MongoDB集群故障选举全面解析
笔记哥 /
04-12 /
9点赞 /
0评论 /
283阅读
转载请注明出处:
### 一、MongoDB集群基础架构
#### 1. 副本集(Replica Set)核心原理
- **节点角色**:
- **Primary**:唯一可写节点,处理所有写操作和默认读请求
- **Secondary**:异步复制Primary数据,可配置为只读节点
- **Arbiter**(可选):不存储数据,仅参与投票
- **选举机制**:
- 基于Raft协议,需**多数节点存活**(N/2 +1)才能选出Primary
- 每个节点有1票,Arbiter无数据但有投票权
- **数据同步**:
- 通过Oplog(操作日志)实现异步复制
- 写操作需满足`writeConcern`级别才返回成功
#### 2. 三节点典型部署
```csharp
Node1: Primary (投票权=1)
Node2: Secondary (投票权=1)
Node3: Secondary/Arbiter (投票权=1)
多数票数(majority)=2
```
### 二、单节点故障场景分析
#### 1.集群状态变化:
1. **剩余节点**:2个节点存活(1主1从或2从)。
2. **选举能力**:
- 三节点集群的多数(majority)= 2。
- 剩余2个节点仍能形成多数,触发自动选举。
3. **读写能力**:
- 新主节点继续处理**写操作**(需满足`w: majority`)。
- **读操作**可正常进行(从新主或剩余从节点)。
4. **数据安全**:
- 若宕机节点是主节点:已确认的写操作(`w: majority`)不会丢失。
- 若宕机节点是从节点:主节点继续服务,数据同步暂停直至节点恢复。
5. **恢复流程**:
- 自动故障转移(通常30秒内完成)。
- 宕机节点恢复后自动同步增量数据。
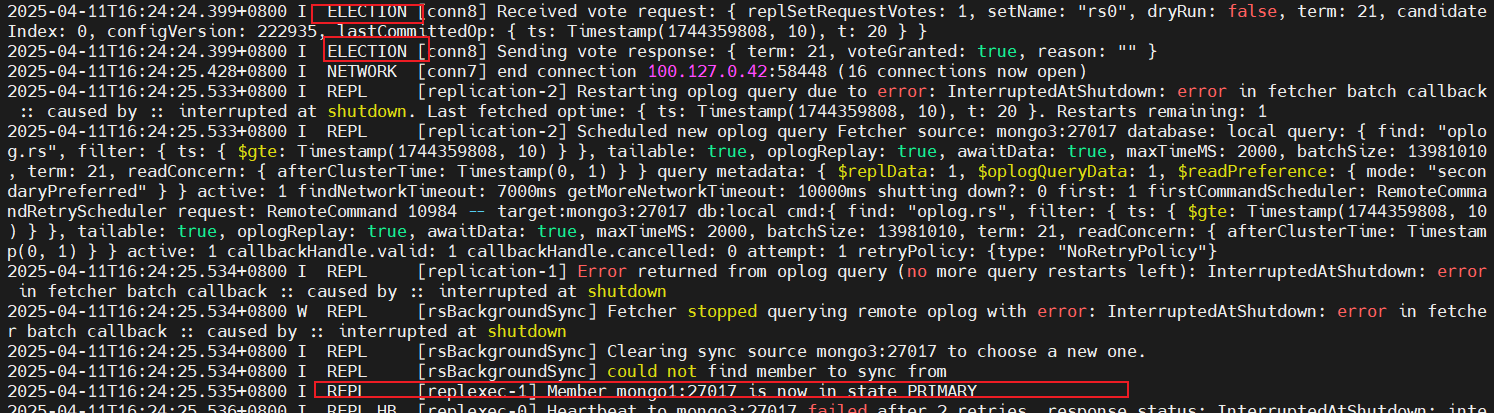
6. **选举日志:**
#### 2. 故障节点类型
| 故障节点 | 集群行为 | 影响范围 |
| --- | --- | --- |
| **Primary** | 剩余2个Secondary触发选举,30秒内选出新Primary | 写入中断<30秒,读操作可继续(若客户端配置`readPreference=secondaryPreferred`) |
| **Secondary** | Primary继续服务,集群标记该节点为`RECOVERING`,恢复后自动同步增量数据 | 无写入中断,读能力降级(少一个读节点) |
#### 3. 数据一致性保障
- **写关注(Write Concern)**:
- 若写操作配置`w: majority`,即使故障节点未确认,数据也不会丢失
- 示例安全写入命令:
```csharp
db.products.insert(
{ item: "card", qty: 15 },
{ writeConcern: { w: "majority", j: true } } // j=true表示持久化到磁盘
)
```
### 三、双节点故障场景分析
#### 1.集群状态变化:
1. **剩余节点**:1个节点存活。
2. **选举能力**:
- 无法满足多数(2/3),**无法选举新主**。
- 原主节点若存活则继续服务,否则集群无主。
3. **读写能力**:
- **写操作**:完全不可用(无主节点)。
- **读操作**:
- 若存活节点是主节点:可读(需客户端直连该节点)。
- 若存活节点是从节点:需设置`readPreference=secondary`。
4. **数据风险**:
- 若原主节点宕机且未持久化最新数据:可能丢失未复制到从节点的写操作。
5. **恢复选项**:
- **自动恢复**:需至少一个节点恢复形成多数。
- **强制恢复**(高风险)
#### 2. 剩余节点状态
| 存活节点 | 集群状态 | 恢复方案 |
