大模型中的Token:概念、分词器作用及详解
笔记哥 /
04-01 /
13点赞 /
0评论 /
707阅读
“**大模型**中的 **Token** 究竟是什么?”
这确实是一个很有代表性的问题。许多人听说过 Token 这个概念,但未必真正理解它的作用和意义。思考之后,我决定写篇文章,详细解释这个话题。

我说:像 **DeepSeek** 和 **ChatGPT** 这样的超大语言模型,都有一个“刀法精湛”的小弟——**分词器(**Tokenizer**)**。

当**大模型**接**收到一段文字**。
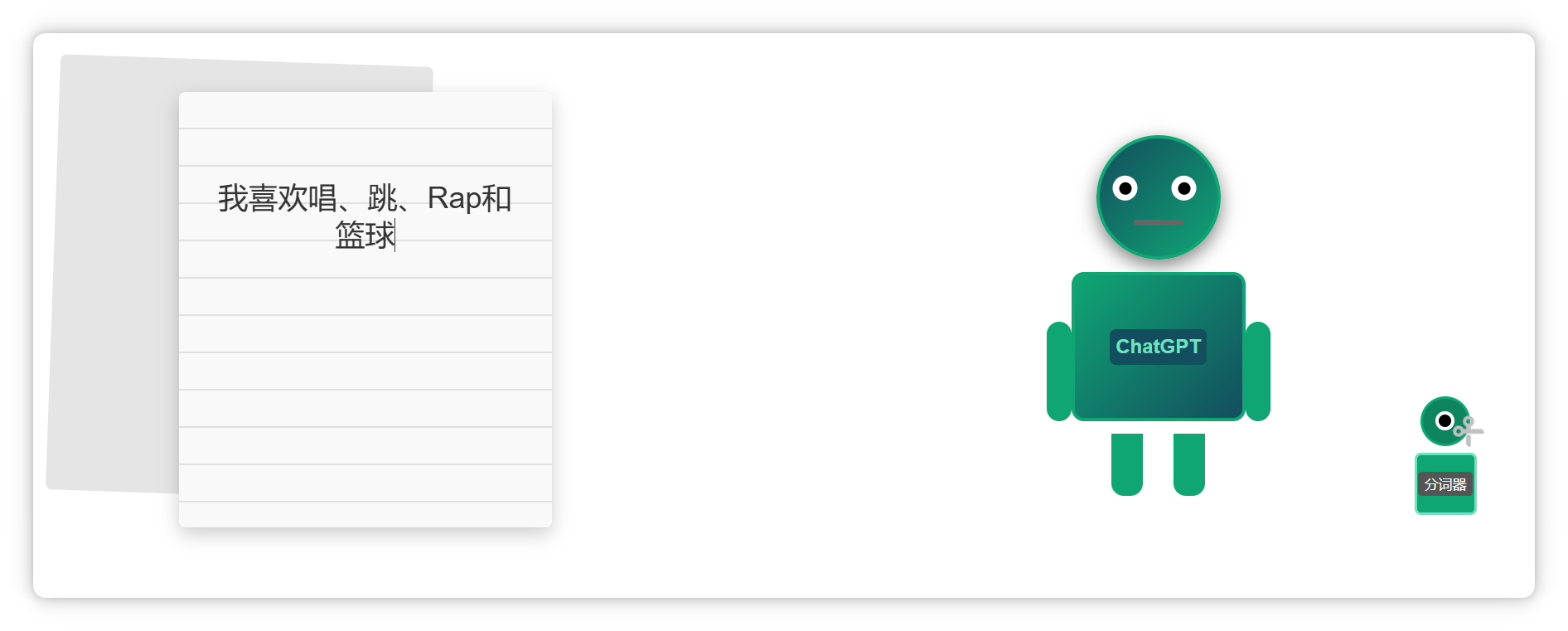
会让**分词器**把它**切成很多个小块**。
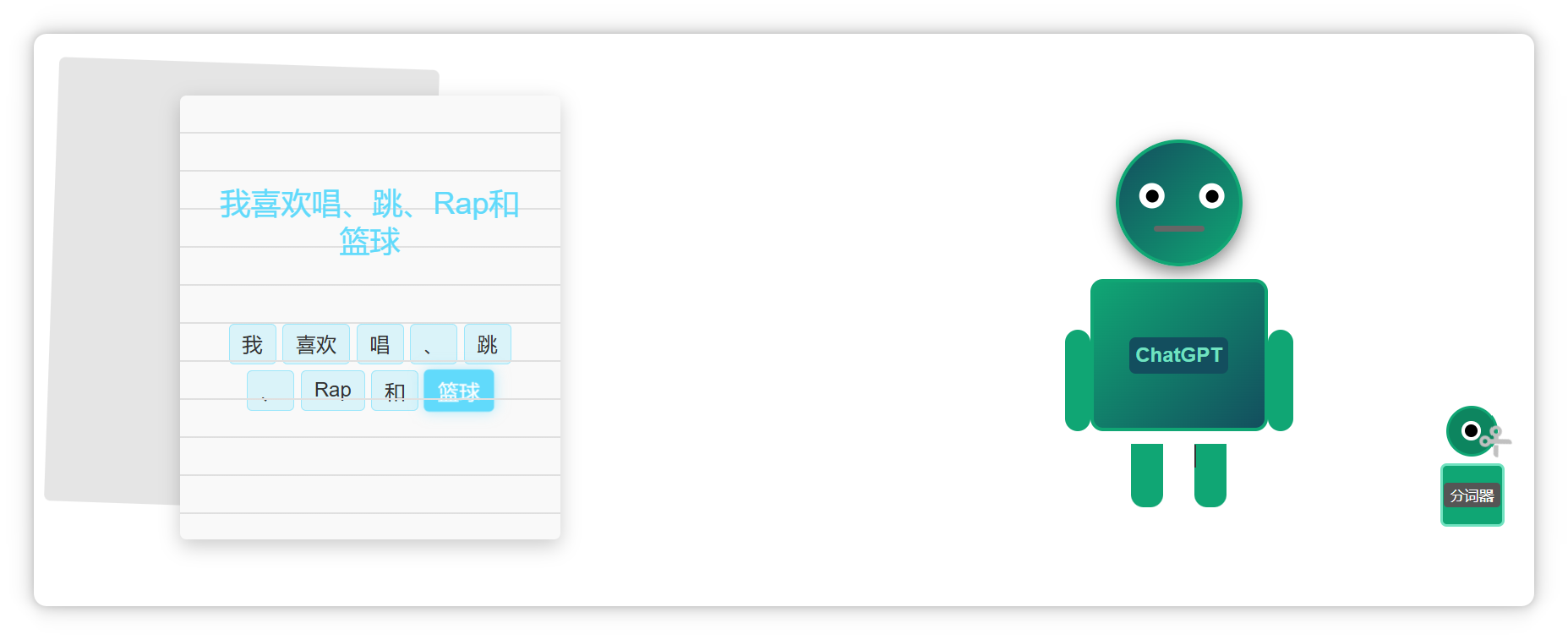
这切出来的每一个小块就叫做一个 **Token**。

比如这段话(**我喜欢唱、跳、Rap和篮球**),在大模型里可能会被切成这个样子。

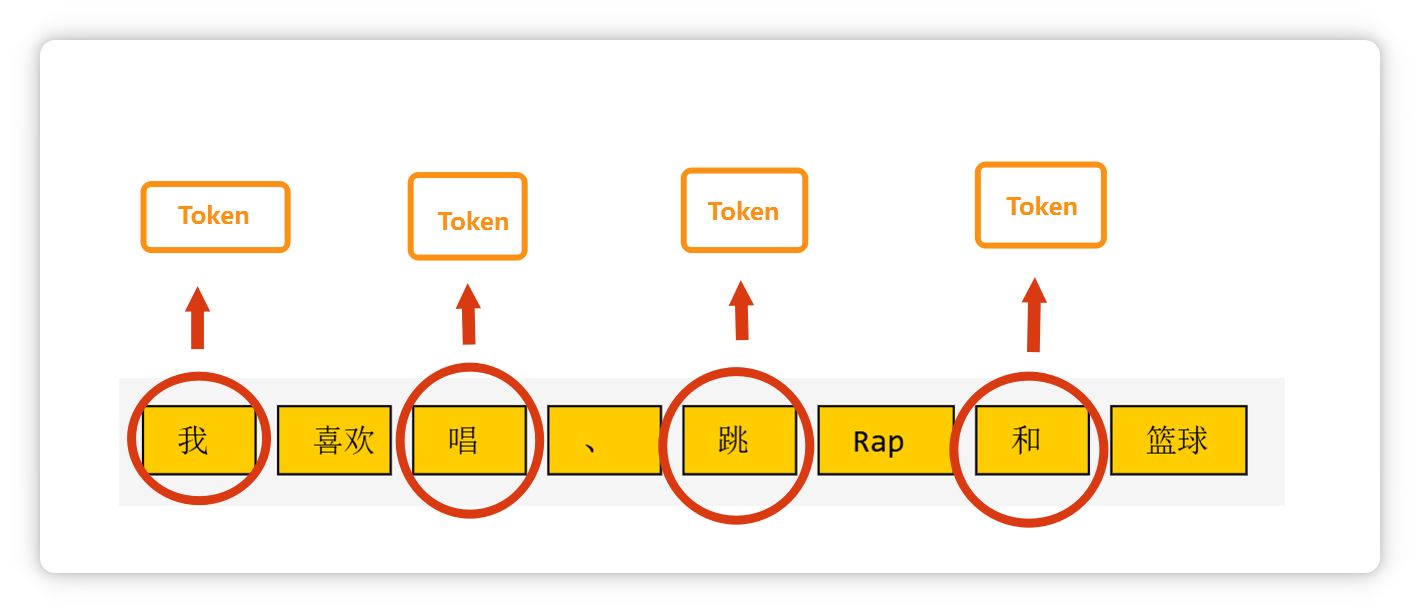
像**单个汉字**,可能是一个 **Token**。
**两个汉字**构成的**词语**,也可能是一个 **Token**。
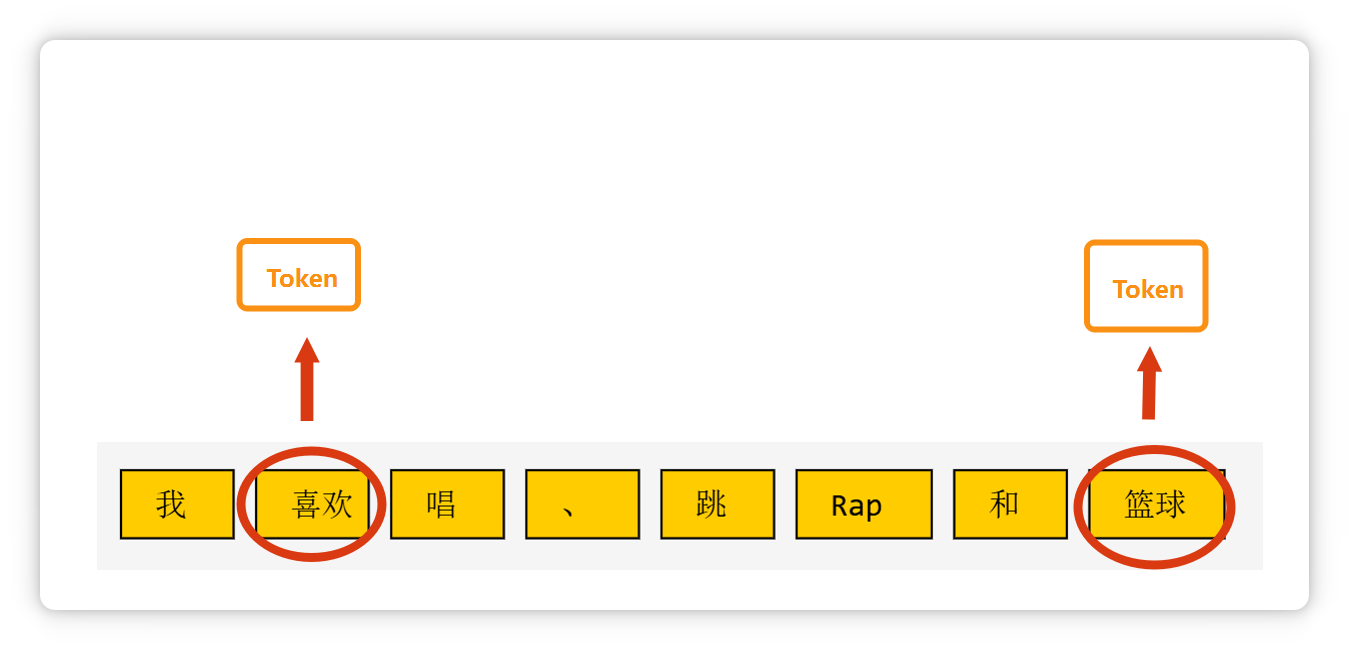
**三个字**构成的**常见短语**,也可能是一个 **Token**。
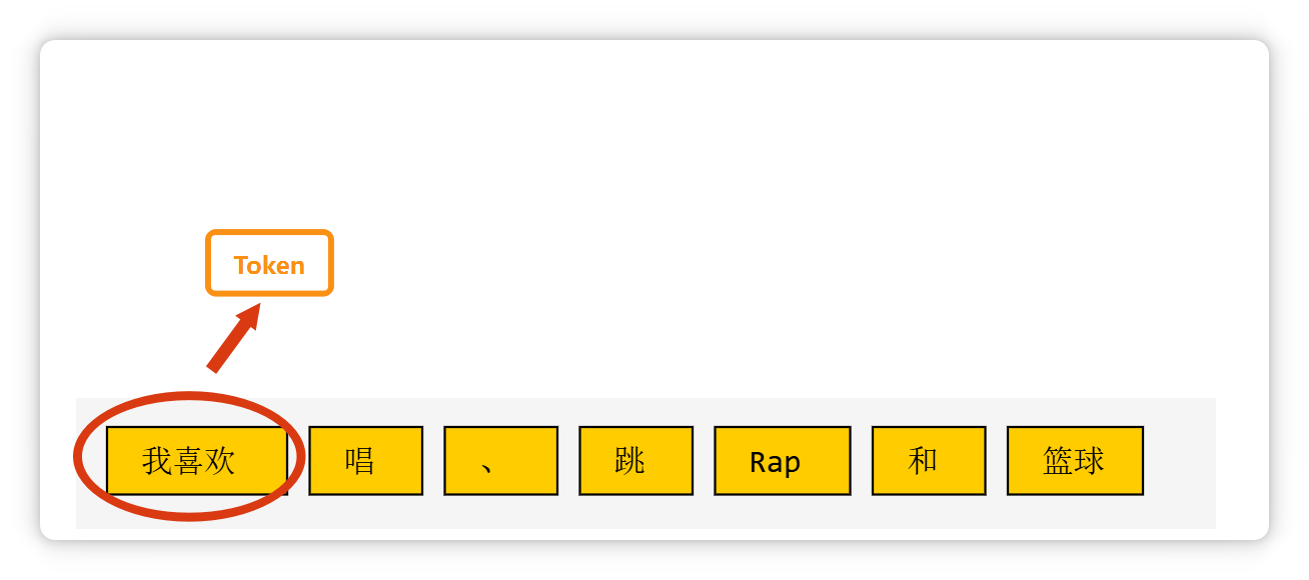
**一个标点符号**,也可能是一个 **Token**。
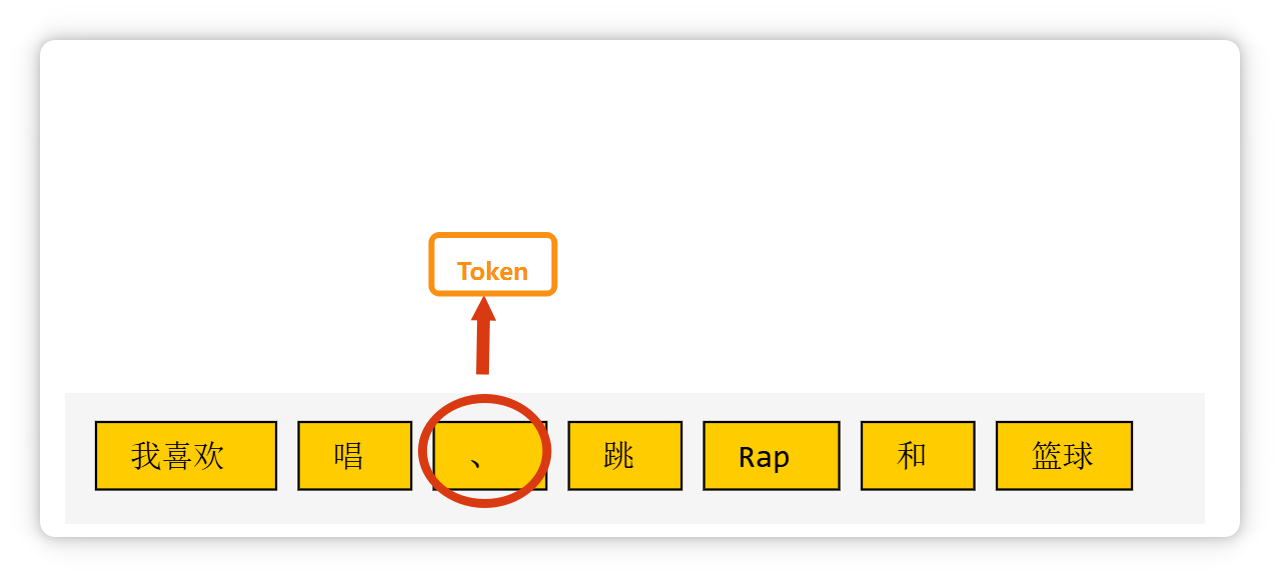
**一个单词**,或者是**几个字母**组成的一个**词缀**,也可能是一个 **Token**。
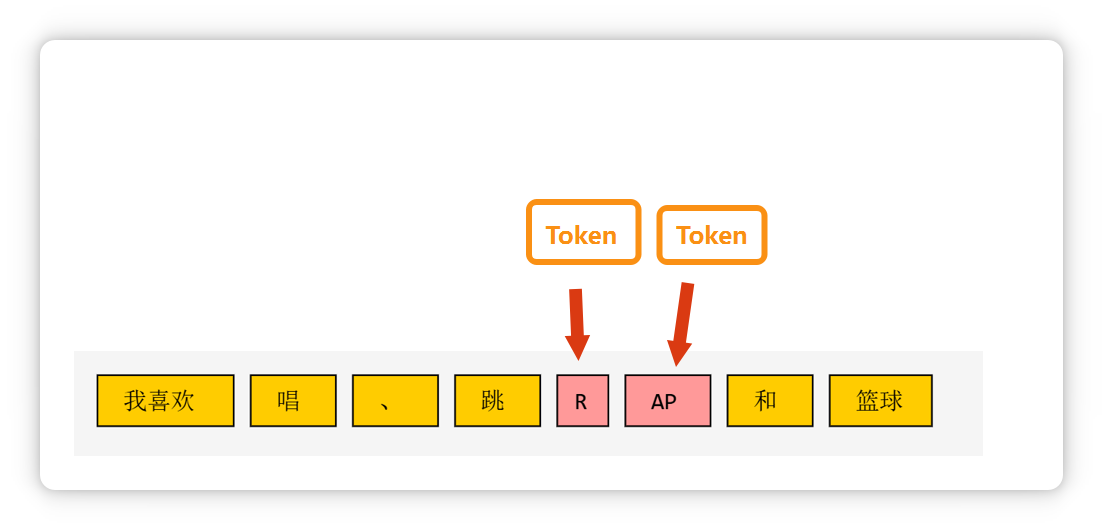
大模型在输出文字的时候,也是一个 Token 一个 Token 的往外蹦,所以看起来可能有点像在打字一样。

