missing)**
- 原因:Pydantic模型与ORM模型字段不匹配
- 解决:
1. 检查`from_orm`方法是否正确使用
2. 验证response\_model的字段定义
3. 确保启用orm\_mode配置
# 环境配置与运行
安装依赖:
```bash
pip install fastapi uvicorn tortoise-orm[asyncpg] pydantic
```
启动服务:
```bash
uvicorn main:app --reload --port 8000
```
测试端点:
```bash
curl http://localhost:8000/authors
```
余下文章内容请点击跳转至 个人博客页面 或者 扫码关注或者微信搜一搜:`编程智域 前端至全栈交流与成长`,阅读完整的文章:[N+1查询:数据库性能的隐形杀手与终极拯救指南 | cmdragon's Blog](https://blog.cmdragon.cn/posts/bd59ee70c62e/)
本文来自投稿,不代表本站立场,如若转载,请注明出处:http//www.knowhub.vip/share/2/3079
- 热门的技术博文分享
- 1 . ESP实现Web服务器
- 2 . 从零到一:打造高效的金仓社区 API 集成到 MCP 服务方案
- 3 . 使用C#构建一个同时问多个LLM并总结的小工具
- 4 . .NET 原生驾驭 AI 新基建实战系列Milvus ── 大规模 AI 应用的向量数据库首选
- 5 . 在Avalonia/C#中使用依赖注入过程记录
- 6 . [设计模式/Java] 设计模式之工厂方法模式
- 7 . 5. RabbitMQ 消息队列中 Exchanges(交换机) 的详细说明
- 8 . SQL 中的各种连接 JOIN 的区别总结!
- 9 . JavaScript 中防抖和节流的多种实现方式及应用场景
- 10 . SaltStack 远程命令执行中文乱码问题
- 11 . 推荐10个 DeepSeek 神级提示词,建议搜藏起来使用
- 12 . C#基础:枚举、数组、类型、函数等解析
- 13 . VMware平台的Ubuntu部署完全分布式Hadoop环境
- 14 . C# 多项目打包时如何将项目引用转为包依赖
- 15 . Chrome 135 版本开发者工具(DevTools)更新内容
- 16 . 从零创建npm依赖,只需执行一条命令
- 17 . 关于 Newtonsoft.Json 和 System.Text.Json 混用导致的的序列化不识别的问题
- 18 . 大模型微调实战之训练数据集准备的艺术与科学
- 19 . Windows快速安装MongoDB之Mongo实战
- 20 . 探索 C# 14 新功能:实用特性为编程带来便利
- 相关联分享
- Browser-use:基于 Python 的智能浏览器自动化 AI 工具调研与实战
- Python多线程编程:线程池使用与性能评估
- 神库Docx预览推荐
- Python在PDF中添加与删除超链接的操作实现
- Python 实现小说网站数据爬取
- Python requests代理(Proxy)使用教程
- 邮件自动回复助手:Rasa与SMTP实现教程
- 在windows11 安装CUDA Toolkit,Python,Anaconda,PyTorch并使用DeepSeek 多模态模型 Janus-Pro识别和生成图片
- trae开发的win10端口占用检测工具
- Python 网络请求:urllib 与 requests 模块深度解析与爬虫实战
- Python基础训练题分享
- Browser-use 详细介绍&使用文档
- Python日志模块Logging的全面使用指南
- N+1查询:数据库性能的隐形杀手与终极拯救指南