【快速判断是否存在利器】布隆过滤器和布谷鸟过滤器
笔记哥 /
03-14 /
18点赞 /
0评论 /
346阅读
## 从入门到精通:布隆过滤器和布谷鸟过滤器
在计算机科学领域,过滤器(Filter)是一种用于快速判断元素是否属于某个集合的数据结构。布隆过滤器(Bloom Filter)和布谷鸟过滤器(Cuckoo Filter)是两种常用的概率型过滤器,它们以高效的空间利用率和查询速度著称,广泛应用于缓存系统、数据库、网络爬虫等场景。
本文将带你从入门到精通,深入了解布隆过滤器和布谷鸟过滤器的原理、优缺点、应用场景以及实现细节,并基于 Spring Boot 项目提供保姆级的代码示例。
* * *
### 一、布隆过滤器 (Bloom Filter)
#### 1.1 简介
布隆过滤器是由 Burton Howard Bloom 在 1970 年提出的一种空间效率很高的概率型数据结构。它利用多个哈希函数将一个元素映射到一个位数组中,用于判断一个元素是否属于某个集合。
#### 1.2 工作原理
1. **初始化**:创建一个长度为 m 的位数组,所有位初始化为 0。
2. **添加元素**:使用 k 个独立的哈希函数将元素映射到位数组中的 k 个位置,并将这些位置置为 1。
3. **查询元素**:使用相同的 k 个哈希函数计算元素对应的 k 个位置,如果所有位置都为 1,则认为元素可能存在;如果有任何一个位置为 0,则元素一定不存在。
#### 1.3 底层剖析
布隆过滤器的核心在于**多哈希函数映射**和**位数组存储**。以下是其底层实现的关键点:
- **哈希函数**:布隆过滤器使用 k 个独立的哈希函数,每个哈希函数将输入元素映射到位数组中的一个位置。为了减少冲突,哈希函数应具有良好的均匀分布性。
- **位数组**:位数组是布隆过滤器的存储结构,每个元素通过哈希函数映射到位数组中的多个位置。位数组的长度 m 和哈希函数的数量 k 共同决定了布隆过滤器的误判率。
- **误判率**:布隆过滤器的误判率取决于位数组的长度 m、哈希函数的数量 k 以及插入的元素数量 n。误判率的计算公式为:
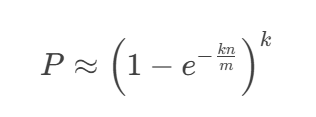
通过调整 m 和 k,可以控制误判率。
#### 1.4 优缺点
**优点**:
- **空间效率高**:布隆过滤器使用位数组存储数据,空间复杂度为 O(m)。
- **查询速度快**:查询时间复杂度为 O(k),k 为哈希函数的数量。
- **支持动态添加**:可以动态地向布隆过滤器中添加元素。
**缺点**:
- **存在误判率**:布隆过滤器可能会出现误判,即判断一个不存在的元素为存在。
- **不支持删除**:由于多个元素可能共享同一个位,删除操作会影响其他元素的判断。
#### 1.5 应用场景
- **缓存系统**:用于快速判断数据是否在缓存中,避免缓存穿透。
- **数据库查询优化**:用于快速判断某个键是否在数据库中,减少磁盘 I/O。
- **网络爬虫**:用于记录已访问的 URL,避免重复爬取。
#### 1.6 Spring Boot 实现示例
以下是一个基于 Spring Boot 的布隆过滤器实现示例:
##### 1.6.1 添加依赖
在 `pom.xml` 中添加 Guava 库依赖(Guava 提供了布隆过滤器的实现):
```xml
com.google.guava
guava
32.1.2-jre
```
##### 1.6.2 实现布隆过滤器
```java
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import org.springframework.stereotype.Service;
import java.nio.charset.StandardCharsets;
@Service
public class BloomFilterService {
// 初始化布隆过滤器,预计插入 1000 个元素,误判率为 0.01
private BloomFilter bloomFilter = BloomFilter.create(
Funnels.stringFunnel(StandardCharsets.UTF_8), 1000, 0.01);
/**
* 添加元素到布隆过滤器
*/
public void add(String element) {
bloomFilter.put(element);
}
/**
* 判断元素是否可能存在
*/
public boolean mightContain(String element) {
return bloomFilter.mightContain(element);
}
}
```
##### 1.6.3 测试布隆过滤器
```java
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class BloomFilterController {
@Autowired
private BloomFilterService bloomFilterService;
@GetMapping("/add")