朋友听完以后,好像更疑惑了:

于是,我决定换一个方式,给他通俗解释一下。
大模型的Token究竟是啥,以及为什么会是这样。
首先,请大家快速读一下这几个字:

是不是有点没有认出来,或者是需要愣两秒才可以认出来?
但是如果这些字出现在**词语**或者**成语**里,你**瞬间**就可以念出来。

那之所以会这样,是因为我们的**大脑在日常生活中**,**喜欢**把这些有含义的**词语**或者**短语**,优先作为**一个整体**来对待。

不到万不得已,不会去一个字一个字的抠。

这就导致我们对这些**词语还挺熟悉**,**单看**这些字(旯妁圳侈邯)的时候,反而会觉得**有点陌生**。
而大脑🧠之所以要这么做,是因为这样可以节省脑力,咱们的大脑还是非常懂得偷懒的。

比如 “**今天天气不错**” 这句话,如果一个字一个字的去处理,一共需要有**6个部分**。

但是如果划分成**3个**、**常见**且**有意义的词**。

就只需要处理**3个**部分**之间的关系**,从而**提高效率**,**节省脑力**。
既然人脑可以这么做,那人工智能也可以这么做。

所以就有了**分词器**,专门**帮大模型**把大段的文字,**拆解成大小合适**的一个个 **Token**。

不同的分词器,它的分词方法和结果不一样。
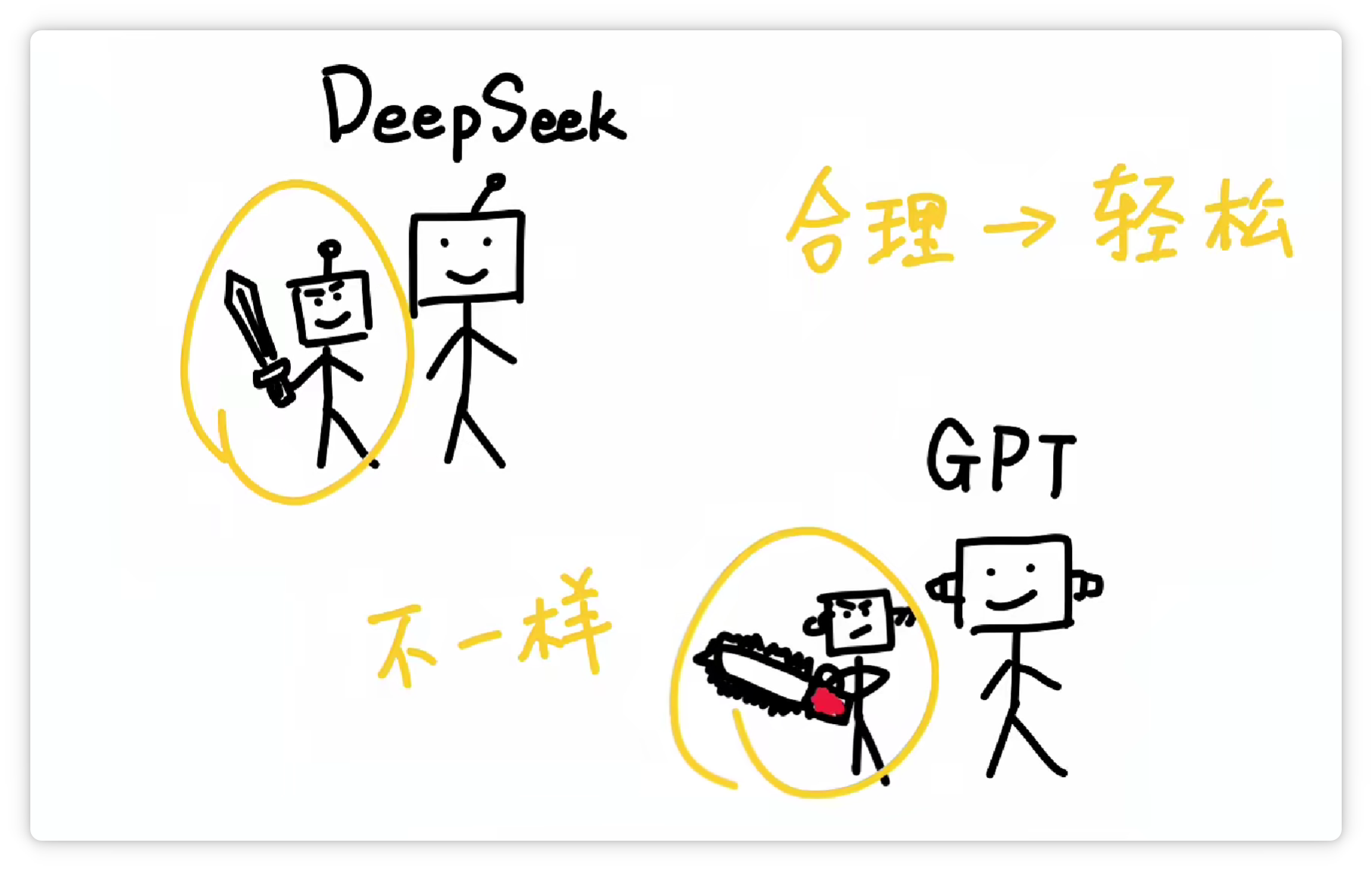
分得越合理,大模型就越轻松。这就好比餐厅里负责切菜的切配工,它的刀功越好,主厨做起菜来当然就越省事。

