Chroma:.NET开发者构建智能应用的向量数据库利器
笔记哥 /
04-15 /
28点赞 /
0评论 /
127阅读
在人工智能`AI`和机器学习`ML`迅猛发展的今天,数据的存储和检索需求发生了巨大变化。传统的数据库擅长处理结构化数据,但在面对高维向量数据时往往力不从心。向量数据库作为一种新兴技术,专为`AI`应用设计,能够高效地存储和查询高维向量数据,成为现代智能应用的核心组件之一。
本文将详细介绍`Chroma`这一开源向量数据库,探讨其在`.NET`生态系统中的应用,包括安装步骤、代码示例以及实际应用场景,帮助`.NET`开发者充分利用这一工具构建智能应用。
## 一、Chroma简介
`Chroma`是一个开源的、AI原生的向量数据库,旨在为开发者提供简单、高效的方式来管理和查询高维向量数据。它特别适用于需要嵌入`embeddings`、向量搜索和多模态数据处理的`AI`应用场景。`Chroma`的设计目标是降低开发复杂性,同时保证高性能和灵活性,使其成为构建智能应用的理想选择。
### 1.1 Chroma 的特点
`Chroma`具备以下几个显著特点,使其在向量数据库领域脱颖而出:
- **开源和AI原生**:`Chroma`是完全开源的,遵循`Apache 2.0`许可,开发者可以自由使用、修改和分发。它专为AI应用设计,与现代机器学习工作流无缝衔接。
- **功能丰富**:支持向量搜索、文档存储、全文搜索、元数据过滤和多模态检索等多种功能,满足多样化的应用需求。
- **易于使用**:提供简洁的`RESTFul API`接口,开发者无需深入了解底层实现即可快速上手。
- **高性能**:针对高维向量数据的存储和检索进行了优化,支持大规模数据集的快速查询。
- **与.NET集成**:通过官方提供的`C#`客户端`SDK`,`Chroma`可以轻松集成到`.NET`应用中,为`.NET`开发者提供了强大的支持。
- **持久化** Chroma支持将数据持久化到磁盘,以便在重启后保留数据。用户可以选择将数据存储在内存中或持久化到磁盘。
- **可扩展性** Chroma设计为可扩展的系统,可以处理大规模的嵌入向量和文档集合。用户可以根据需要扩展Chroma的容量和性能。
### 1.2 Chroma 的核心概念
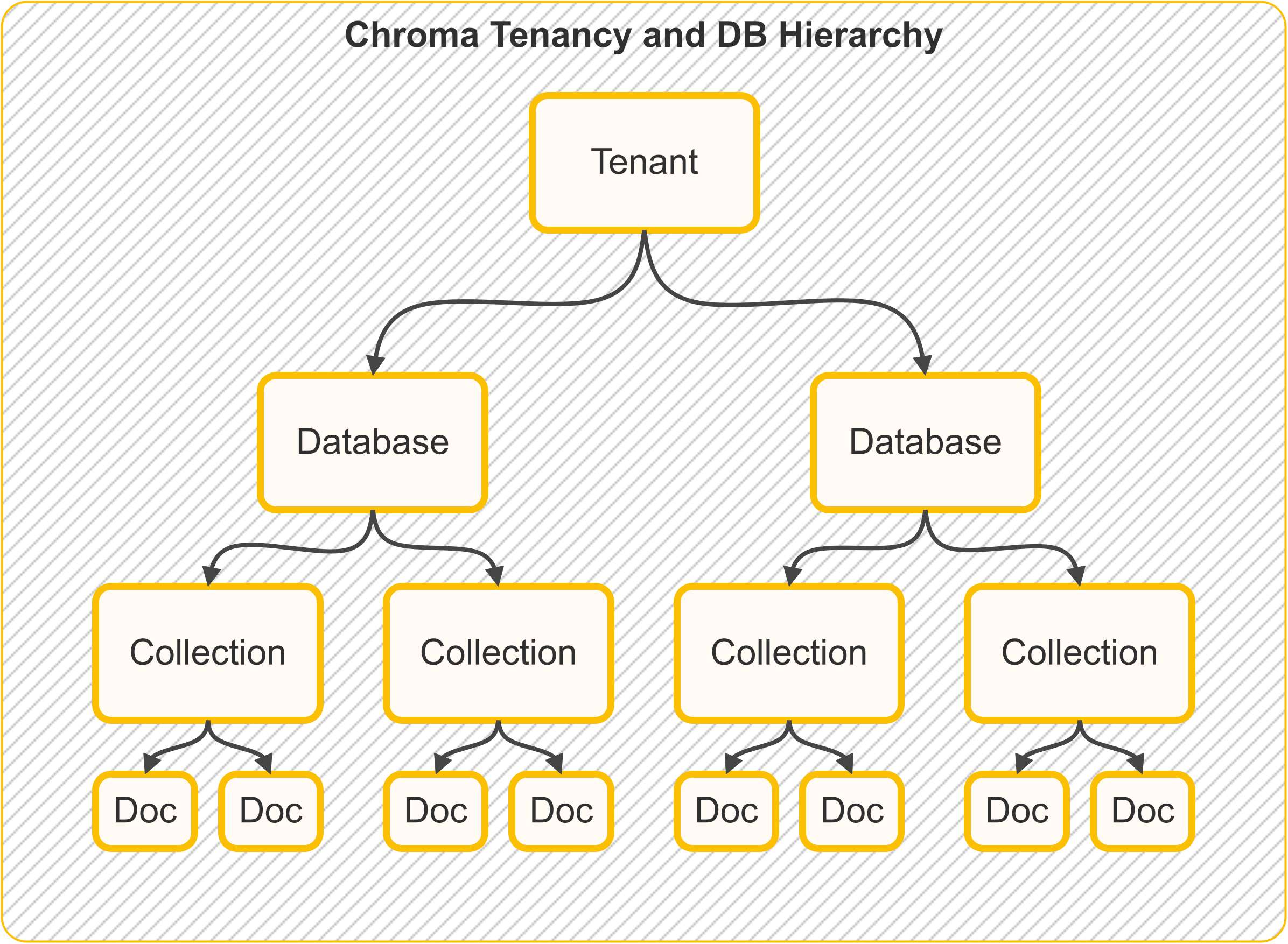
Chroma的核心概念主要围绕着高效存储、查询和管理嵌入向量(embeddings)以及相关数据。以下是Chroma的关键概念:
- **租户(Tenant)**: Tenant 是一个逻辑分组,通常代表一个组织、用户或客户,用于组织一组数据库。