public String addElement(@RequestParam String element) {
bloomFilterService.add(element);
return "Added: " + element;
}
@GetMapping("/check")
public String checkElement(@RequestParam String element) {
boolean exists = bloomFilterService.mightContain(element);
return "Element " + element + " might exist: " + exists;
}
}
```
##### 1.6.4 运行测试
启动 Spring Boot 项目后,访问以下 URL 进行测试:
- 添加元素:`http://localhost:8080/add?element=test`
- 检查元素:`http://localhost:8080/check?element=test`
* * *
### 二、布谷鸟过滤器 (Cuckoo Filter)
#### 2.1 简介
布谷鸟过滤器是布隆过滤器的一种改进版本,由 Bin Fan 等人在 2014 年提出。它通过使用布谷鸟哈希(Cuckoo Hashing)来解决布隆过滤器不支持删除操作的问题。
#### 2.2 工作原理
1. **初始化**:创建一个包含多个桶的数组,每个桶可以存储多个指纹(fingerprint)。
2. **添加元素**:使用两个哈希函数计算元素的两个候选桶,并将元素的指纹存储到其中一个桶中。如果两个桶都满了,则进行“踢出”操作,将原有元素踢出并重新插入。
3. **查询元素**:使用相同的两个哈希函数计算元素的两个候选桶,并检查这两个桶中是否包含该元素的指纹。
4. **删除元素**:通过查找元素的指纹并将其从桶中删除。
#### 2.3 底层剖析
布谷鸟过滤器的核心在于**布谷鸟哈希**和**指纹存储**。以下是其底层实现的关键点:
- **布谷鸟哈希**:布谷鸟过滤器使用两个哈希函数 h1 和 h2 来计算元素的候选桶。具体来说,给定一个元素 x,它的两个候选桶分别为 h1(x) 和 h2(x)。如果其中一个桶有空位,则将元素的指纹存储到该桶中;如果两个桶都满了,则进行“踢出”操作,将原有元素踢出并重新插入。
- **指纹**:指纹是元素的哈希值的一部分,通常较短(例如 8 位)。指纹的唯一性决定了误判率。布谷鸟过滤器通过存储指纹而不是完整的元素来节省空间。
- **误判率**:布谷鸟过滤器的误判率取决于指纹的长度和桶的大小。指纹越长,误判率越低,但空间占用越大。
#### 2.4 优缺点
**优点**:
- **支持删除操作**:布谷鸟过滤器支持删除操作,且不会影响其他元素的判断。
- **空间效率高**:与布隆过滤器相比,布谷鸟过滤器在相同误判率下,空间利用率更高。
- **查询速度快**:查询时间复杂度为 O(1)。
**缺点**:
- **实现复杂**:布谷鸟过滤器的实现比布隆过滤器复杂,尤其是在处理哈希冲突时。
- **插入性能可能下降**:在高负载情况下,插入操作可能会因为频繁的“踢出”操作而性能下降。
#### 2.5 应用场景
- **缓存系统**:与布隆过滤器类似,但支持删除操作,适用于需要动态更新缓存的场景。
- **数据库查询优化**:支持删除操作,适用于需要频繁更新数据的场景。
- **分布式系统**:用于快速判断数据是否在分布式系统中存在。
#### 2.6 Spring Boot 实现示例
以下是一个基于 Spring Boot 的布谷鸟过滤器实现示例:
##### 2.6.1 添加依赖
在 `pom.xml` 中添加 Caffeine 依赖:
```xml
com.github.ben-manes.caffeine
caffeine
3.1.8
```
##### 2.6.2 实现布谷鸟过滤器
```java
import com.github.benmanes.caffeine.cache.BloomFilter;
import com.github.benmanes.caffeine.cache.Caffeine;
import org.springframework.stereotype.Service;
@Service
public class CuckooFilterService {
// 初始化布谷鸟过滤器,预计插入 1000 个元素,误判率为 0.01
private BloomFilter cuckooFilter = Caffeine.newBuilder()
.maximumSize(1000)
.buildFilter();
/**
* 添加元素到布谷鸟过滤器
*/
public void add(String element) {
cuckooFilter.put(element);
}
/**
* 判断元素是否可能存在
*/
public boolean mightContain(String element) {
return cuckooFilter.mightContain(element);