分词器究竟是怎么分的词呢?
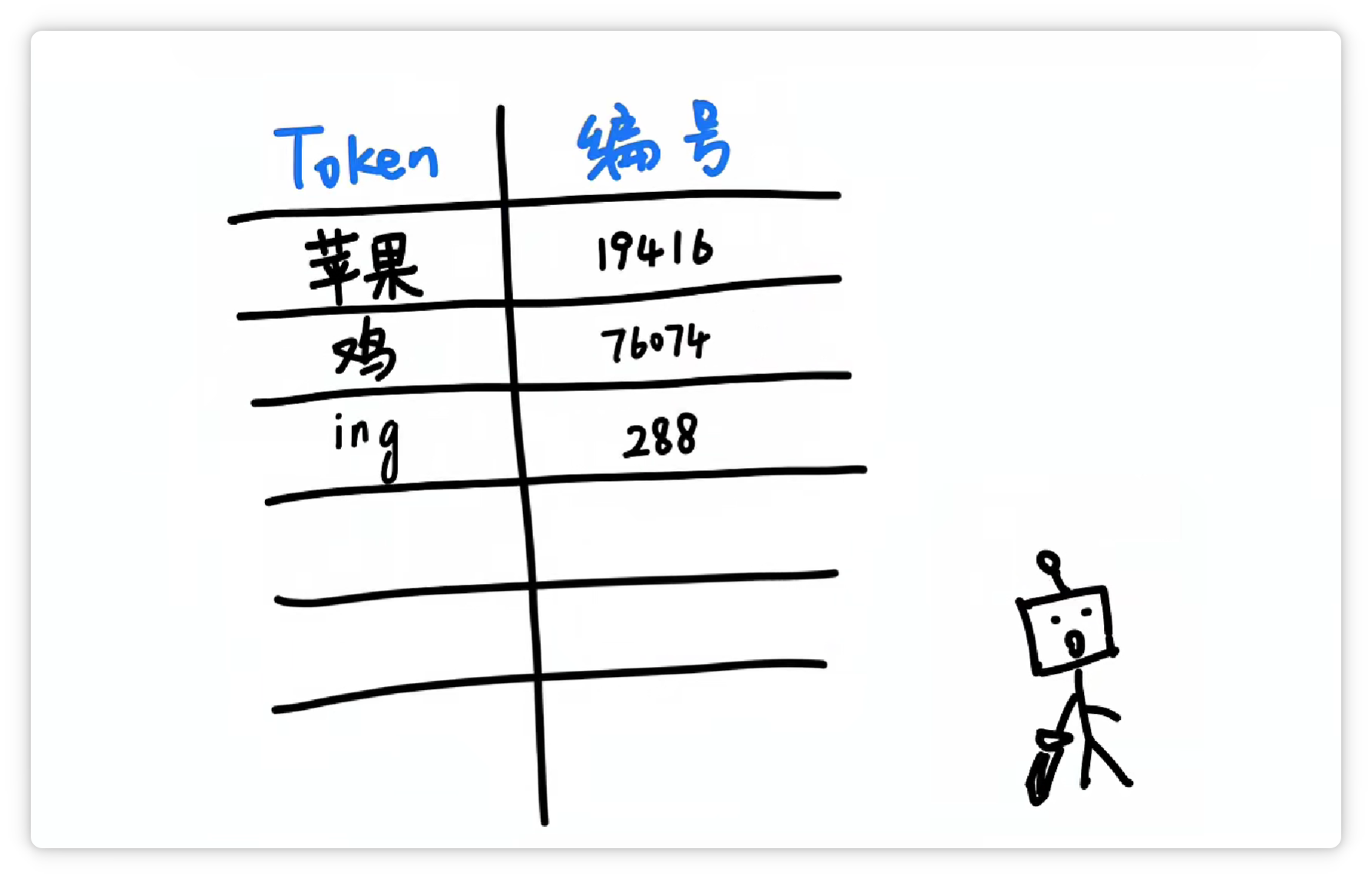
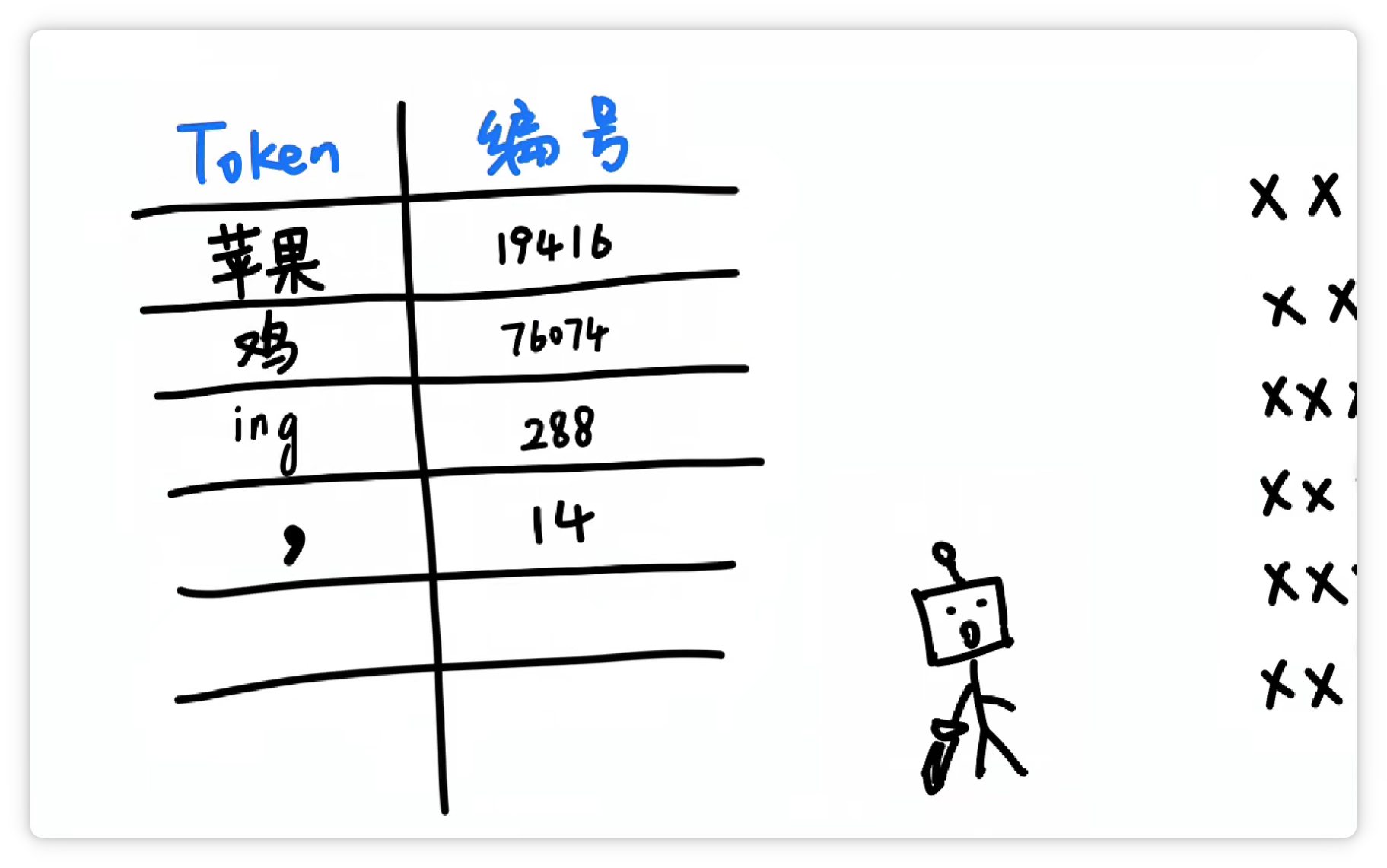
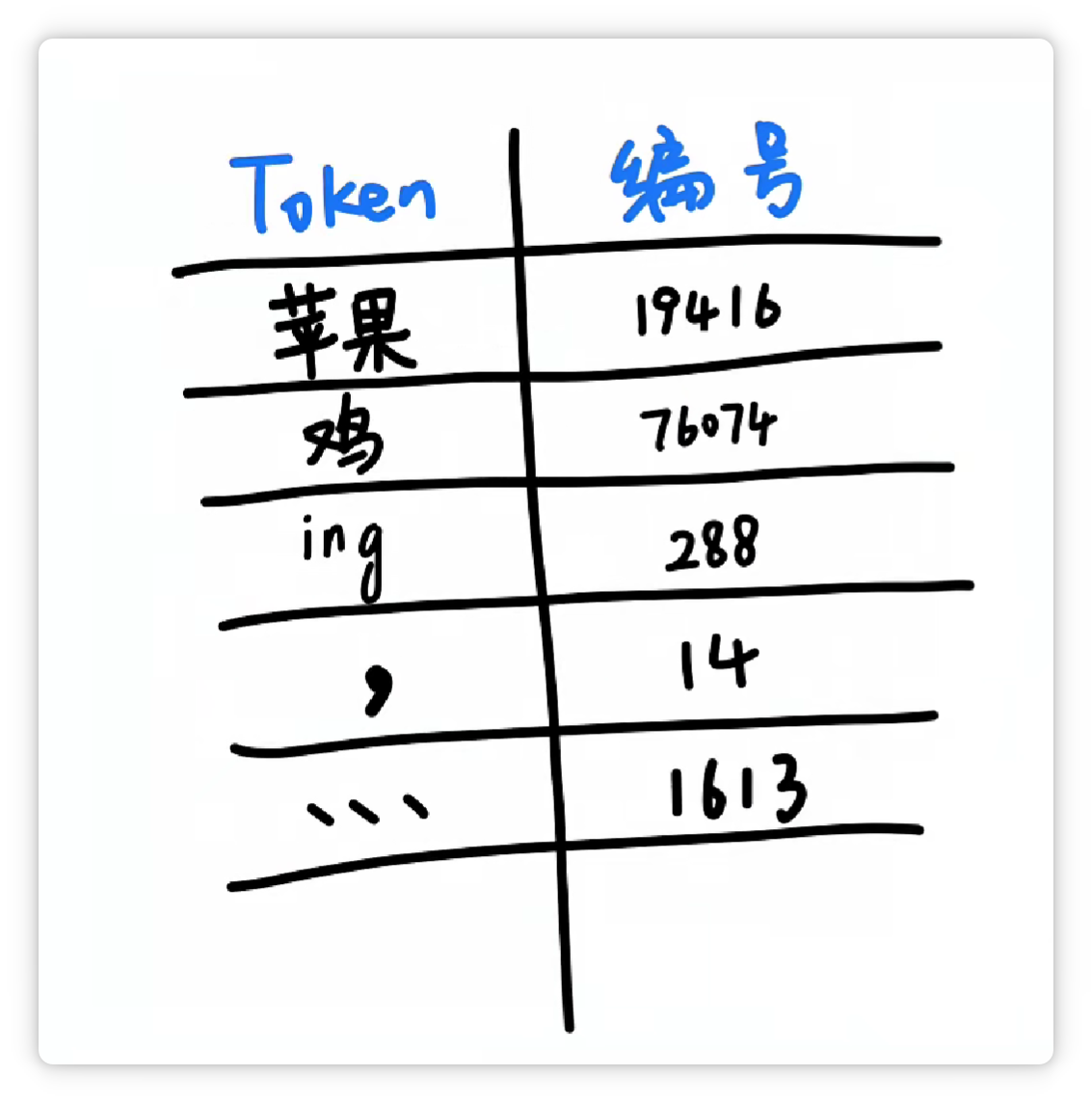
其中一种方法大概是这样,分词器统计了大量文字以后,发现 **“苹果”** 这两个字,**经常一起出现**。
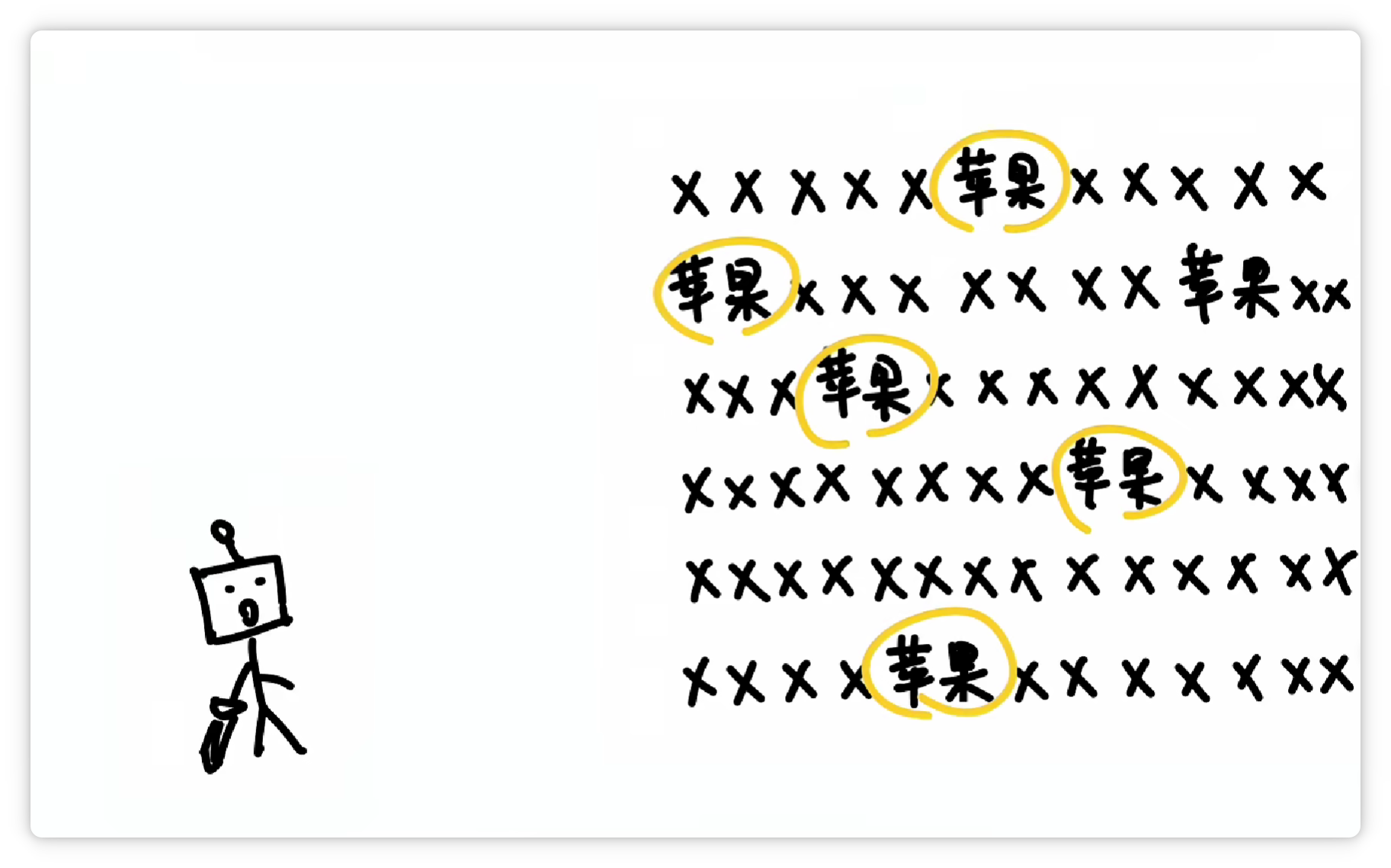
就把它们打包成一个 **Token**,给它一个**数字编号**,比如 **19416**。
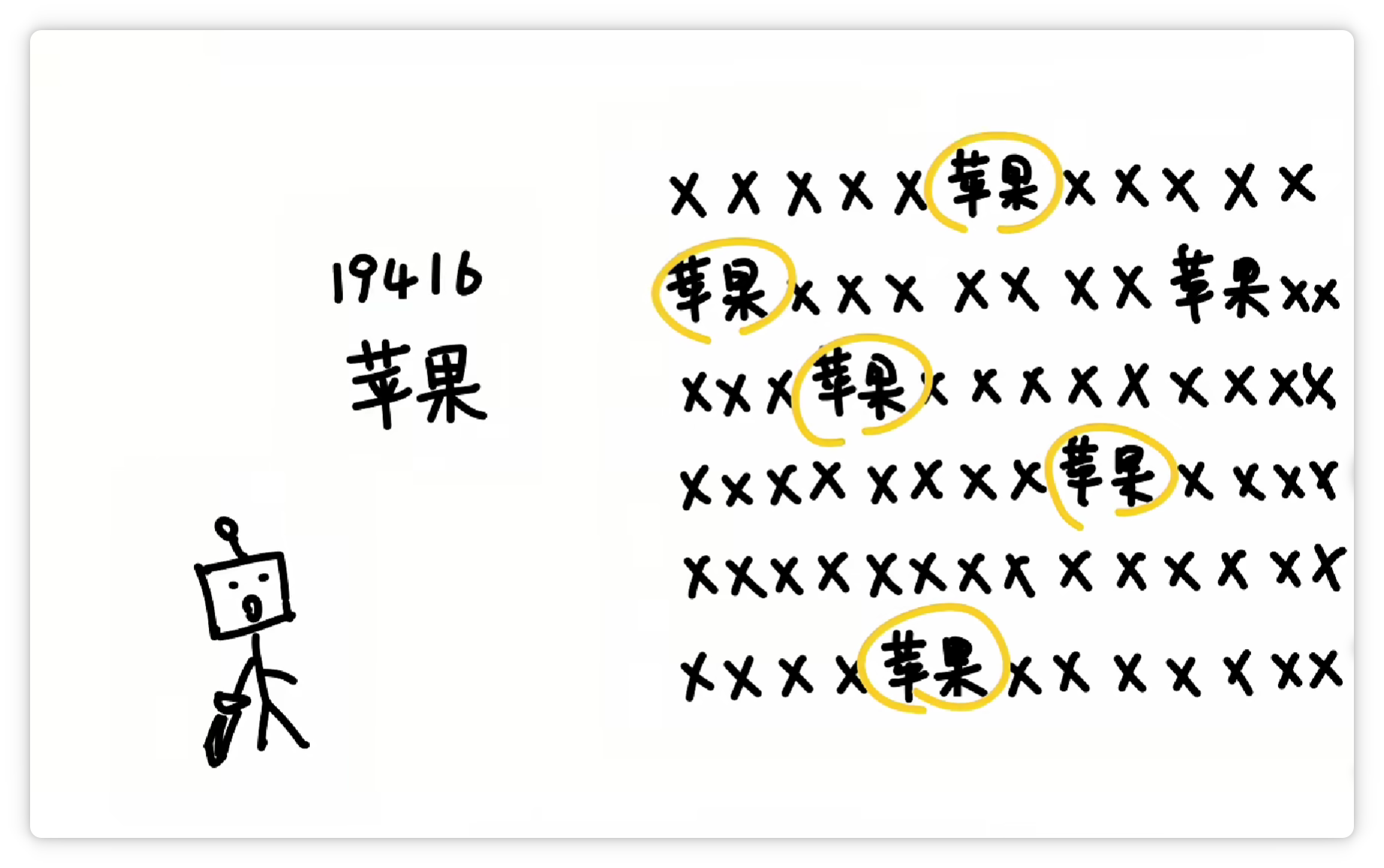
然后丢到一个大的**词汇表**里。
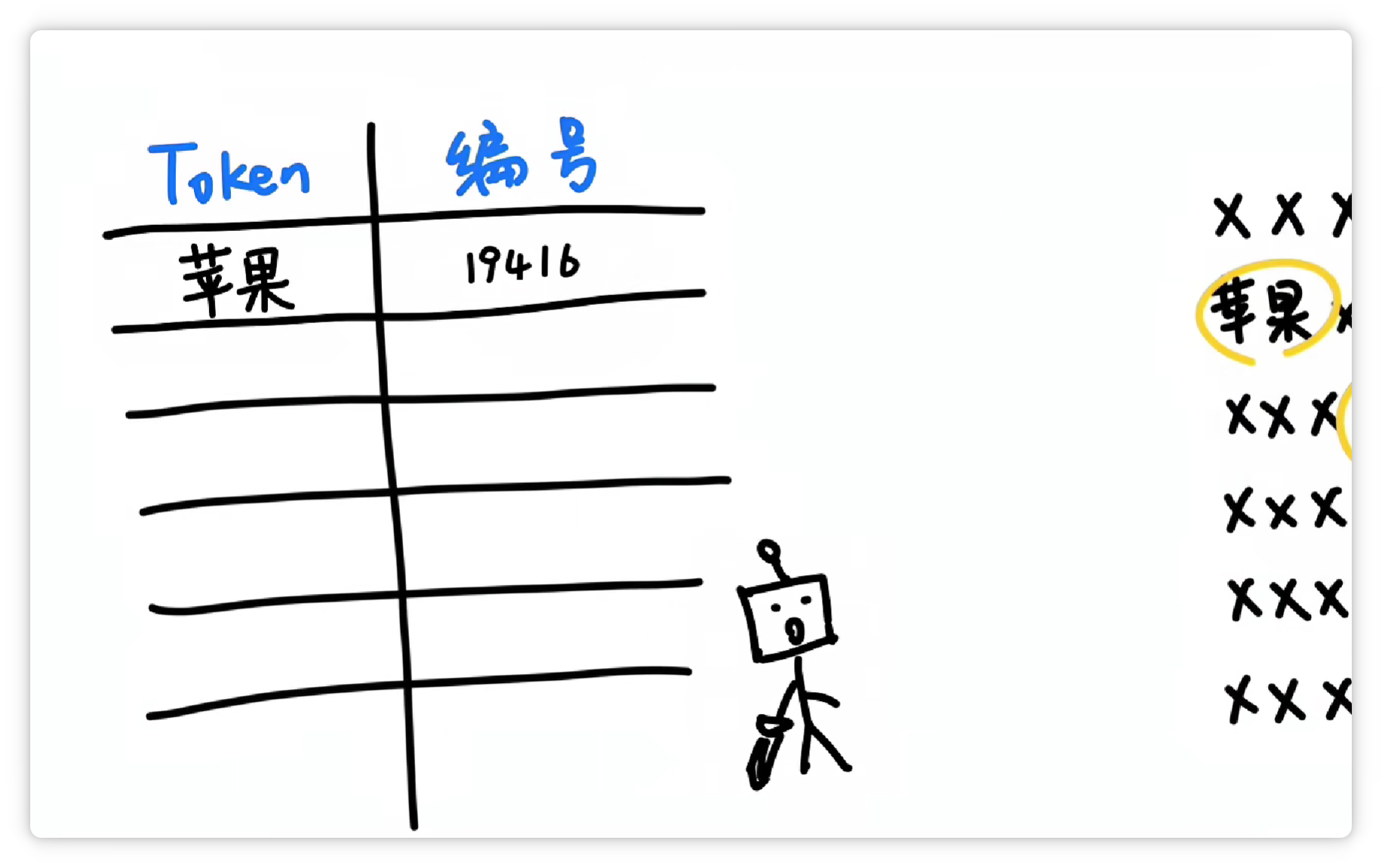
这样下次再看到 **“苹果”** 这两个字的时候,就可以直接认出这个组合就可以了。
然后它可能又发现 **“鸡”** 这个字**经常出现**,并且**可以搭配不同的其他字**。