| --- | --- | --- |
| 仅Primary | 失去majority,Primary自动降级为Secondary,集群进入**只读模式** | 需手动干预: 1. 重启一个故障节点 2. 或强制重组副本集(`rs.reconfig()`) |
| 仅Secondary | 无Primary,所有写入操作失败,读操作需显式指定`readPreference=secondary` | 需至少恢复1个节点以形成majority |
#### 3. 数据风险窗口
- **潜在丢失数据**:
- 故障前写入未达到`w: majority`的数据可能丢失
- 可通过`oplog`检查未复制的操作:
```csharp
// 在Primary上查看oplog时间窗口
rs.printReplicationInfo()
// 输出示例:oplog first event time -> last event time
```
### 四、核心机制深度解析
#### 1. 选举触发条件
```csharp
A[节点检测Primary无响应] --> B[发起选举请求]
B --> C{获票数≥majority?}
C -->|Yes| D[成为新Primary]
C -->|No| E[等待重试]
```
#### 2. 数据同步流程
1. Primary将写操作记录到`local.oplog.rs`集合
2. Secondary定期拉取(`fetch`) Primary的oplog
3. 应用oplog到本地数据集(异步过程)
#### 3. 故障恢复时序
```csharp
故障检测(10s) → 选举阶段(30s) → 数据同步(依赖网络带宽)
```
### 五、生产环境建议
#### 1. 部署优化
- **跨机房容灾**:
```csharp
机房A: Primary + Secondary
机房B: Secondary
```
- **优先级配置**:
```csharp
// 确保特定节点优先成为Primary
cfg = rs.conf()
cfg.members[0].priority = 2
cfg.members[1].priority = 1
rs.reconfig(cfg)
```
以下是一个集群配置下的 : rs.conf() 配置:
```csharp
rs0:PRIMARY> rs.conf()
{
"_id" : "rs0",
"version" : 222935,
"protocolVersion" : NumberLong(1),
"writeConcernMajorityJournalDefault" : true,
"members" : [
{
"_id" : 0,
"host" : "mongo1:27017",
"arbiterOnly" : false,
"buildIndexes" : true,
"hidden" : false,
"priority" : 2,
"tags" : {
},
"slaveDelay" : NumberLong(0),
"votes" : 1
},
{
"_id" : 1,
"host" : "mongo2:27017",
"arbiterOnly" : false,
"buildIndexes" : true,
"hidden" : false,
"priority" : 2,
"tags" : {
},
"slaveDelay" : NumberLong(0),
"votes" : 1
},
{
"_id" : 2,
"host" : "mongo3:27017",
"arbiterOnly" : false,
"buildIndexes" : true,
"hidden" : false,
"priority" : 2,
"tags" : {
},
"slaveDelay" : NumberLong(0),
"votes" : 1
}
],
"settings" : {