- **数据库(Database)**: Database 是一个逻辑分组,通常代表一个应用程序或项目,用于组织一组 Collection(集合)。
- **集合(Collection)**: 集合是Chroma中存储嵌入向量、文档、ID和元数据的基本单元。每个集合通常代表一个特定的数据集或应用场景,类似于数据库中的“表”。
> ❝
>
> Database 与 Collection 的关系:
>
> - **Collection(集合)** 是 ChromaDB 中存储实际数据的基本单元,比如嵌入向量、文> 档、ID 和元数据。Collection 隶属于某个 Database,而 Database 又隶属于某个 Ten> ant,形成了一个层次化的数据组织结构。
>
>
- **嵌入向量(Embeddings)**: 嵌入向量是文本、图像或其他数据的向量表示,用于捕捉其语义或特征。Chroma允许用户将这些嵌入向量与相应的文档和元数据一起存储。
- **文档(Documents)**: 文档是与嵌入向量相关联的原始数据,例如文本、图像或其他内容。文档可以与嵌入向量一起存储,以便在查询时提供上下文。
- **ID**: 每个嵌入向量、文档和元数据都与一个唯一的ID相关联,用于标识和检索特定的条目。
- **元数据(Metadata)**: 元数据是与嵌入向量和文档相关的额外信息,例如作者、日期、类别等。元数据可以用于过滤和查询数据。
- **嵌入函数(Embedding Functions)**: Chroma支持使用嵌入函数来自动生成嵌入向量。用户可以指定嵌入函数,以便在添加文档时自动生成嵌入向量。
这些核心概念共同构成了Chroma的功能和特性,使其成为一个高效的嵌入向量存储与查询工具。
### 1.3 Chroma 的工作原理
`Chroma`的核心功能基于高效的向量索引和搜索技术。它使用诸如`HNSW(Hierarchical Navigable Small World)`等先进的索引结构来存储高维向量数据,并支持多种距离度量(如欧几里得距离、余弦相似度)来计算向量之间的相似性。开发者可以将文本、图像或其他数据转换为嵌入向量,存储在`Chroma`中,并通过相似性搜索快速检索相关内容。这种设计特别适合语义搜索、推荐系统等需要理解数据深层含义的场景。
### 1.4 Chroma Embeddings算法简介
Chroma Embeddings算法是一种用于生成文本嵌入向量(text embeddings)的方法,主要在ChromaDB中应用。ChromaDB是一个专门设计用于存储和查询嵌入向量的数据库,支持多种嵌入模型,其中就包括Chroma Embeddings算法。