于是它就把 **“鸡”** 这个字,打包成一个 **Token**,给它**配一个数字编号**,比如 **76074**。

并且丢到**词汇表**里。
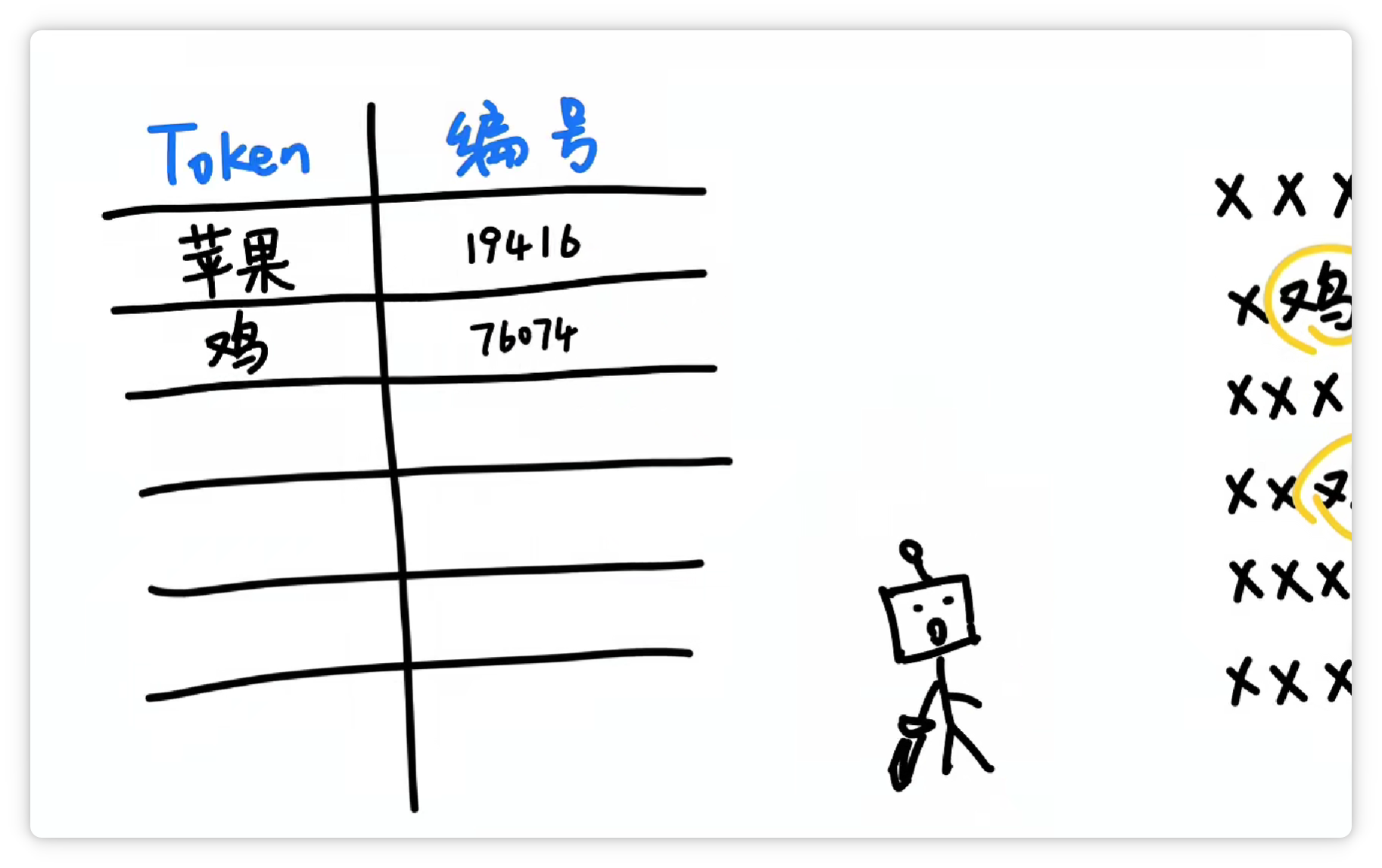
它又发现 **“ing”** 这三个字母**经常一起出现**。
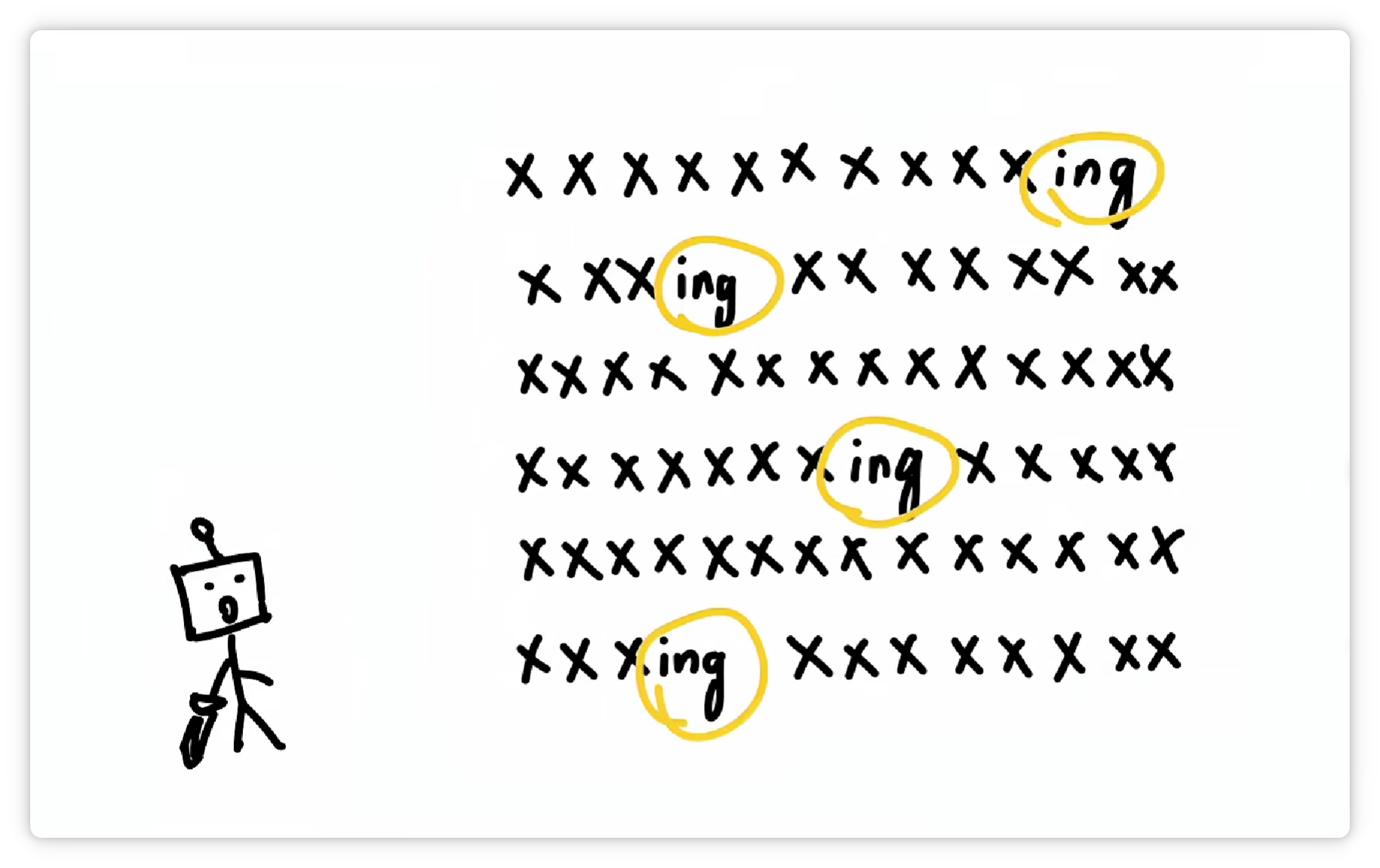
于是又把 **“ing”** 这**三个字母**打包成一个 **Token**,给它**配一个数字编号**,比如 **288**。
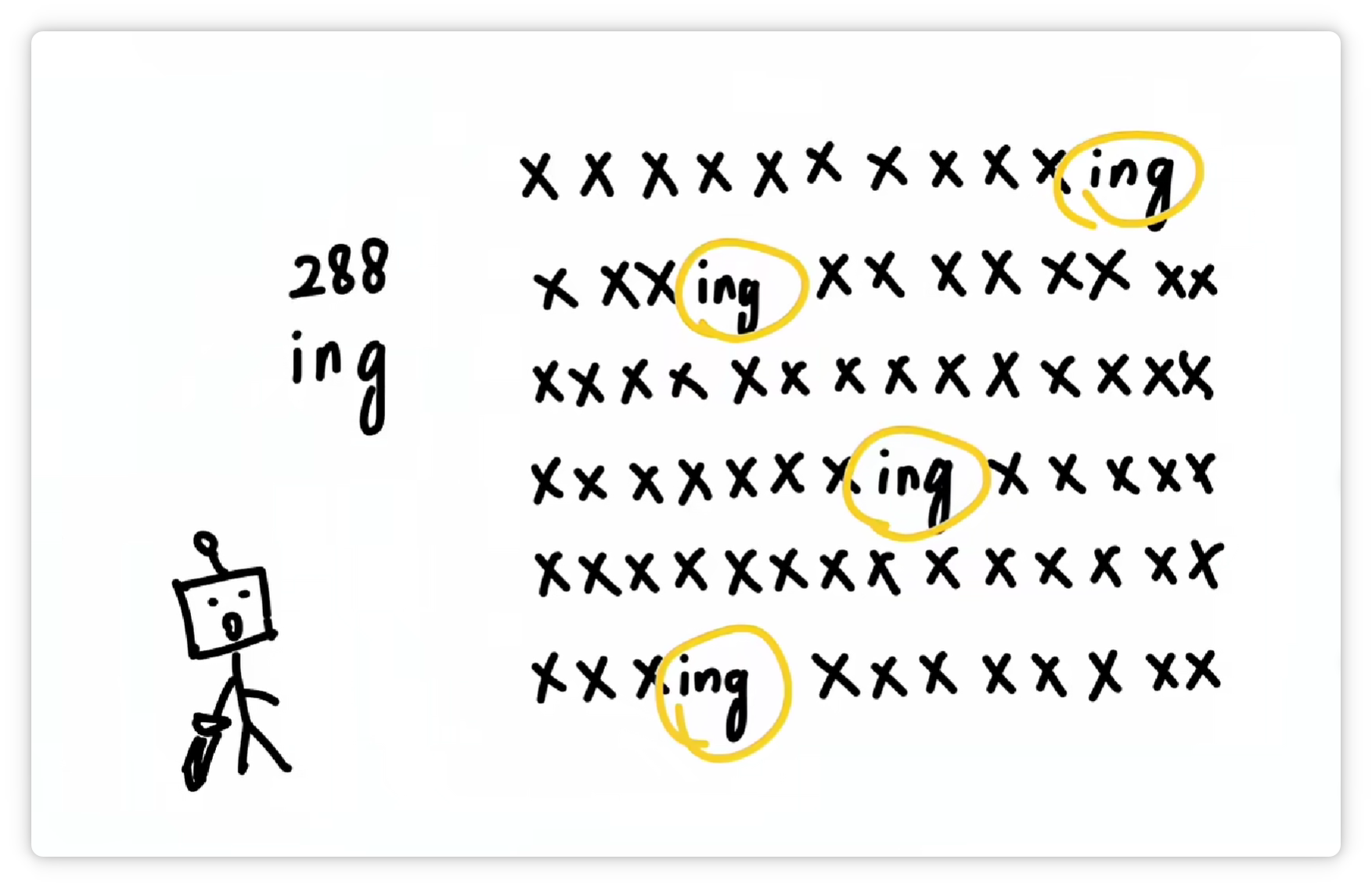
并且收录到**词汇表**里。
它又发现 **“逗号”** 经常出现。

