4个爬虫神器,三分钟搞定数据采集
笔记哥 /
04-15 /
32点赞 /
0评论 /
915阅读
在信息爆炸的时代,数据就是财富。无论是市场调研、竞品分析,还是个人兴趣研究,快速且准确地获取所需数据至关重要。今天,就为大家揭秘 4 个功能实用、强大的爬虫神器,有适合零代码无编码基础的,也有需通过编程进行深度定制的,让你轻松实现三分钟搞定数据采集!
## 1、神器一:八爪鱼采集器
首先登场的是八爪鱼采集器,堪称简单易用的全能选手,即使你是编程小白,也能迅速上手。
这款软件以其直观的图形化界面、可视化的流程设计和强大的自定义功能著称。无需编程基础,只需点点鼠标,设置几个规则,就能轻松抓取网页上的各类数据。无论是电商商品信息、社交媒体帖子还是新闻网站的文章内容或是动态加载的数据,它都能轻松应对,有免费版也有收费版。根据需求选择即可。
**官网:** ``
**上手难度:** 🌟
**适用场景:** 电商价格监控、新闻聚合、社交媒体数据抓取等。
## 2、神器二:Web Scraper
`Web Scraper` 是一款基于浏览器的零代码爬虫工具,支持动态页面抓取和智能元素定位。专门用于数据采集,在浏览器上直接抓网页,通过模拟人类浏览行为实现网页数据自动化采集。其核心功能包括智能元素选择器、动态页面解析和多层级数据抓取,支持文本、图片、链接等多种数据类型。
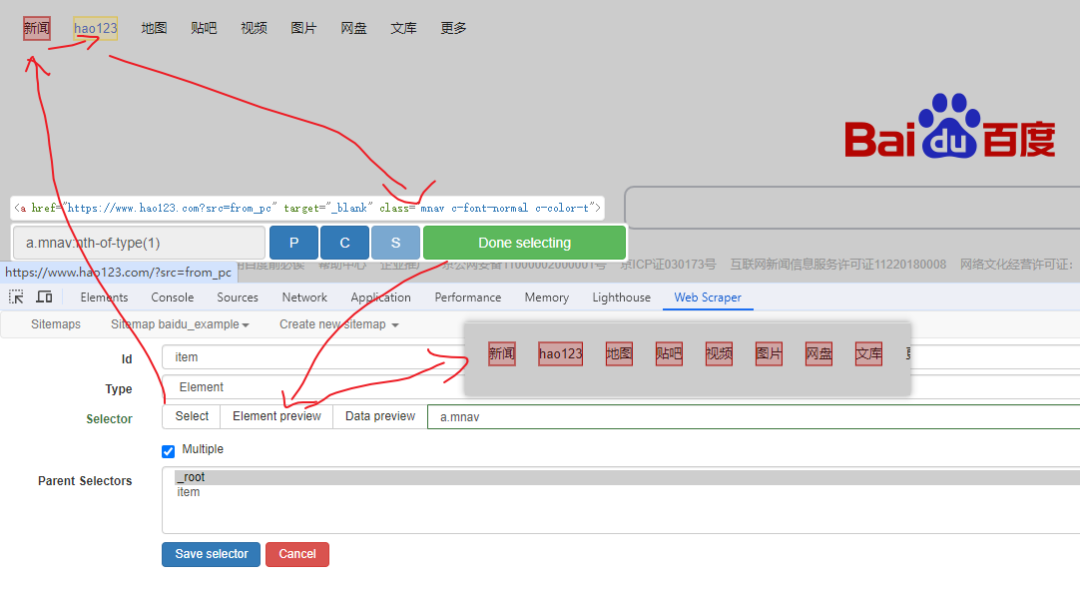
`Web Scraper`插件支持翻页、登录认证和简单数据清洗,而且支持多种数据类型采集,并可将采集到的数据导出为Excel、CSV等多种格式。
**官网:** ``
**上手难度:** 🌟
## 3、神器三:Scrapy
`Scrapy` 是一款基于 Python 的开源爬虫框架,适合有一定编程基础的专业开发者。它具有高度的灵活性和可扩展性,开发者可以根据项目需求,自由定制爬虫功能。且Scrapy以其高效的异步请求、强大的扩展性和丰富的中间件而闻名。对于有一定编程基础的朋友来说,Scrapy是打造定制化爬虫的不二之选。
**安装:**
```csharp
pip install scrapy
```
**上手难度:** 🌟🌟🌟
**适用场景:** 大规模网站爬取、数据清洗与存储、复杂逻辑处理、自由定制爬虫功能。
**示例:** 下面以Scrapy爬取豆瓣电影为例:
1、首先,创建一个新的Scrapy项目:
```csharp
scrapy startproject douban_movie
cd douban_movie
```
1. 新建items.py,定义我们要抓取的数据结构:
```csharp
import scrapy
class DoubanMovieItem(scrapy.Item):
# 电影排名
ranking = scrapy.Field()
# 电影名称
title = scrapy.Field()
# 电影评分
score = scrapy.Field()
# 评论人数
comment_num = scrapy.Field()
# 电影简介
quote = scrapy.Field()
# 电影详情页链接
detail_url = scrapy.Field()
# 电影封面图片链接
cover_url = scrapy.Field()
```
1. 创建Spider,在spiders目录下创建douban\_spider.py:
```csharp
import scrapy
from douban_movie.items import DoubanMovieItem
from scrapy.http import Request
class DoubanSpider(scrapy.Spider):
name = "douban"
allowed_domains = ["movie.douban.com"]
start_urls = ["https://movie.douban.com/top250"]
# 设置自定义请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
def start_requests(self):
for url in self.start_urls:
yield Request(url, headers=self.headers, callback=self.parse)