> ❝
>
> 这种算法的核心目标是将文本转化为高维向量表示,从而捕捉文本的语义信息,并支持诸如相似性搜索、文本分类和聚类等自然语言处理任务。
>
#### 算法原理
Chroma Embeddings算法通常基于**Transformer模型**,尤其是类似于**BERT(Bidirectional Encoder Representations from Transformers)**或其变体的预训练语言模型。BERT通过在大量文本数据上进行无监督学习,能够理解文本的上下文和深层语义。Chroma Embeddings算法利用这一特性,将输入文本转化为固定长度的嵌入向量。这些向量保留了文本的语义信息,使得相似的文本在向量空间中距离较近,而语义不同的文本则距离较远。
其工作流程大致如下:
1. **文本输入**:接收用户提供的文本数据。
2. **嵌入生成**:通过预训练的Transformer模型,将文本转换为嵌入向量。
3. **存储与查询**:在ChromaDB中存储这些向量,并支持基于向量的查询操作。
#### 应用
- **生成嵌入向量**:将文本数据转化为向量表示。
- **存储嵌入**:将生成的向量高效存储在数据库中。
- **相似性搜索**:通过比较向量之间的距离,找到与查询文本最相似的已有文本。
例如,用户可以输入一段查询文本,Chroma Embeddings算法会将其转化为嵌入向量,然后ChromaDB会返回数据库中最相似的文本结果。这种功能在信息检索、推荐系统等领域尤为实用。
#### 优势
Chroma Embeddings算法具有以下优点:
- **语义捕捉能力强**:基于Transformer模型,能够理解文本的深层含义,而不仅仅是表面词汇。
- **灵活性**:ChromaDB支持多种嵌入模型,用户可以根据任务需求选择合适的模型。
- **高效性**:生成的嵌入向量支持快速查询和相似性计算,适用于大规模数据场景。
#### 实现细节
尽管具体实现可能因ChromaDB的版本和配置而有所不同,但Chroma Embeddings算法通常依赖于:
- **预训练模型**:如BERT或其变体,这些模型已在大型语料库上训练完成。
- **微调(可选)**:根据特定任务对模型进行调整,以提升性能。
用户在使用时无需深入了解模型内部细节,只需通过ChromaDB的接口调用算法即可生成和查询嵌入向量。
> ❝
>
> Chroma Embeddings算法是一种基于Transformer模型的文本嵌入生成方法,广泛应用于ChromaDB中。它通过将文本转化为嵌入向量,捕捉深层语义信息,支持高效的存储和查询操作。这种算法在相似性搜索、文本分类等任务中表现出色,是自然语言处理领域的重要工具。