于是又把 **“逗号”** 也打包作为一个 **Token**,给它**配一个数字编号**,比如 **14**。
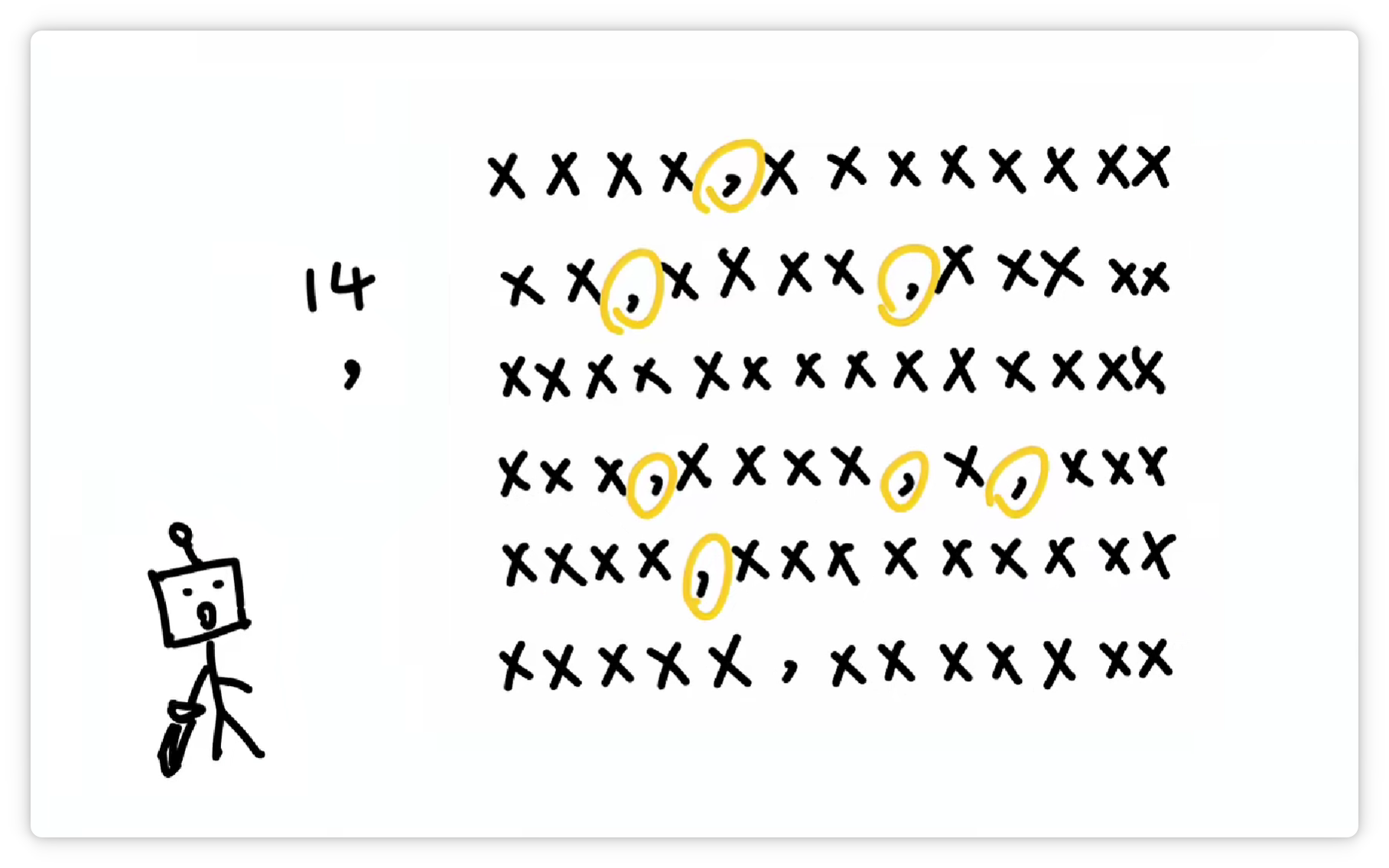
收录到**词汇表**里。
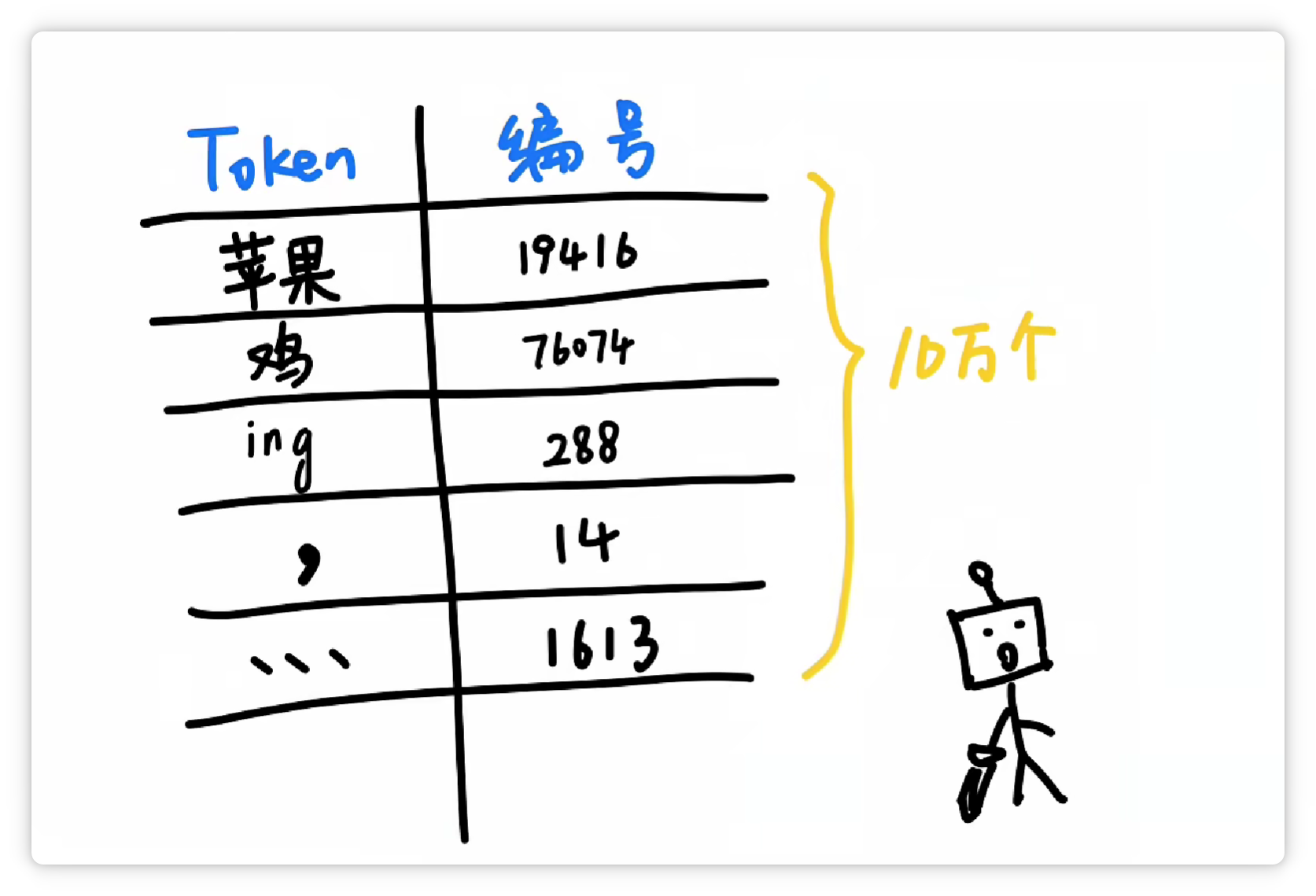
经过**大量统计**和**收集**,分词器就可以得到**一个庞大的Token表**。
可能有**5万个**、**10万个**,甚至**更多Token**,可以**囊括**我们日常见到的各种**字**、**词**、**符号**等等。
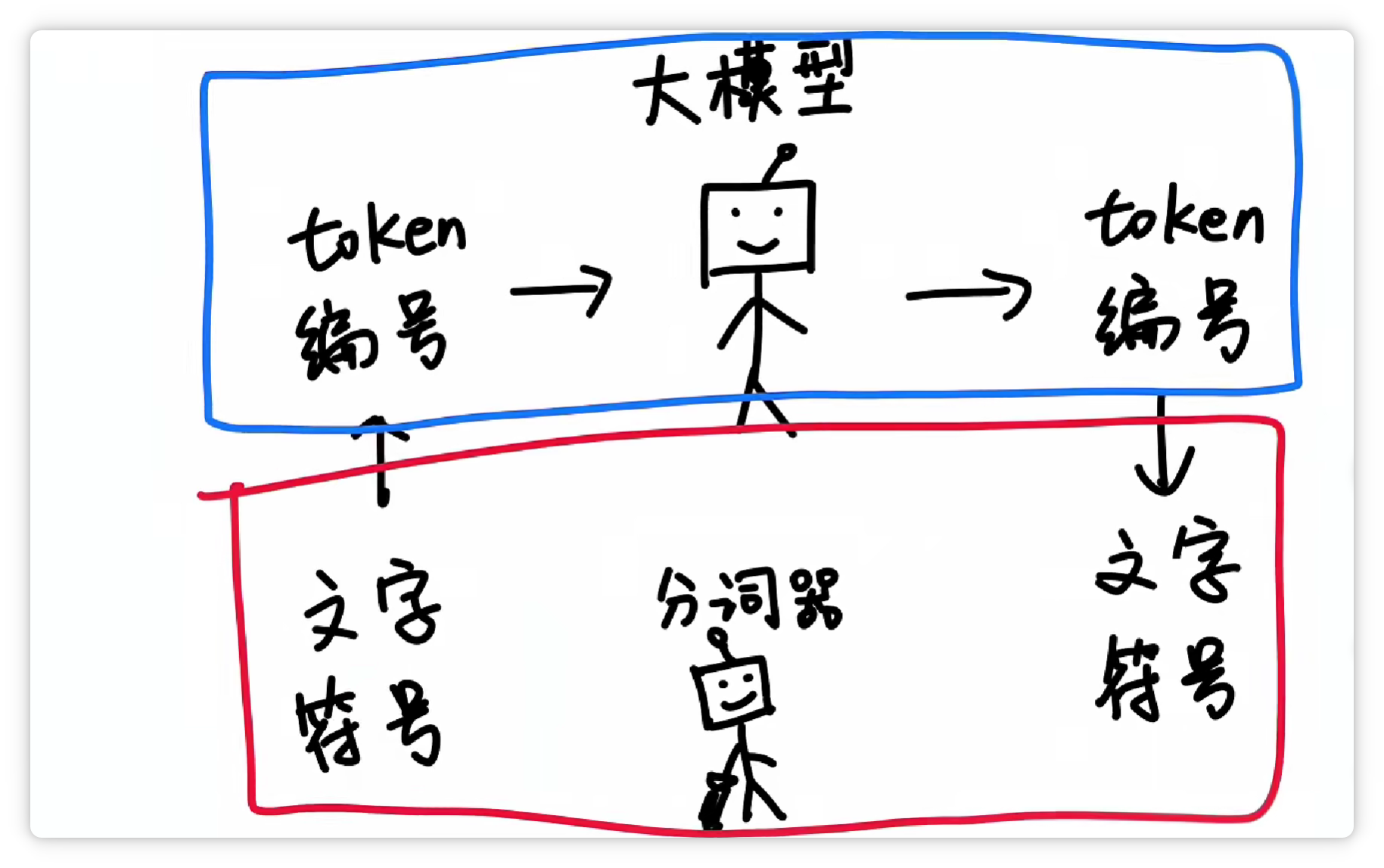
这样一来,大模型在**输入**和**输出**的时候,都只需要**面对一堆数字编号**就可以了。
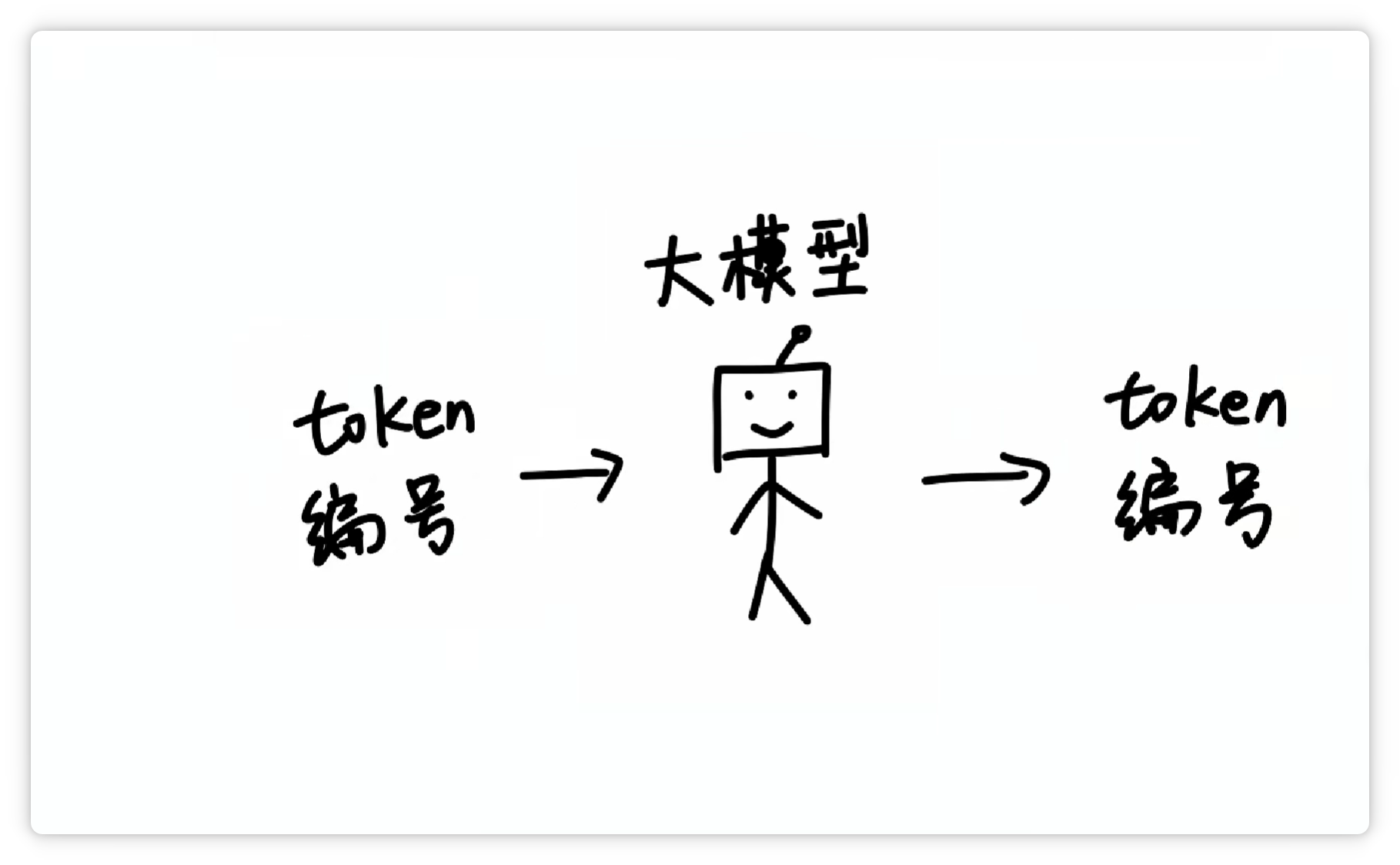
再由分词器**按照Token表**,转换成**人类可以看懂**的**文字**和**符号**。
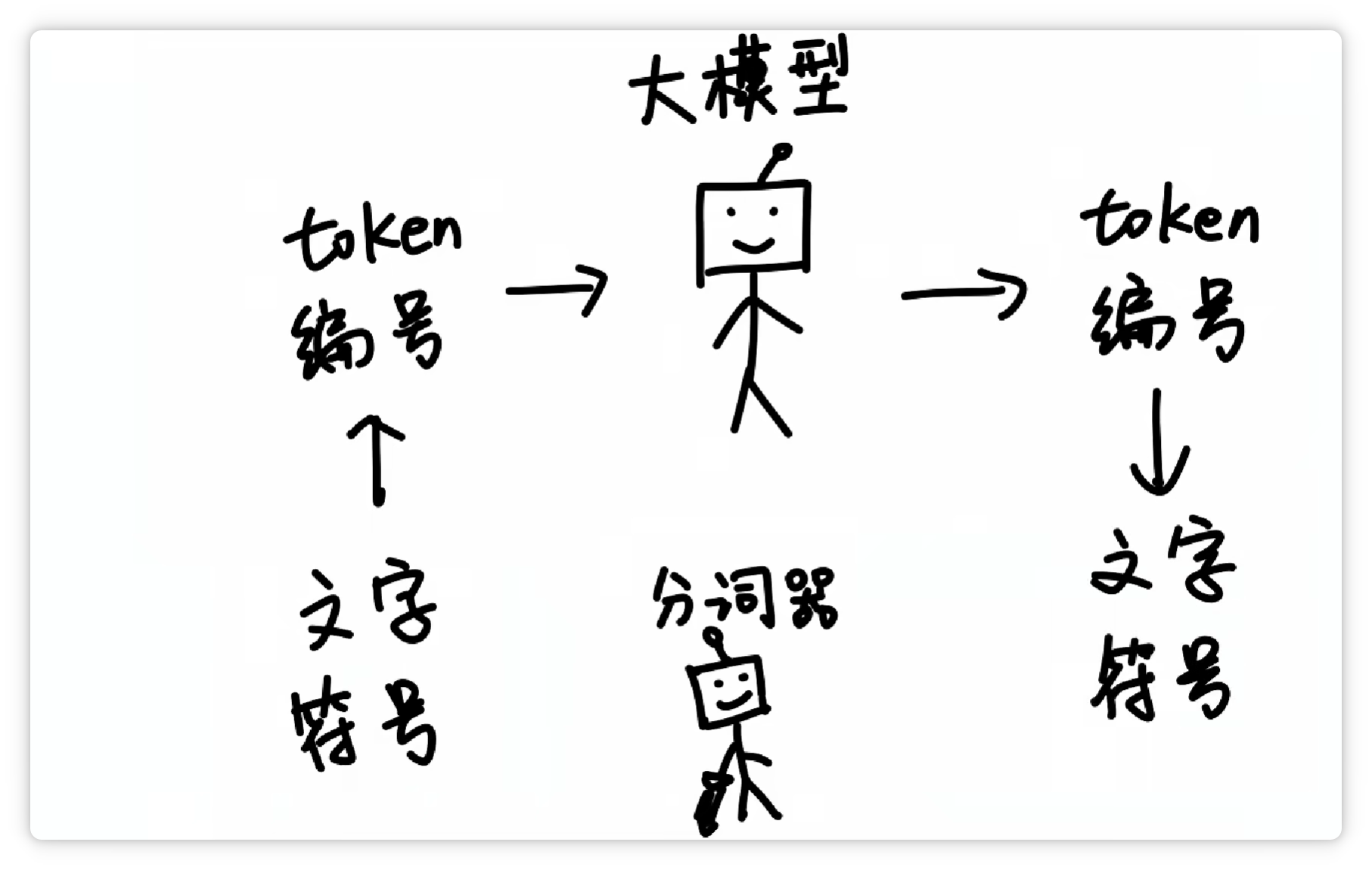
这样一分工,工作效率就非常高。
有这么一个网站 **Tiktokenizer**:
输入一段话,它就可以告诉你,这段话是**由几个Token构成**的,分别是什么,以及这几个**Token的编号分别是多少**。
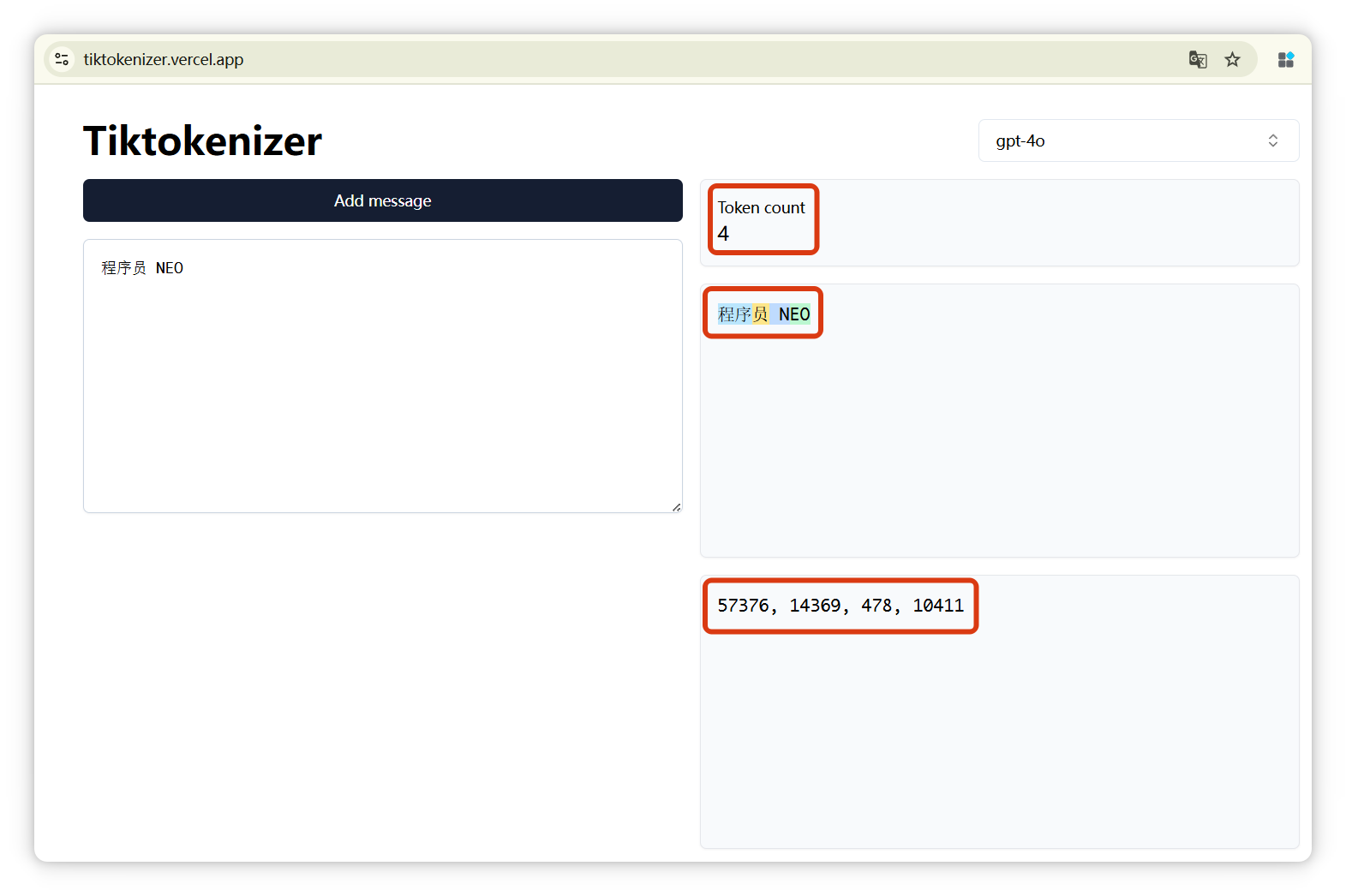
我来演示一下,这个网站有很多模型可以选择,像 **GPT-4o**、**DeepSeek**、**LLaMA** 等等。