}
/**
* 删除元素(布谷鸟过滤器不支持直接删除,可以通过重建过滤器实现)
*/
public void clear() {
cuckooFilter = Caffeine.newBuilder()
.maximumSize(1000)
.buildFilter();
}
}
```
##### 2.6.3 测试布谷鸟过滤器
```java
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/cuckoo")
public class CuckooFilterController {
@Autowired
private CuckooFilterService cuckooFilterService;
@PostMapping("/add")
public String addElement(@RequestParam String element) {
cuckooFilterService.add(element);
return "Added: " + element;
}
@GetMapping("/check")
public String checkElement(@RequestParam String element) {
boolean exists = cuckooFilterService.mightContain(element);
return "Element " + element + " might exist: " + exists;
}
@DeleteMapping("/clear")
public String clearFilter() {
cuckooFilterService.clear();
return "Filter cleared";
}
}
```
##### 2.6.4 运行测试
启动 Spring Boot 项目后,访问以下 URL 进行测试:
- 添加元素:`http://localhost:8080/cuckoo/add?element=test`
- 检查元素:`http://localhost:8080/cuckoo/check?element=test`
- 清空过滤器:`http://localhost:8080/cuckoo/clear`
* * *
### 三、布隆过滤器 vs 布谷鸟过滤器
| 特性 | 布隆过滤器 | 布谷鸟过滤器 |
| --- | --- | --- |
| **空间效率** | 高 | 更高 |
| **查询速度** | O(k) | O(1) |
| **误判率** | 可控制 | 可控制 |
| **删除操作** | 不支持 | 支持 |
| **实现复杂度** | 简单 | 复杂 |
| **插入性能** | 稳定 | 高负载时可能下降 |
* * *
### 四、总结
布隆过滤器和布谷鸟过滤器都是高效的概率型数据结构,适用于需要快速判断元素是否属于某个集合的场景。布隆过滤器实现简单,空间效率高,但不支持删除操作;布谷鸟过滤器在支持删除操作的同时,进一步提高了空间效率,但实现复杂度较高。
在实际应用中,可以根据具体需求选择合适的过滤器。如果不需要删除操作,布隆过滤器是一个简单高效的选择;如果需要支持删除操作,布谷鸟过滤器则更为合适。
本文来自投稿,不代表本站立场,如若转载,请注明出处:http//www.knowhub.vip/share/2/274
- 热门的技术博文分享
- 1 . ESP实现Web服务器
- 2 . 从零到一:打造高效的金仓社区 API 集成到 MCP 服务方案
- 3 . 使用C#构建一个同时问多个LLM并总结的小工具
- 4 . .NET 原生驾驭 AI 新基建实战系列Milvus ── 大规模 AI 应用的向量数据库首选
- 5 . 在Avalonia/C#中使用依赖注入过程记录
- 6 . [设计模式/Java] 设计模式之工厂方法模式
- 7 . 5. RabbitMQ 消息队列中 Exchanges(交换机) 的详细说明
- 8 . SQL 中的各种连接 JOIN 的区别总结!
- 9 . JavaScript 中防抖和节流的多种实现方式及应用场景
- 10 . SaltStack 远程命令执行中文乱码问题
- 11 . 推荐10个 DeepSeek 神级提示词,建议搜藏起来使用
- 12 . C#基础:枚举、数组、类型、函数等解析
- 13 . VMware平台的Ubuntu部署完全分布式Hadoop环境
- 14 . C# 多项目打包时如何将项目引用转为包依赖
- 15 . Chrome 135 版本开发者工具(DevTools)更新内容
- 16 . 从零创建npm依赖,只需执行一条命令
- 17 . 关于 Newtonsoft.Json 和 System.Text.Json 混用导致的的序列化不识别的问题
- 18 . 大模型微调实战之训练数据集准备的艺术与科学
- 19 . Windows快速安装MongoDB之Mongo实战
- 20 . 探索 C# 14 新功能:实用特性为编程带来便利
- 相关联分享
- 【快速判断是否存在利器】布隆过滤器和布谷鸟过滤器