>
## 二、配置 Chroma 开发环境
目前在.NET中,想要完整的使用,还是比较困难的,最大的困难在于**生成嵌入向量**,虽然现在有很多的SDK,但这些这是对Chroma API的封装而已,还远没有达到可以实际应用的地步。
不过,好消息是,.NET官方正在Semantic Kernel中加入对Chroma的完整支持,目前尚不成熟,在这里,我简单的演示一下,大家也不用太深入的看代码,因为现在的代码都处于开发中,很多接口都会变化,而且已经实现的代码也有很多问题,我花了一下午的时间,才把这些问题清除掉,并运行起来。
### 2.1 安装 Chroma 服务
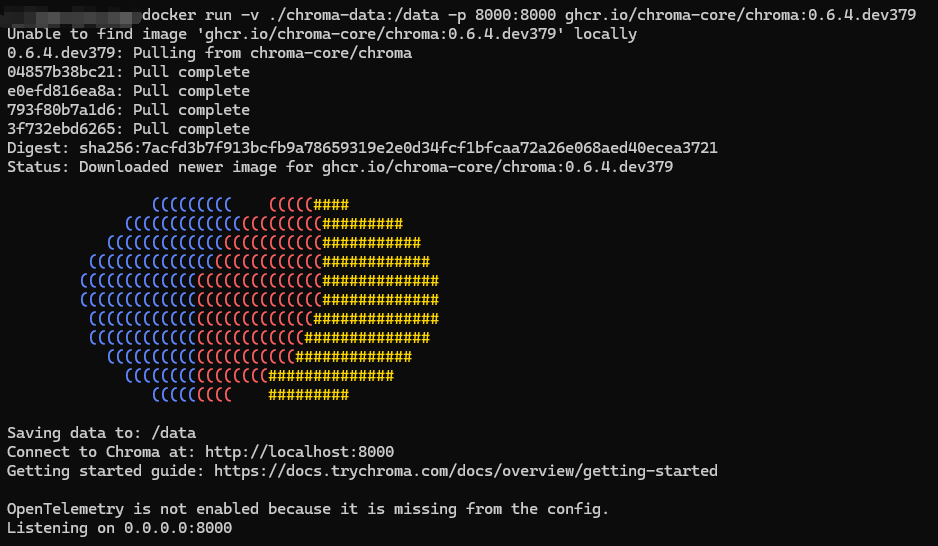
`Chroma`的客户端需要连接到一个运行中的`Chroma`服务器。开发者可以通过以下方式启动 `Chroma`服务:
- **使用 Docker**: 在本地运行以下命令以启动`Chroma`服务:
```csharp
docker run -v ./chroma-data:/data -p 8000:8000 ghcr.io/chroma-core/chroma:0.6.4.dev379
```
- **使用 Python**: 如果你更倾向于直接运行`Chroma`,可以通过`Python`安装并启动:
```csharp
pip install chromadb
chromadb run --host localhost --port 8000
```
完成上述步骤后,`Chroma`服务将在本地运行,`.NET`客户端即可通过配置的`URI`进行连接。
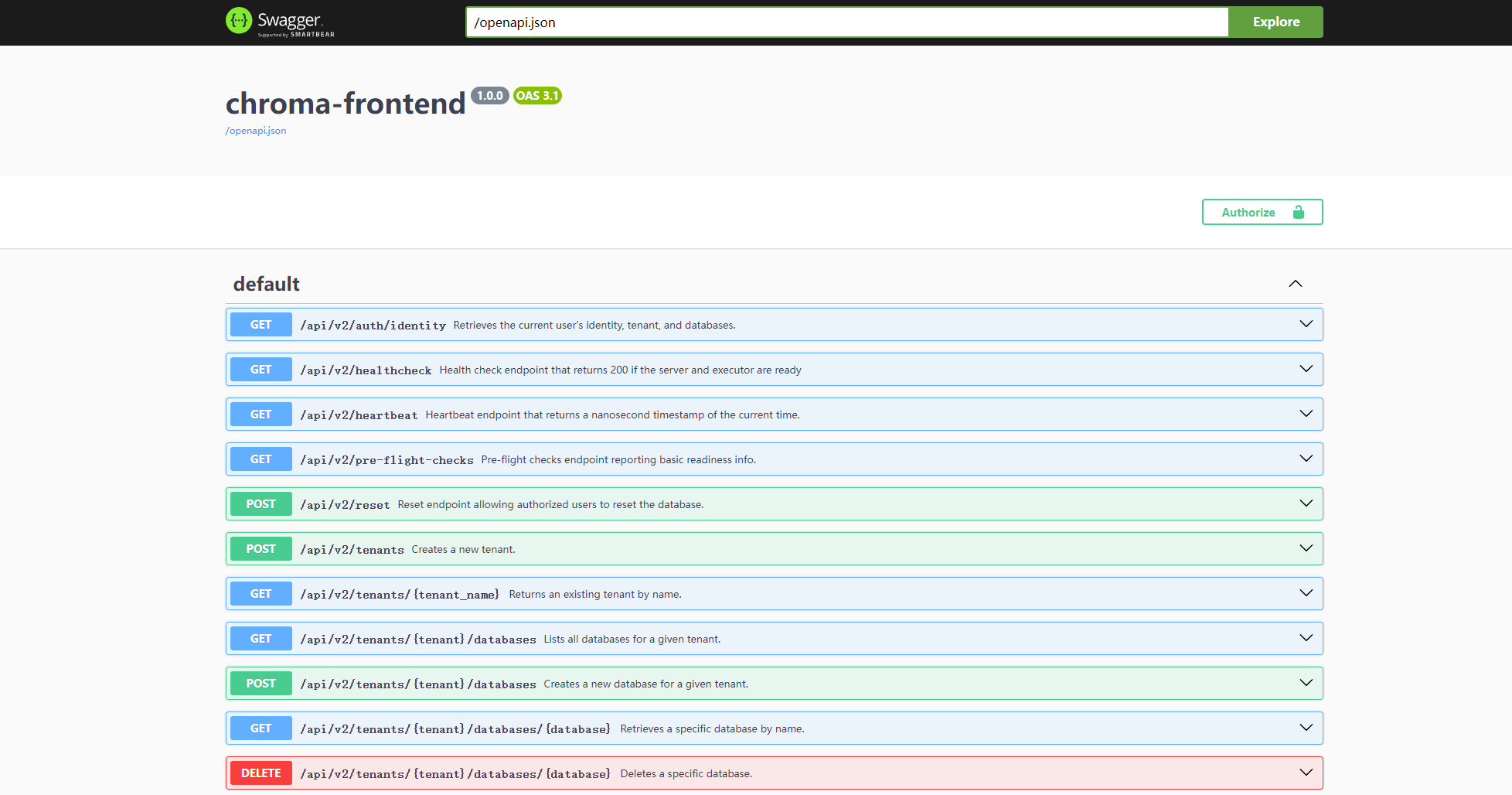
### Chroma 接口文档查看
`接口地址:`
### 2.2 安装Ollama并配置相关模型
- 安装all-minilm用于对话功能
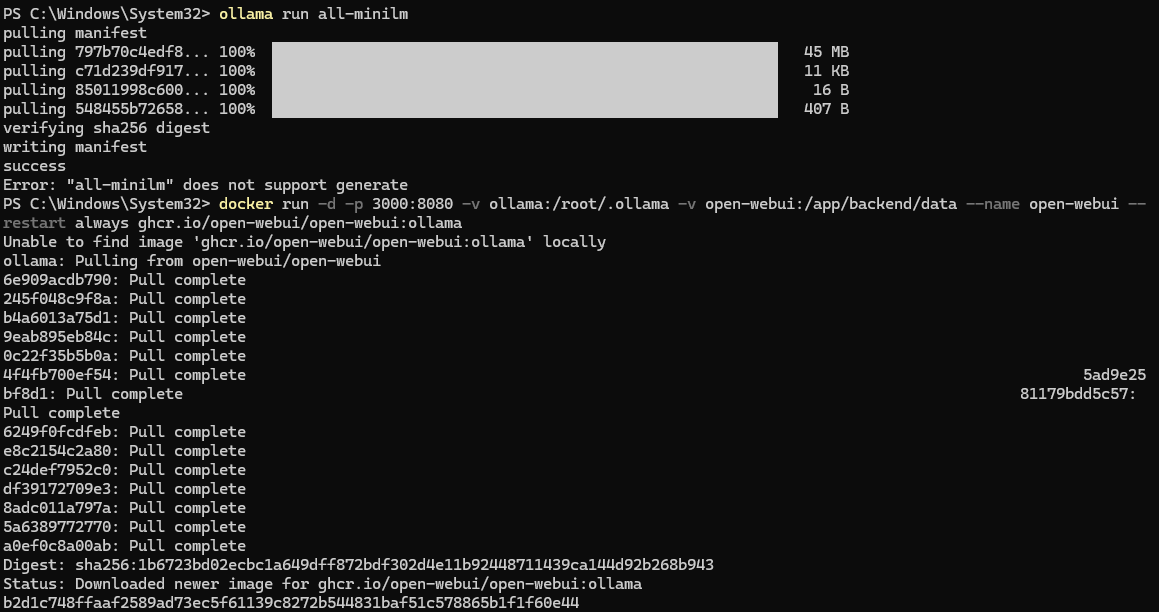
- 安装mxbai-embed-large用于生成嵌入向量

## 三、在.NET 中操作 Chroma
为了帮助开发者更好地理解`Chroma`在`.NET`中的使用方式,以下提供几个实用的代码示例,展示如何创建集合、添加文档、执行查询。
> ❝
>
> 以下代码是使用官方代码库演示,而由于官方代码库尚未稳定,所以只是让大家先看看效果,但是暂时不需要对代码实现有太多的关注,建议把精力多放在 Chroma 的相关知识的学习中,静等微软发布正式版代码库。