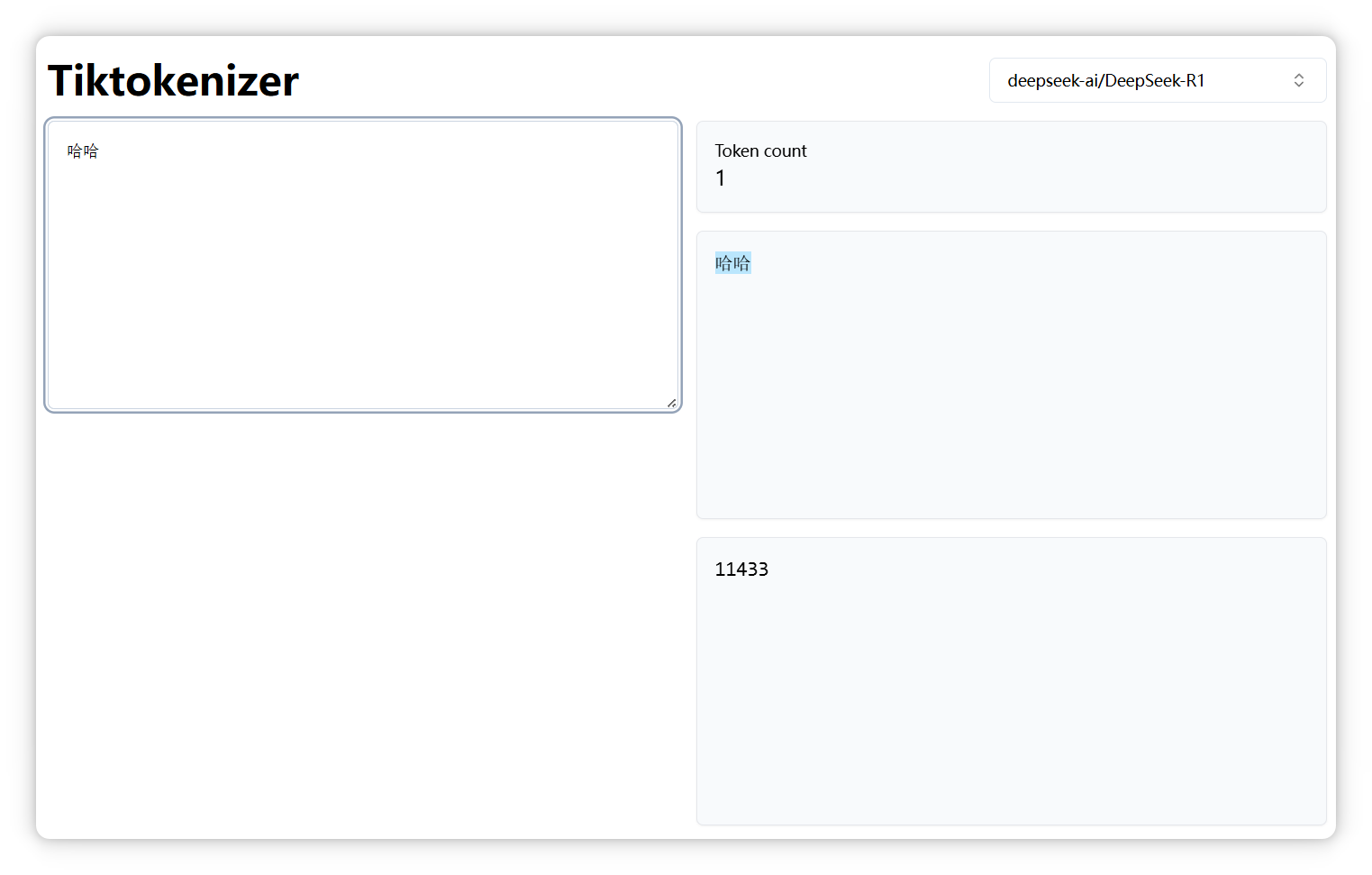
我选的是 **DeepSeek**,我输入 **“哈哈”**,显示是**一个 Token**,编号是 **11433**:
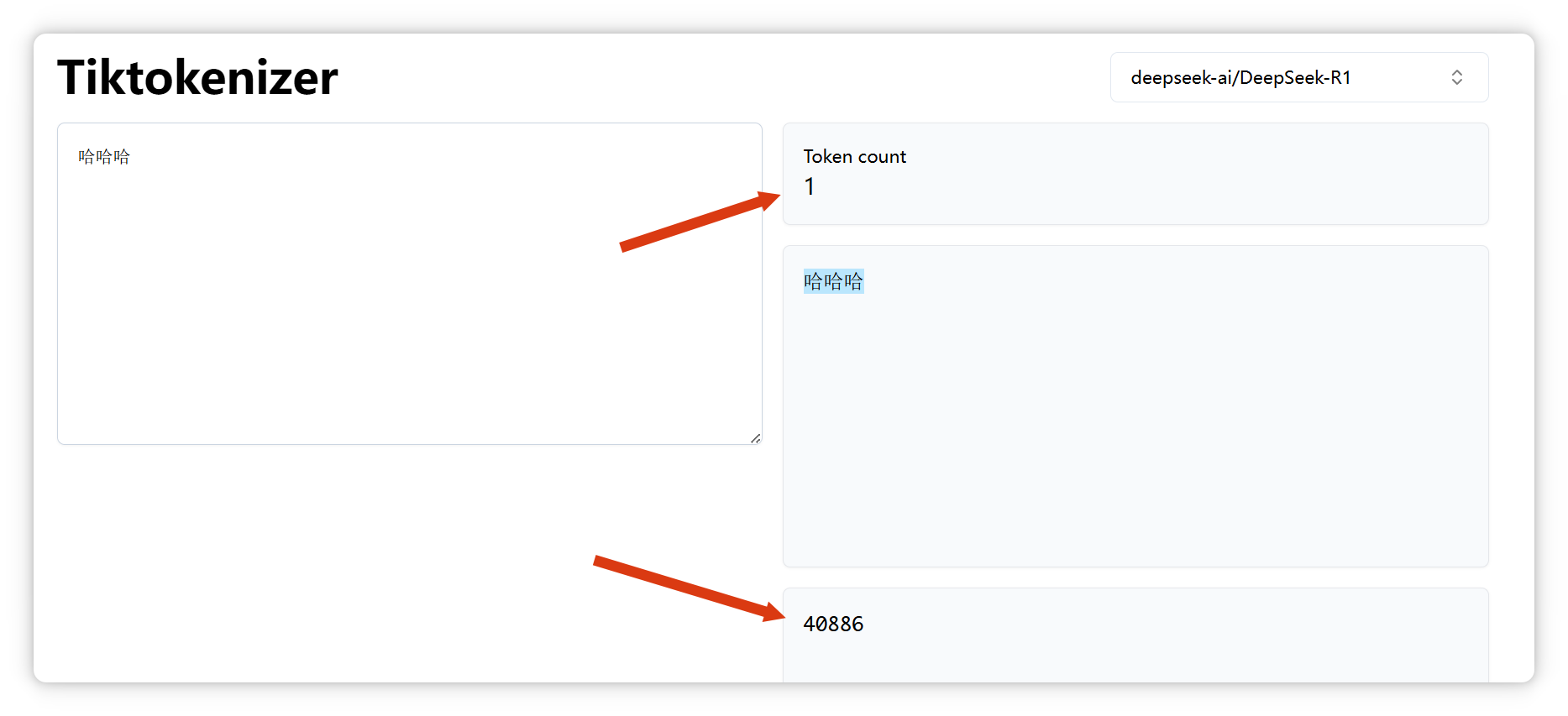
**“哈哈哈”**,也是**一个 Token**,编号是 **40886**:
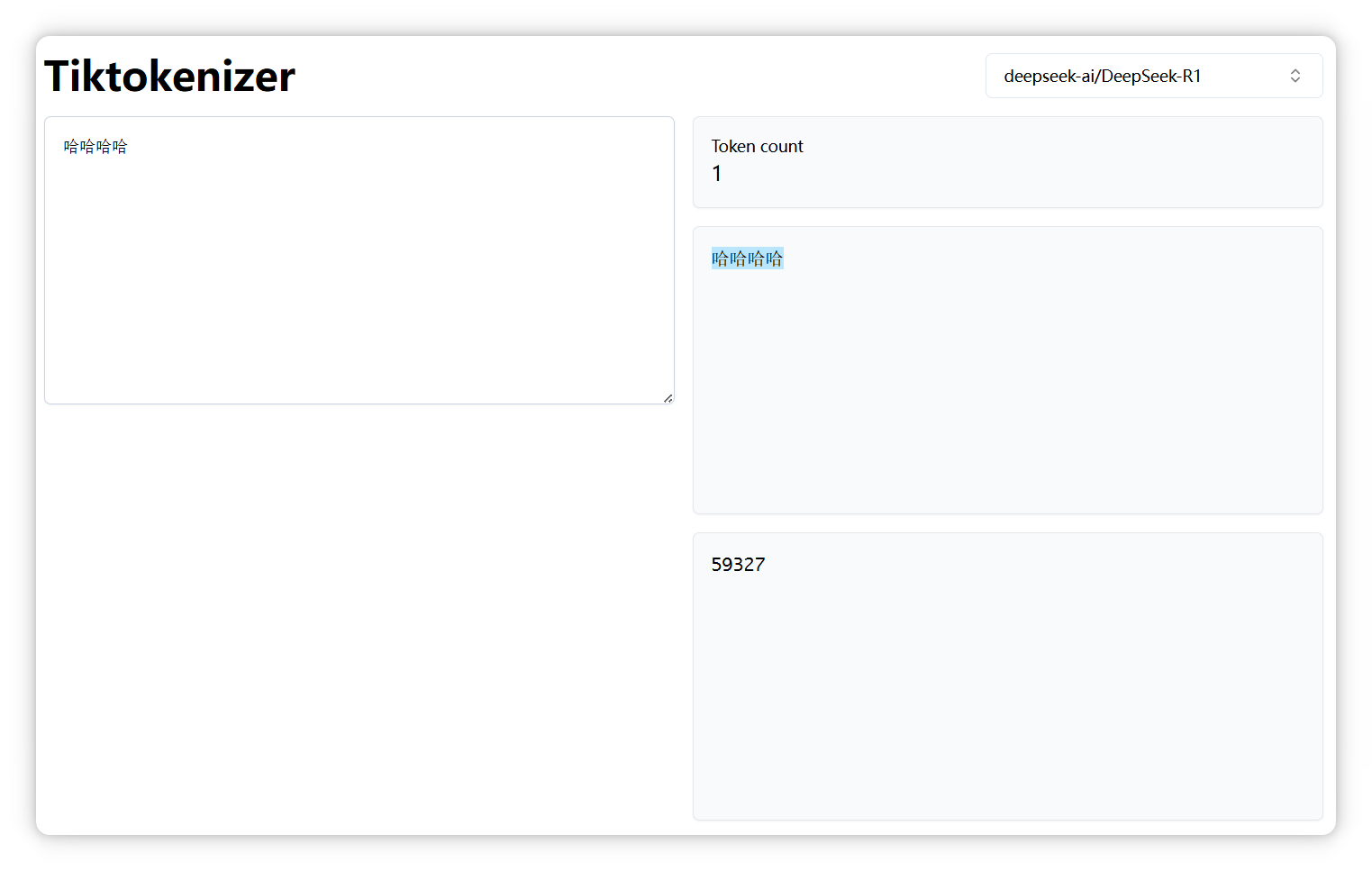
**4**个 **“哈”**,还是**一个 Token**,编号是 **59327**:
但是**5**个 **“哈”**,就变成了**两个Token**,编号分别是 **11433**, **40886**:
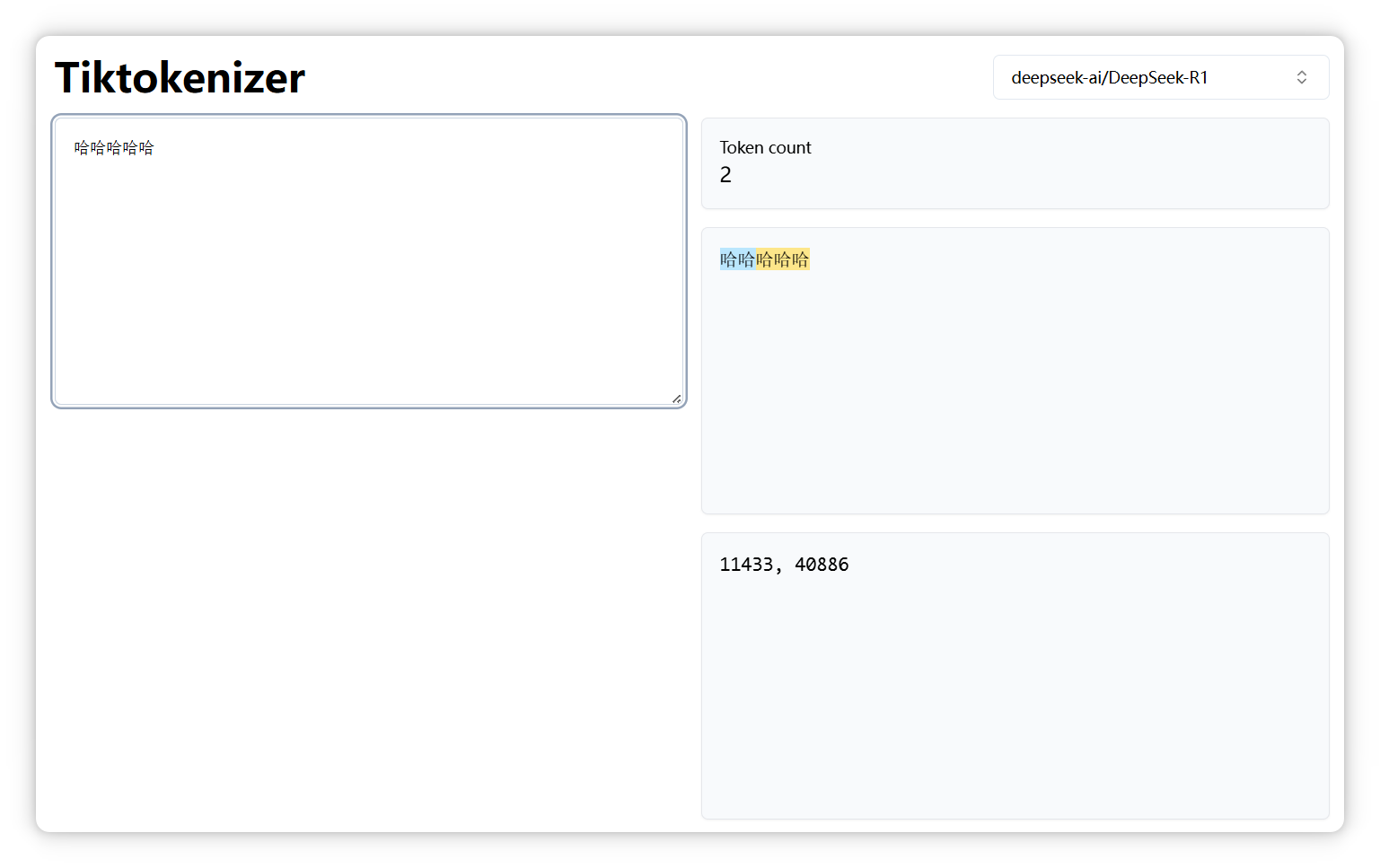
说明大家平常用两个 **“哈”** 或者**三个**的更多。
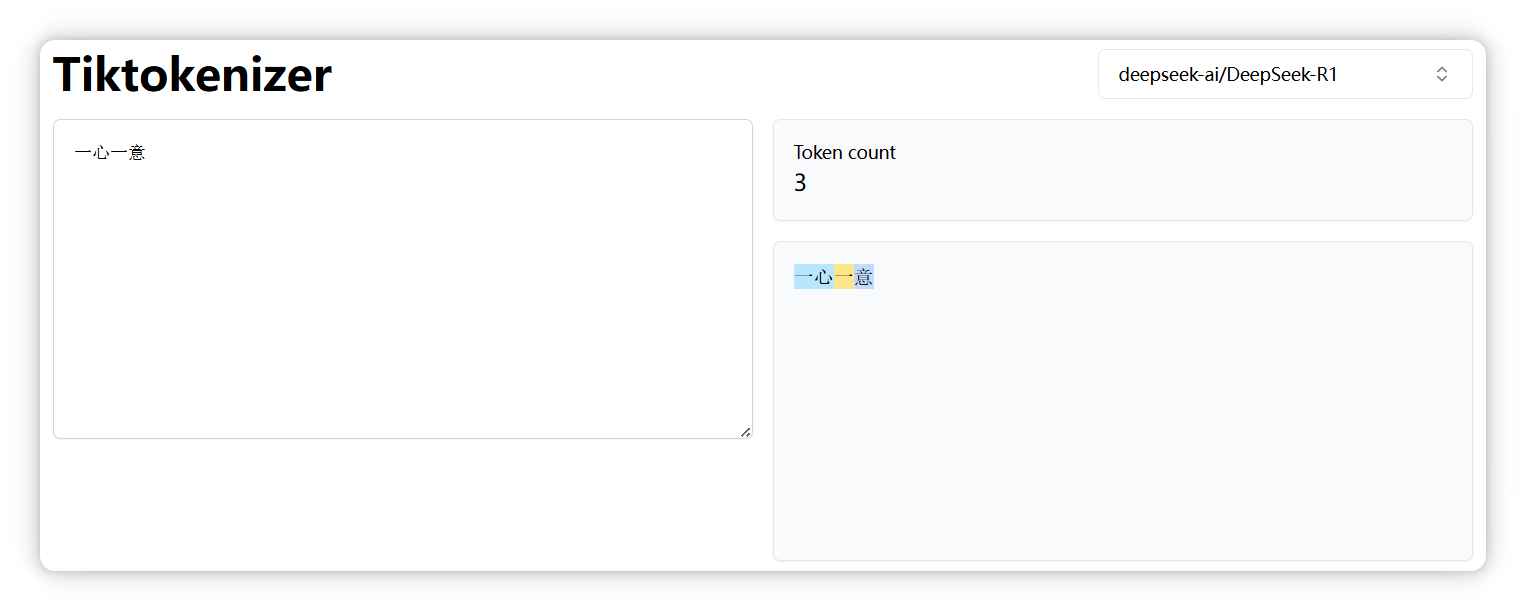
再来,“一心一意” 是三个 Token。
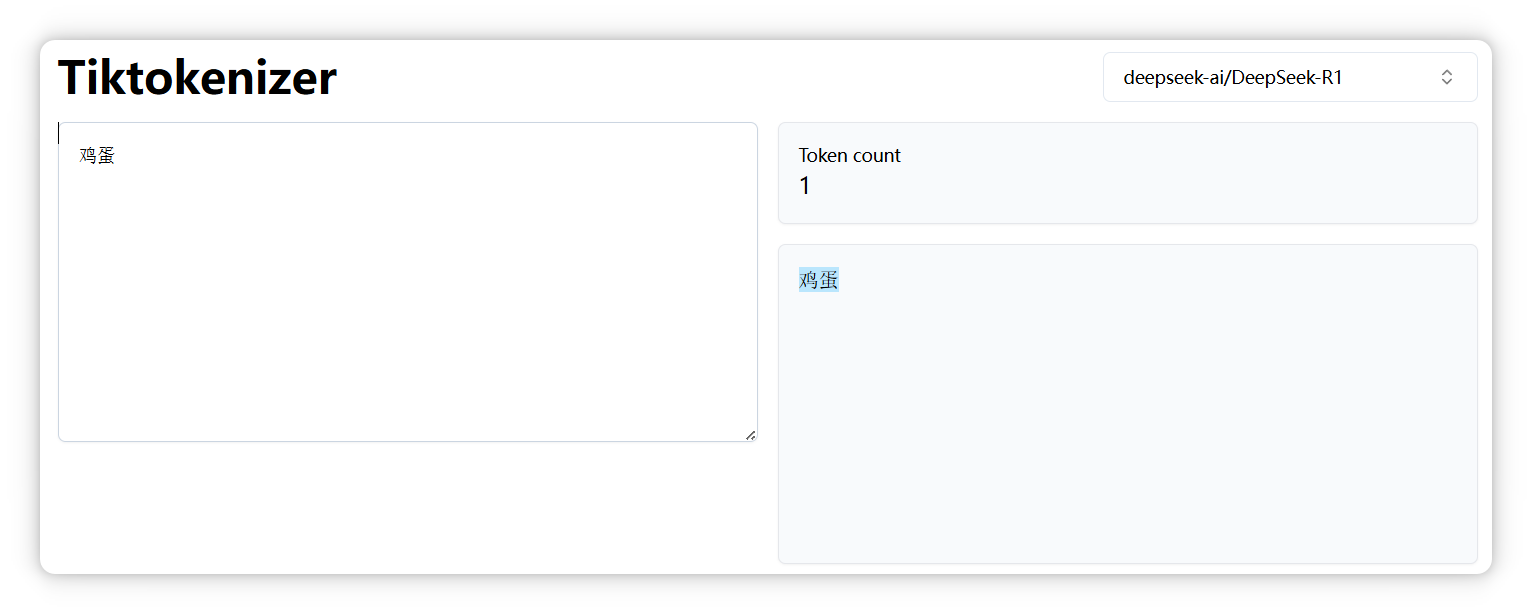
“鸡蛋” 是一个 Token。
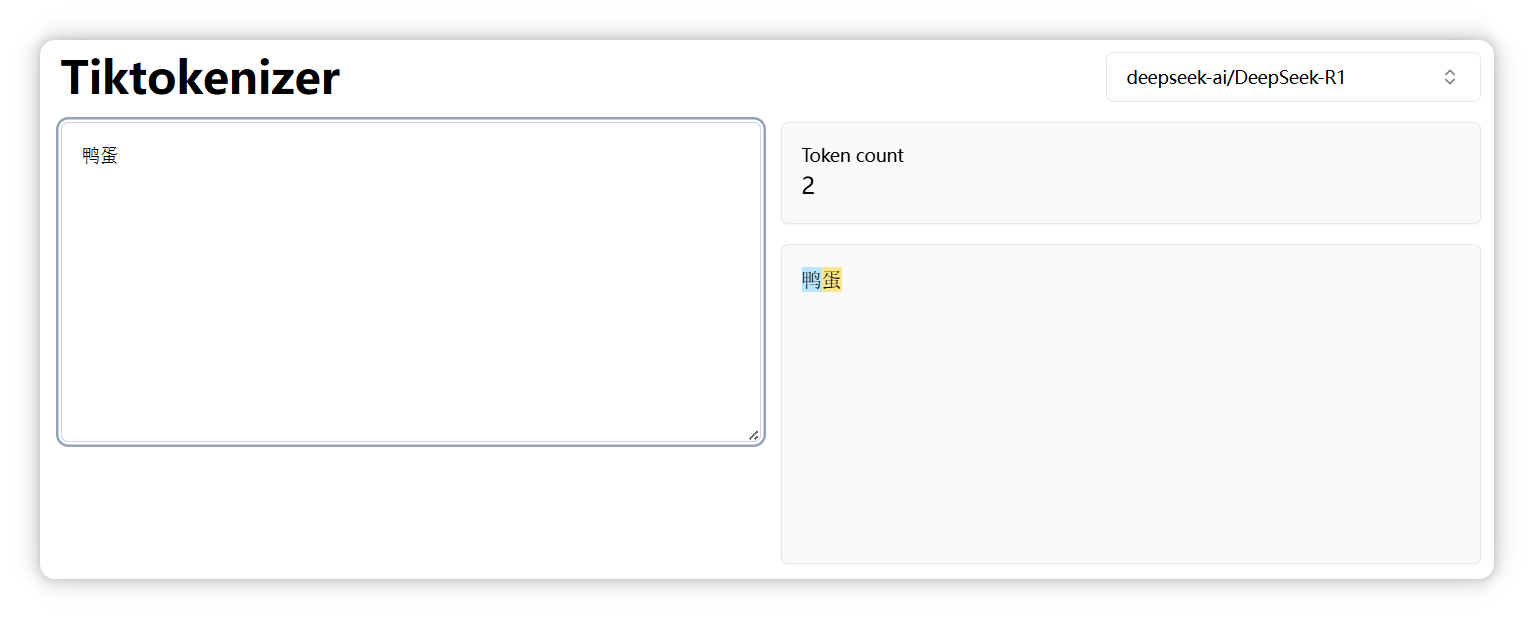
但是 “鸭蛋” 是两个 Token。
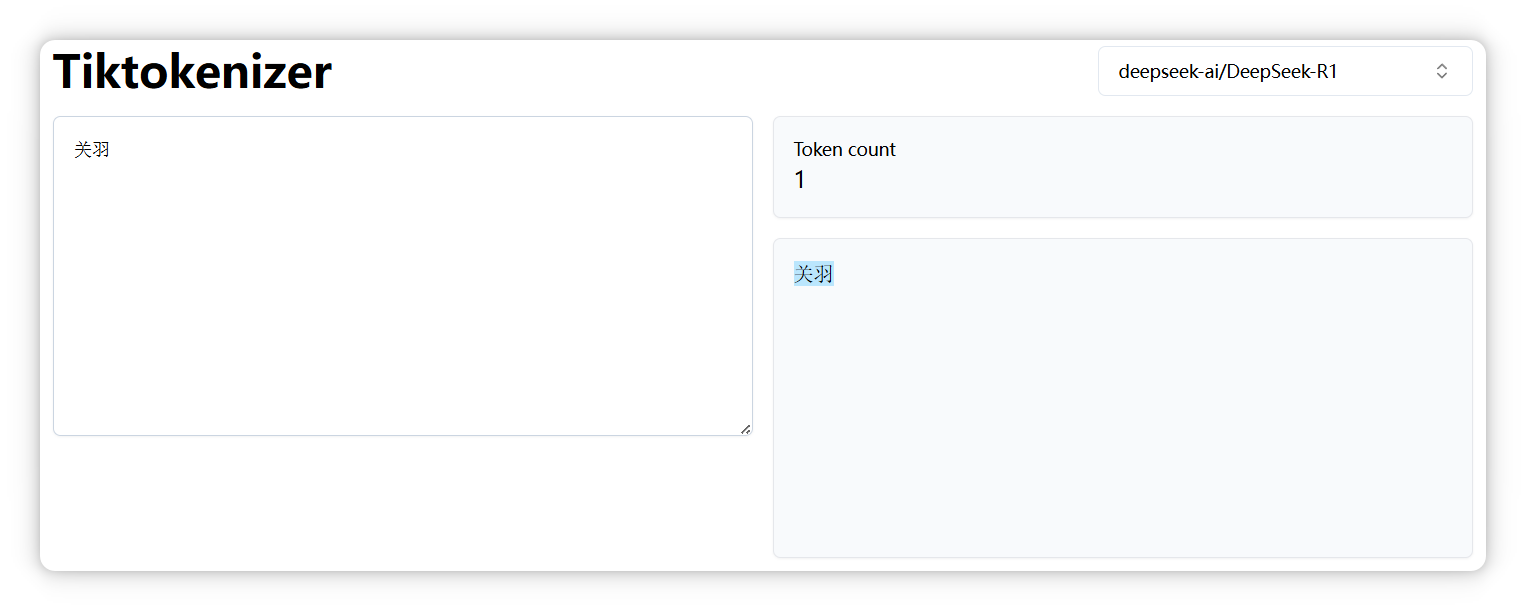
“关羽” 是一个 Token。
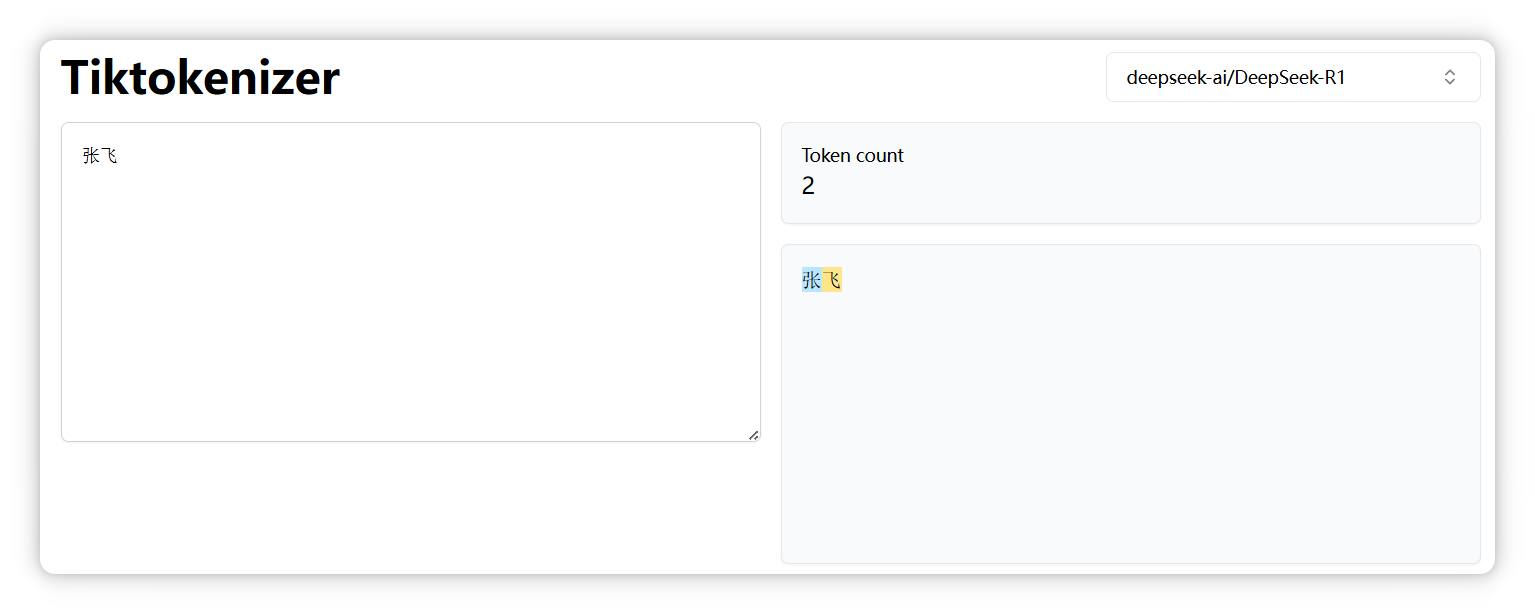
“张飞” 是两个 Token。