"chainingAllowed" : true,
"heartbeatIntervalMillis" : 2000,
"heartbeatTimeoutSecs" : 10,
"electionTimeoutMillis" : 10000,
"catchUpTimeoutMillis" : -1,
"catchUpTakeoverDelayMillis" : 30000,
"getLastErrorModes" : {
},
"getLastErrorDefaults" : {
"w" : 1,
"wtimeout" : 0
},
"replicaSetId" : ObjectId("67d7f53d2d42a33b47b36ff2")
}
}
rs0:PRIMARY>
```
#### 2. 监控关键指标
- **选举相关**:
```csharp
mongostat -e "repl_set_name,election_date,term" # 监控选举事件
```
- **复制延迟**:
```csharp
db.adminCommand({ replSetGetStatus: 1 }).members.map(m => m.optimeDate)
```
#### 3. 灾难恢复方案
- **强制恢复单节点集群**(极端情况):
```csharp
// 在唯一存活的Secondary上执行
rs.reconfig({_id:"rs0", version:2, members:[{_id:1, host:"single-node:27017"}]}, {force:true})
```
### 六、与传统数据库对比
| 特性 | MongoDB副本集 | MySQL主从复制 |
| --- | --- | --- |
| 故障切换 | 自动选举(秒级) | 需手动提升从库 |
| 数据一致性 | 最终一致性+可调强度 | 依赖半同步复制配置 |
| 读写分离 | 原生支持`readPreference` | 需中间件实现 |
| 网络分区容忍 | 优先保证可用性(AP) | 优先保证一致性(CP) |
本文来自投稿,不代表本站立场,如若转载,请注明出处:http//www.knowhub.vip/share/2/2167
- 热门的技术博文分享
- 1 . ESP实现Web服务器
- 2 . 从零到一:打造高效的金仓社区 API 集成到 MCP 服务方案
- 3 . 使用C#构建一个同时问多个LLM并总结的小工具
- 4 . .NET 原生驾驭 AI 新基建实战系列Milvus ── 大规模 AI 应用的向量数据库首选
- 5 . 在Avalonia/C#中使用依赖注入过程记录
- 6 . [设计模式/Java] 设计模式之工厂方法模式
- 7 . 5. RabbitMQ 消息队列中 Exchanges(交换机) 的详细说明
- 8 . SQL 中的各种连接 JOIN 的区别总结!
- 9 . JavaScript 中防抖和节流的多种实现方式及应用场景
- 10 . SaltStack 远程命令执行中文乱码问题
- 11 . 推荐10个 DeepSeek 神级提示词,建议搜藏起来使用
- 12 . C#基础:枚举、数组、类型、函数等解析
- 13 . VMware平台的Ubuntu部署完全分布式Hadoop环境
- 14 . C# 多项目打包时如何将项目引用转为包依赖
- 15 . Chrome 135 版本开发者工具(DevTools)更新内容
- 16 . 从零创建npm依赖,只需执行一条命令
- 17 . 关于 Newtonsoft.Json 和 System.Text.Json 混用导致的的序列化不识别的问题
- 18 . 大模型微调实战之训练数据集准备的艺术与科学
- 19 . Windows快速安装MongoDB之Mongo实战
- 20 . 探索 C# 14 新功能:实用特性为编程带来便利
- 相关联分享
- MongoDB集群故障选举全面解析