>
### 3.1 连接与创建集合
参考代码:
在`Chroma`中,集合`Collection`是存储向量数据的基本单元。以下代码演示如何创建一个名为`products`的集合:
```csharp
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Connectors.Chroma;
using Microsoft.SemanticKernel.Connectors.Ollama;
using Microsoft.SemanticKernel.Embeddings;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Plugins.Memory;
using OllamaSharp;
#pragma warning disable SKEXP0070
#pragma warning disable SKEXP0050
#pragma warning disable SKEXP0001
#pragma warning disable SKEXP0020
const string MemoryCollectionName = "my-memory-collection";
IMemoryStore memoryStore = new ChromaMemoryStore("http://localhost:8000/api/v2/tenants/tenant_test/databases/db_test/");
await memoryStore.CreateCollectionAsync(MemoryCollectionName);
var kernel = Kernel.CreateBuilder()
.AddOllamaChatCompletion("phi3", new Uri("http://localhost:11434"))
.AddOllamaTextEmbeddingGeneration("mxbai-embed-large", new Uri("http://localhost:11434"))
.Build();
// Create an embedding generator to use for semantic memory.
// The combination of the text embedding generator and the memory store makes up the 'SemanticTextMemory' object used to
// store and retrieve memories.
SemanticTextMemory textMemory = new(memoryStore, new OllamaApiClient("http://localhost:11434", "mxbai-embed-large").AsTextEmbeddingGenerationService());
```
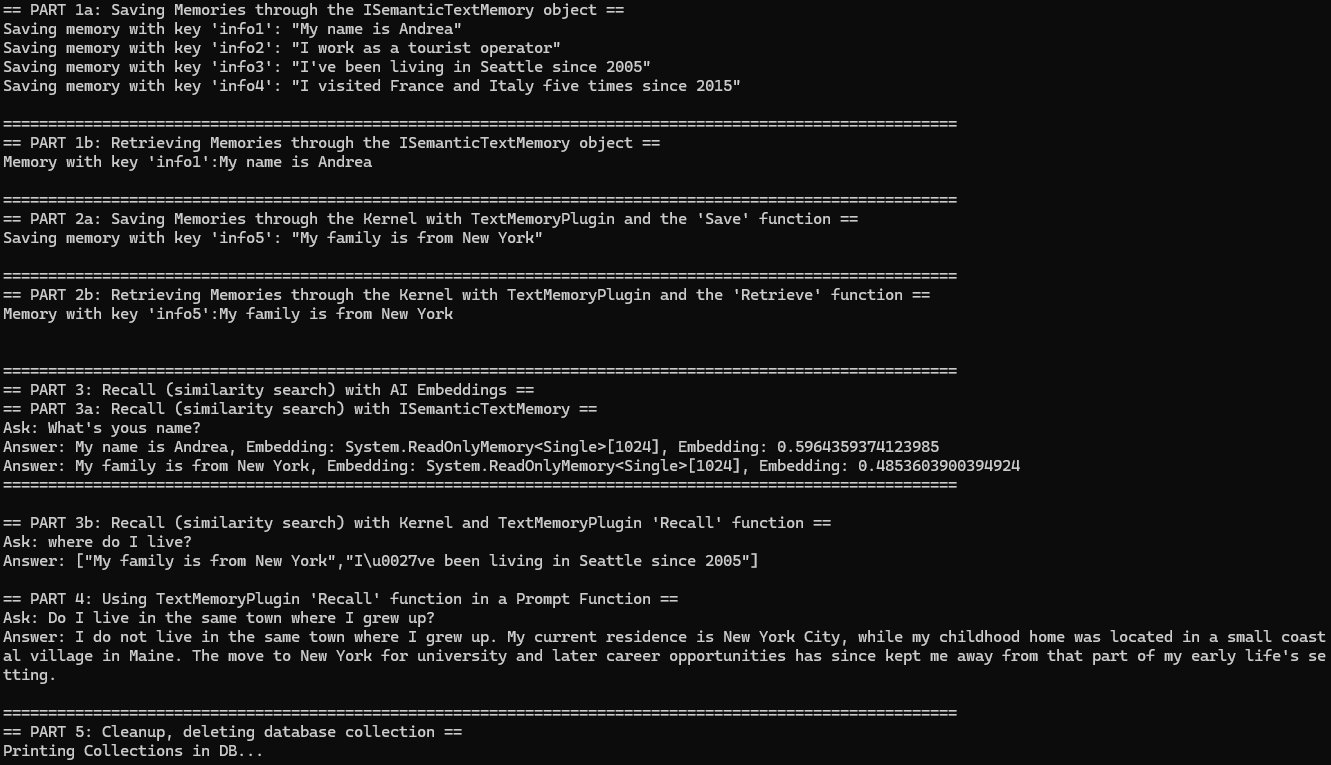
### 3.2 组建 SemanticTextMemory 对象并添加文档信息
```csharp
SemanticTextMemory textMemory = new(memoryStore, new OllamaApiClient("http://localhost:11434", "mxbai-embed-large").AsTextEmbeddingGenerationService());
Console.WriteLine("Saving memory with key 'info1': \"My name is Andrea\"");
await textMemory.SaveInformationAsync(MemoryCollectionName, id: "info1", text: "My name is Andrea");
……
```
如果未提供嵌入,`Chroma`会使用内置的嵌入模型(如 `all-MiniLM-L6-v2`)自动生成向量。
### 3.3 执行向量查询
```csharp
IAsyncEnumerable answers = textMemory.SearchAsync(
collection: MemoryCollectionName,
query: "What's yous name?",
limit: 2,
minRelevanceScore: 0.4,
withEmbeddings: true);
```
### 3.4 总的运行结果
## 四、Chroma 的实际应用场景
`Chroma`的强大功能使其在`.NET`应用中有着广泛的适用性。以下是几个典型的应用场景:
### 4.1 语义搜索
在企业文档管理系统中,传统的关键字搜索往往无法捕捉用户意图的深层含义。通过将文档转换为嵌入并存储在`Chroma`中,开发者可以实现语义搜索。例如,用户输入“如何提高团队效率”,系统能够返回与团队协作、时间管理相关的文档,而不仅仅是包含关键字的文档。