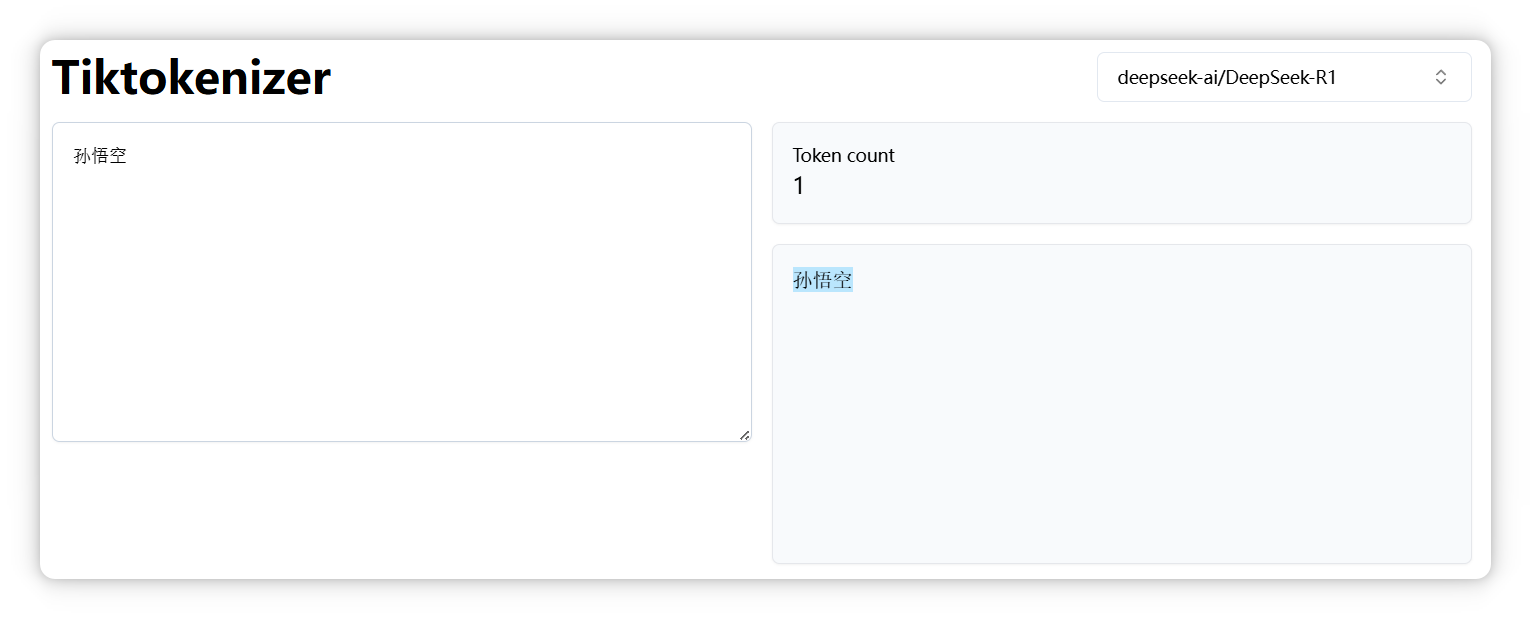
“孙悟空” 是一个 Token。
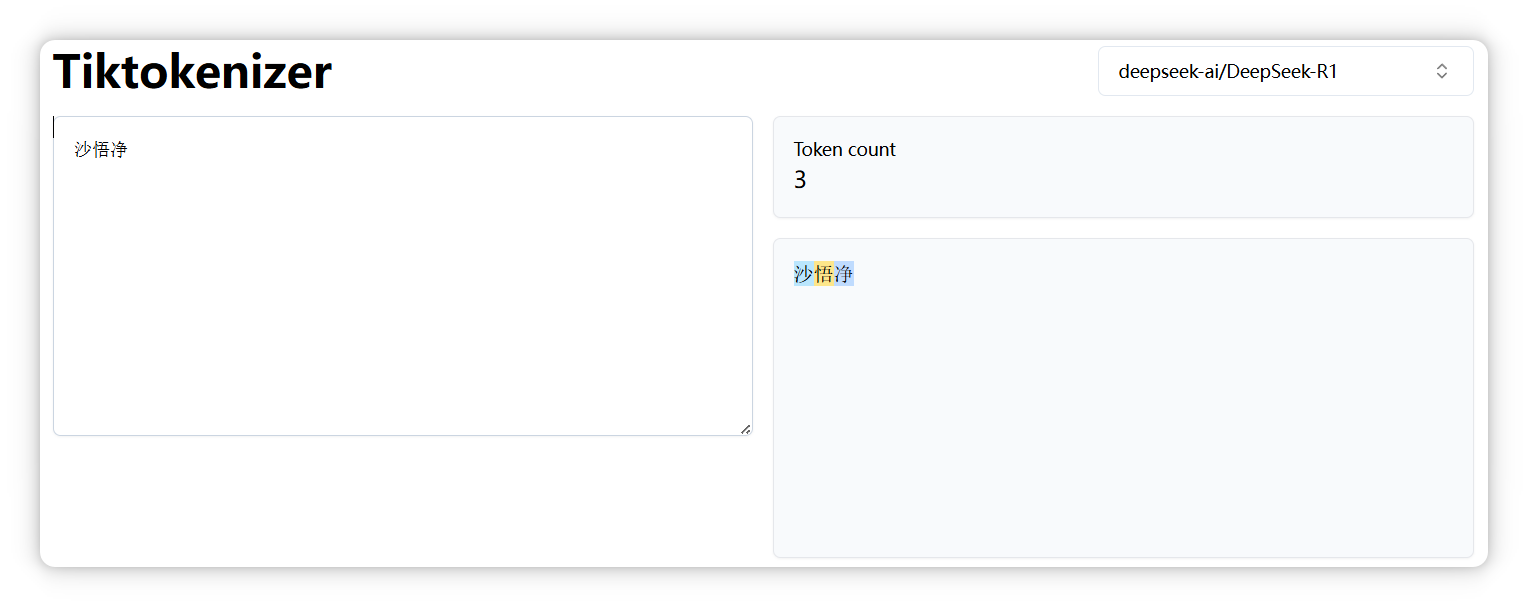
“沙悟净” 是三个 Token。
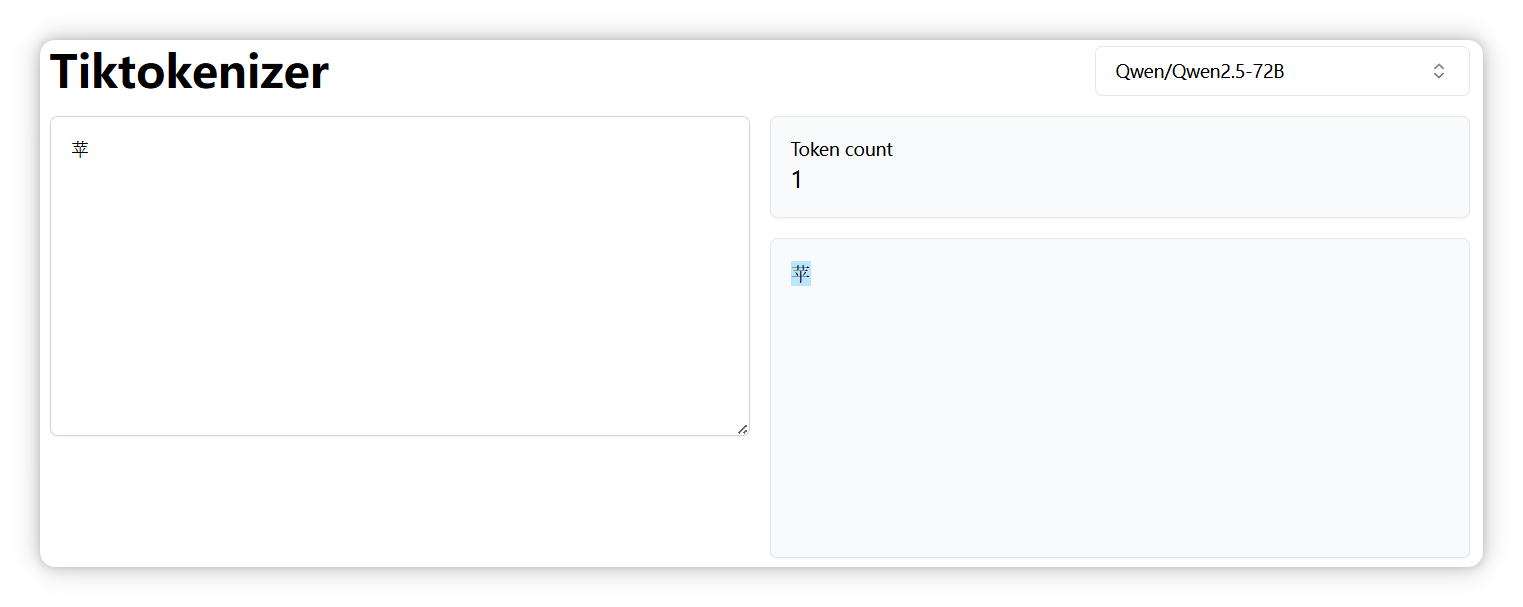
另外,正如前面提到的,不同模型的分词器可能会有不同的切分结果。比如,“**苹果**” 中的 “**苹**” 字,在 **DeepSeek** 中被拆分成两个 Token。
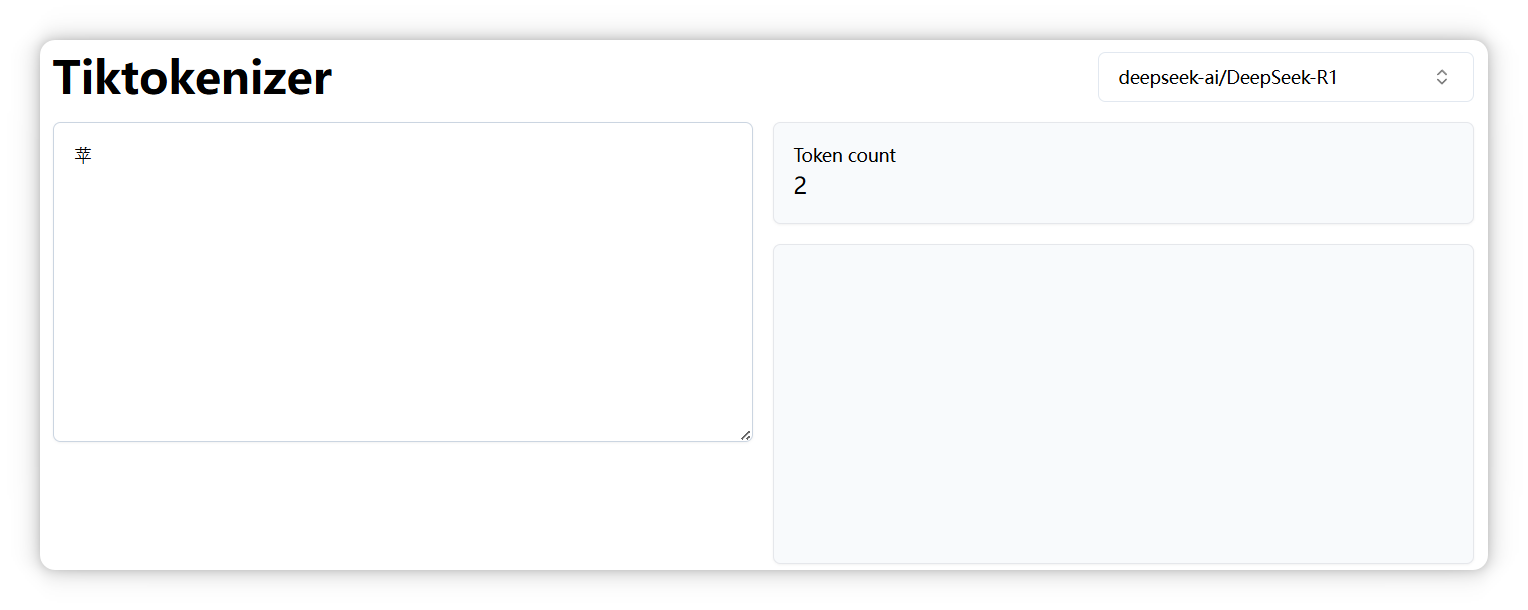
但是在 `Qwen` 模型里却是一个 Token。
所以回过头来看,**Token** 到底是什么?
它就是构建大模型世界的一块块积木。
大模型之所以能理解和生成文本,就是通过计算这些 Token 之间的关系,来预测下一个最可能出现的 Token。
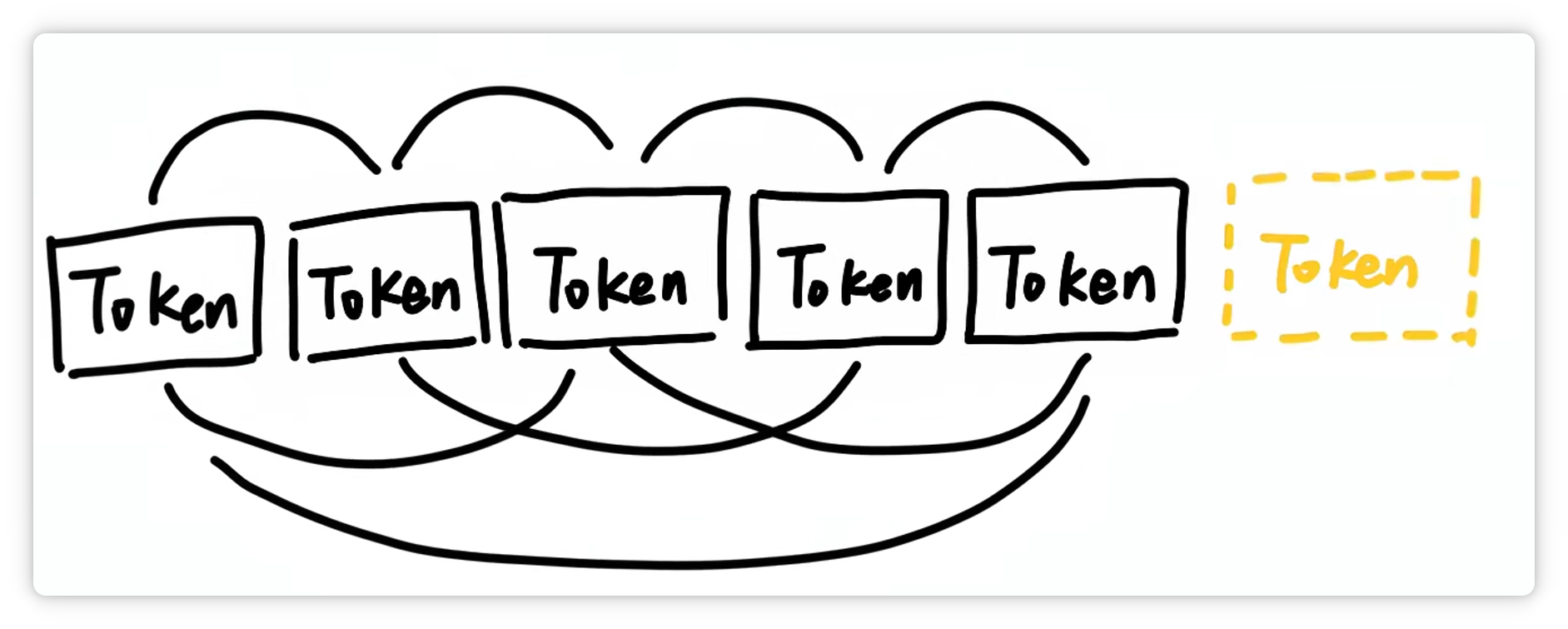
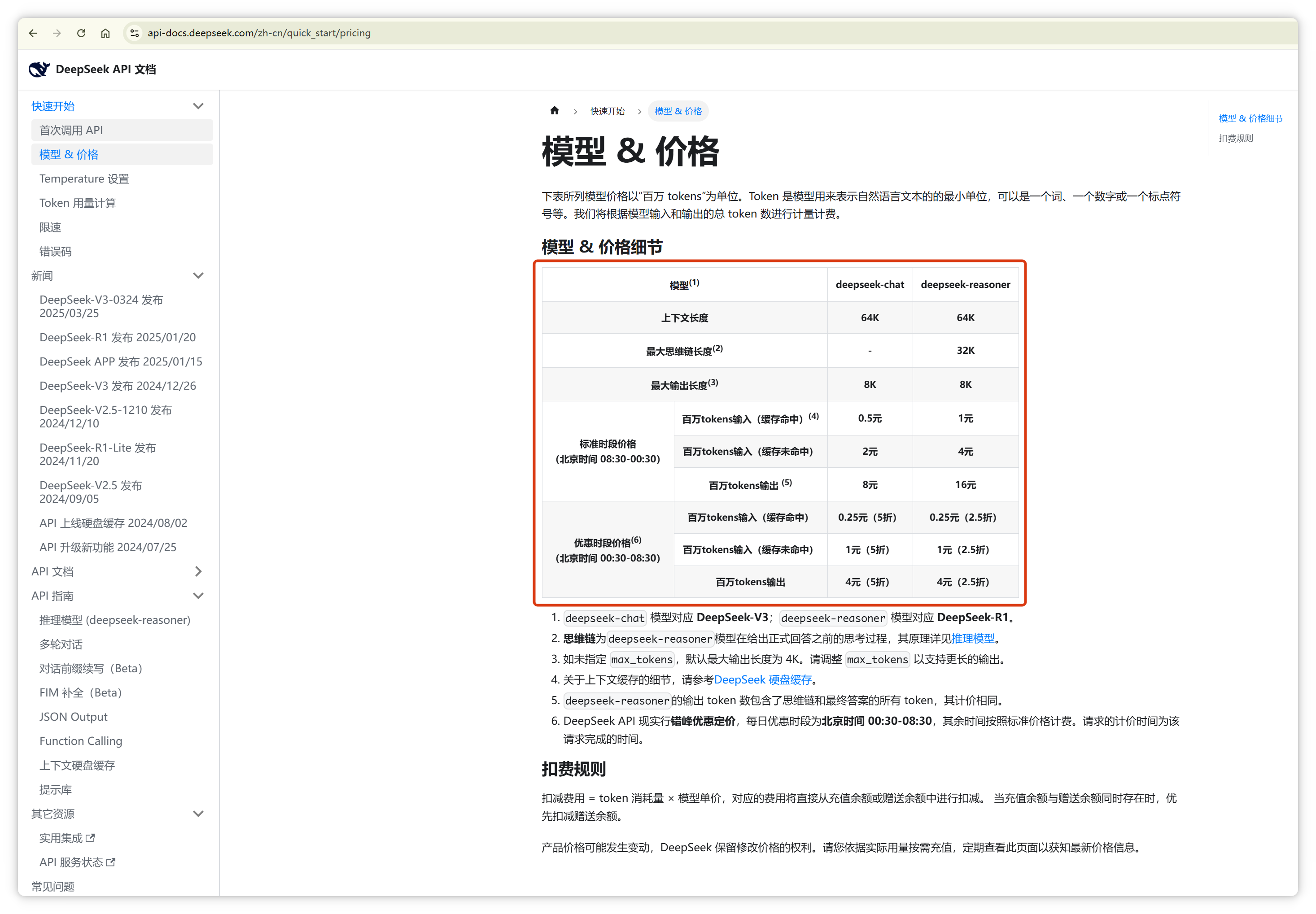
这就是为什么几乎所有大模型公司都按照 **Token** 数量计费,因为 Token 数量直接对应背后的计算成本。
“**Token**” 这个词不仅用于**人工智能**领域,在其他领域也经常出现。其实,它们只是**恰好**都叫这个名字而已。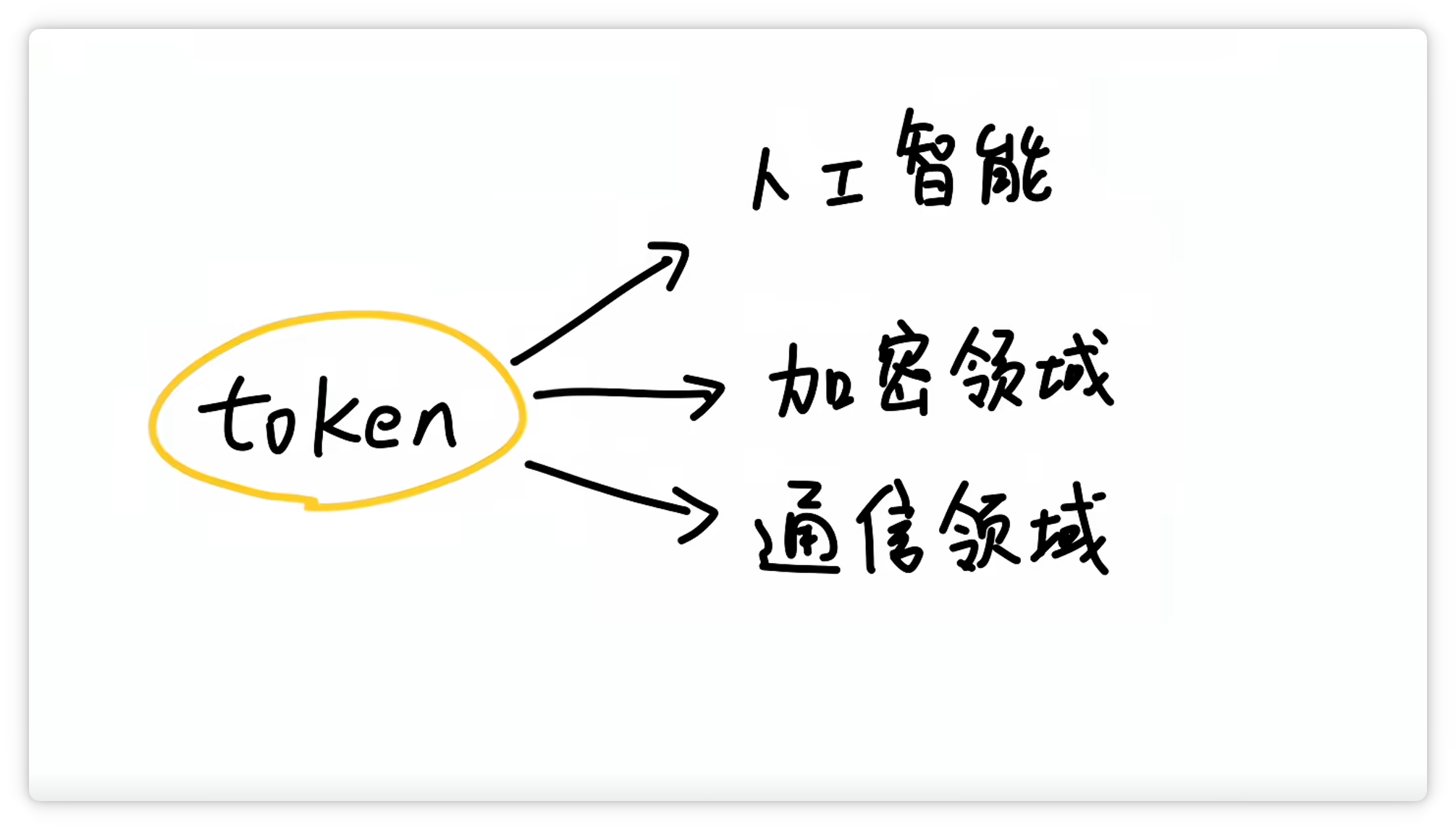
就像同样都是 **“车模”**,**汽车模型**和**车展模特**,虽然用词相同,但含义却**截然不同**。