def parse(self, response):
item = DoubanMovieItem()
movies = response.xpath('//ol[@class="grid_view"]/li')
for movie in movies:
item['ranking'] = movie.xpath(
'.//div[@class="pic"]/em/text()').extract()[0]
item['title'] = movie.xpath(
'.//div[@class="hd"]/a/span[1]/text()').extract()[0]
item['score'] = movie.xpath(
'.//div[@class="star"]/span[@class="rating_num"]/text()').extract()[0]
item['comment_num'] = movie.xpath(
'.//div[@class="star"]/span[4]/text()').re(r'(\d+)')[0]
item['quote'] = movie.xpath(
'.//p[@class="quote"]/span/text()').extract()[0] if movie.xpath('.//p[@class="quote"]/span/text()') else ''
item['detail_url'] = movie.xpath(
'.//div[@class="hd"]/a/@href').extract()[0]
item['cover_url'] = movie.xpath(
'.//div[@class="pic"]/a/img/@src').extract()[0]
yield item
# 处理下一页
next_url = response.xpath('//span[@class="next"]/a/@href').extract()
if next_url:
next_url = 'https://movie.douban.com/top250' + next_url[0]
yield Request(next_url, headers=self.headers, callback=self.parse)
```
1. 在settings.py中添加以下配置:
```csharp
# 遵守robots.txt规则
ROBOTSTXT_OBEY = False
# 设置下载延迟
DOWNLOAD_DELAY = 2
# 启用Pipeline
ITEM_PIPELINES = {
'douban_movie.pipelines.DoubanMoviePipeline': 300,
}
# 设置请求头
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
```
1. 创建Pipeline,创建数据处理管道:
```csharp
import json
import pymongo
from scrapy.exceptions import DropItem
class DoubanMoviePipeline(object):
def __init__(self):
# 可选:保存到JSON文件
self.file = open('douban_movie.json', 'w', encoding='utf-8')
# 可选:连接MongoDB
# self.client = pymongo.MongoClient('localhost', 27017)
# self.db = self.client['douban']
# self.collection = self.db['movies']
def process_item(self, item, spider):
# 检查必要字段是否存在
if not all(item.get(field) for field in ['title', 'score', 'detail_url']):
raise DropItem("Missing required fields in %s" % item)
# 保存到JSON文件
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(line)