### 4.2 推荐系统
在电子商务平台中,可以使用`Chroma`存储商品和用户的向量表示。例如,将商品描述和用户浏览历史转换为嵌入,存储在`Chroma`中,通过相似性搜索为用户推荐相关商品。这种方法比传统基于规则的推荐系统更灵活、更智能。
### 4.3 多模态检索
在多媒体应用中,`Chroma`的多模态检索功能尤为强大。例如,可以将图像和文本描述的嵌入存储在同一个集合中,用户上传一张图片后,系统能够返回与之内容相似的图像和相关描述。
### 4.4 问答系统
在客户支持应用中,可以使用`Chroma`存储常见问题及其答案的向量表示。用户输入问题后,系统通过向量搜索返回最匹配的答案,提升响应速度和准确性。
## 五、Chroma 与.NET生态系统的集成
`Chroma`不仅可以通过`C#`客户端直接使用,还能与`.NET`生态系统中的其他组件深度集成,进一步提升开发效率:
- **Semantic Kernel**:这是`Microsoft`推出的一款`AI`开发框架,支持与`Chroma`集成。开发者可以通过`Semantic Kernel`将`Chroma`作为向量存储,用于实现复杂的`AI`工作流。
- **Microsoft.SemanticKernel.Connectors.Chroma**:通过此扩展,`Chroma`可以与.NET的依赖注入机制无缝协作,提供标准化的向量数据访问接口,简化应用程序架构。
- **Microsoft.Extensions.VectorData**:库的主要作用是为 .NET 应用程序提供与向量存储交互的统一抽象层。向量存储用于存储和管理高维嵌入向量,广泛应用于语义搜索和生成式 AI 等场景。
这些集成使得`Chroma`能够融入现有的`.NET`项目,与其他工具协同工作,加速智能应用的开发。
> ❝
>
> **目前这些工作正在进行中,请大家静等.NET正式版的发布。**
>
## 六、性能优化技巧
为了在`.NET`应用中充分发挥`Chroma`的性能,开发者可以采用以下优化策略:
- **索引调优**:调整 HNSW 索引的参数,例如`efConstruction`(构建时的搜索深度)和 `M`(邻居数量),在搜索速度和精度之间找到平衡。
- **数据分片**:对于超大规模数据集,可以将数据分散到多个集合或实例中,通过并行查询提高吞吐量。
- **缓存策略**:对于频繁查询的热点数据,可以在`.NET`应用层添加缓存,减少对`Chroma`的直接访问。
## 七、Chroma 的未来发展展望
随着`AI`技术的不断进步,向量数据库在软件开发中的重要性日益凸显。作为一款开源项目,`Chroma`在未来有很大的发展潜力,尤其是在`.NET`生态系统中:
- **功能扩展**:支持更多类型的索引和距离度量,满足不同场景的需求。
- **性能提升**:优化底层算法,进一步提高大规模数据集的处理能力。
- **云服务支持**:推出官方托管版本,降低部署和维护的门槛,为`.NET`开发者提供更便捷的接入方式。
- **与.NET深度融合**:提供更多针对`.NET`平台的专用工具和文档,提升开发效率。
## 八、总结
`Chroma`作为一个开源、易用且功能强大的向量数据库,为`.NET`开发者提供了一款构建智能应用的利器。通过简单的安装步骤和直观的`API`,开发者可以将`Chroma`集成到.NET项目中,实现高效的向量数据管理。无论是语义搜索、推荐系统还是多模态检索,`Chroma`都能为应用注入智能化能力。随着技术的不断演进,`Chroma`在`.NET`生态系统中的应用前景将更加广阔,为开发者开启更多创新可能。
本文来自投稿,不代表本站立场,如若转载,请注明出处:http//www.knowhub.vip/share/2/2273
- 热门的技术博文分享
- 1 . ESP实现Web服务器
- 2 . 从零到一:打造高效的金仓社区 API 集成到 MCP 服务方案
- 3 . 使用C#构建一个同时问多个LLM并总结的小工具
- 4 . .NET 原生驾驭 AI 新基建实战系列Milvus ── 大规模 AI 应用的向量数据库首选
- 5 . 在Avalonia/C#中使用依赖注入过程记录
- 6 . [设计模式/Java] 设计模式之工厂方法模式
- 7 . 5. RabbitMQ 消息队列中 Exchanges(交换机) 的详细说明
- 8 . SQL 中的各种连接 JOIN 的区别总结!
- 9 . JavaScript 中防抖和节流的多种实现方式及应用场景
- 10 . SaltStack 远程命令执行中文乱码问题
- 11 . 推荐10个 DeepSeek 神级提示词,建议搜藏起来使用
- 12 . C#基础:枚举、数组、类型、函数等解析
- 13 . VMware平台的Ubuntu部署完全分布式Hadoop环境
- 14 . C# 多项目打包时如何将项目引用转为包依赖
- 15 . Chrome 135 版本开发者工具(DevTools)更新内容
- 16 . 从零创建npm依赖,只需执行一条命令
- 17 . 关于 Newtonsoft.Json 和 System.Text.Json 混用导致的的序列化不识别的问题
- 18 . 大模型微调实战之训练数据集准备的艺术与科学
- 19 . Windows快速安装MongoDB之Mongo实战
- 20 . 探索 C# 14 新功能:实用特性为编程带来便利