# FAQ
## 1. 苹为啥会是2个?
因为“苹” 字单独出现的概率太低,无法独立成为一个 Token。
## 2. 为什么张飞算两个 Token?
“张” 和 “飞” 一起出现的频率不够高,或者“ 张” 字和 “飞” 字的搭配不够稳定,经常与其他字组合,因此被拆分为两个 Token。
Token 在大模型方面最好的翻译是 '词元' 非常的信雅达。
本文来自投稿,不代表本站立场,如若转载,请注明出处:http//www.knowhub.vip/share/2/1895
- 热门的技术博文分享
- 1 . ESP实现Web服务器
- 2 . 从零到一:打造高效的金仓社区 API 集成到 MCP 服务方案
- 3 . 使用C#构建一个同时问多个LLM并总结的小工具
- 4 . .NET 原生驾驭 AI 新基建实战系列Milvus ── 大规模 AI 应用的向量数据库首选
- 5 . 在Avalonia/C#中使用依赖注入过程记录
- 6 . [设计模式/Java] 设计模式之工厂方法模式
- 7 . 5. RabbitMQ 消息队列中 Exchanges(交换机) 的详细说明
- 8 . SQL 中的各种连接 JOIN 的区别总结!
- 9 . JavaScript 中防抖和节流的多种实现方式及应用场景
- 10 . SaltStack 远程命令执行中文乱码问题
- 11 . 推荐10个 DeepSeek 神级提示词,建议搜藏起来使用
- 12 . C#基础:枚举、数组、类型、函数等解析
- 13 . VMware平台的Ubuntu部署完全分布式Hadoop环境
- 14 . C# 多项目打包时如何将项目引用转为包依赖
- 15 . Chrome 135 版本开发者工具(DevTools)更新内容
- 16 . 从零创建npm依赖,只需执行一条命令
- 17 . 关于 Newtonsoft.Json 和 System.Text.Json 混用导致的的序列化不识别的问题
- 18 . 大模型微调实战之训练数据集准备的艺术与科学
- 19 . Windows快速安装MongoDB之Mongo实战
- 20 . 探索 C# 14 新功能:实用特性为编程带来便利
- 相关联分享
- 大模型中的Token:概念、分词器作用及详解