# 保存到MongoDB
# self.collection.insert_one(dict(item))
return item
def close_spider(self, spider):
self.file.close()
# self.client.close()
```
1. 运行以下命令启动爬虫:
```csharp
scrapy crawl douban -o movies.csv
或者将结果保存为JSON格式:
scrapy crawl douban -o movies.json
```
可以看出,Scrapy虽灵活,但使用起来还是有点难度的,如果没些编码基础的同学,不太好驾驭。
## 4、神器四:Beautiful Soup
`Beautiful Soup` 也是一个 Python 库,专注于从HTML 和 XML 文件中提取数据。相比Scrapy它简单易用,能够快速提取网页中的特定信息,是网页解析的得力助手。
**上手难度:** 🌟🌟
**适用场景:** 小规模数据抓取、网页内容提取、数据清洗。
**使用示例:**
1、安装 Beautiful Soup
```csharp
pip install beautifulsoup4
```
如果需要使用其他解析器,还需要安装:
```csharp
pip install lxml # 推荐使用,速度快
pip install html5lib # 容错性好
```
2、解析 HTML 文档
```csharp
from bs4 import BeautifulSoup
import requests
# 获取网页内容
url = "https://example.com"
response = requests.get(url)
html_content = response.text
# 创建 BeautifulSoup 对象
soup = BeautifulSoup(html_content, 'lxml') # 使用 lxml 解析器
# 获取第一个 标签
title_tag = soup.title
print(title_tag) # <title>Example Domain
print(title_tag.string) # Example Domain
# 获取第一个
标签 first_p = soup.p print(first_p.get_text()) # 获取标签内的文本内容 ``` ## 最后 选择一款最适合你的软件,动手实践,让数据成为你探索世界、创造价值的强大武器。 当然,记得,合法合规是使用爬虫的前提,尊重网站的使用条款,保护数据隐私,很重要!
本文来自投稿,不代表本站立场,如若转载,请注明出处:http//www.knowhub.vip/share/2/2287
- 热门的技术博文分享
- 1 . ESP实现Web服务器
- 2 . 从零到一:打造高效的金仓社区 API 集成到 MCP 服务方案
- 3 . 使用C#构建一个同时问多个LLM并总结的小工具
- 4 . .NET 原生驾驭 AI 新基建实战系列Milvus ── 大规模 AI 应用的向量数据库首选
- 5 . 在Avalonia/C#中使用依赖注入过程记录
- 6 . [设计模式/Java] 设计模式之工厂方法模式
- 7 . 5. RabbitMQ 消息队列中 Exchanges(交换机) 的详细说明
- 8 . SQL 中的各种连接 JOIN 的区别总结!
- 9 . JavaScript 中防抖和节流的多种实现方式及应用场景
- 10 . SaltStack 远程命令执行中文乱码问题
- 11 . 推荐10个 DeepSeek 神级提示词,建议搜藏起来使用
- 12 . C#基础:枚举、数组、类型、函数等解析
- 13 . VMware平台的Ubuntu部署完全分布式Hadoop环境
- 14 . C# 多项目打包时如何将项目引用转为包依赖
- 15 . Chrome 135 版本开发者工具(DevTools)更新内容
- 16 . 从零创建npm依赖,只需执行一条命令
- 17 . 关于 Newtonsoft.Json 和 System.Text.Json 混用导致的的序列化不识别的问题
- 18 . 大模型微调实战之训练数据集准备的艺术与科学
- 19 . Windows快速安装MongoDB之Mongo实战
- 20 . 探索 C# 14 新功能:实用特性为编程带来便利
- 相关联分享