Excel百万数据如何快速导入?
笔记哥 /
04-02 /
45点赞 /
0评论 /
684阅读
## 前言
今天要讨论一个让无数人抓狂的话题:**如何高效导入百万级Excel数据**。
去年有家公司找到我,他们的电商系统遇到一个致命问题:每天需要导入20万条商品数据,但一执行就卡死,最长耗时超过3小时。
更魔幻的是,重启服务器后前功尽弃。
经过半天的源码分析,我们发现了下面这些触目惊心的代码...
## 1 为什么传统导入方案会崩盘?
很多小伙伴在实现Excel导入时,往往直接写出这样的代码:
```java
// 错误示例:逐行读取+逐条插入
public void importExcel(File file) {
List list = ExcelUtils.readAll(file); // 一次加载到内存
for (Product product : list) {
productMapper.insert(product); // 逐行插入
}
}
```
这种写法会引发三大致命问题:
### 1.1 内存熔断:堆区OOM惨案
- **问题**:POI的`UserModel`(如XSSFWorkbook)一次性加载整个Excel到内存
- **实验**:一个50MB的Excel(约20万行)直接耗尽默认的1GB堆内存
- **症状**:频繁Full GC ➔ CPU飙升 ➔ 服务无响应
### 1.2 同步阻塞:用户等到崩溃
- **过程**:用户上传文件 → 同步等待所有数据处理完毕 → 返回结果
- **风险**:连接超时(HTTP默认30秒断开)→ 任务丢失
### 1.3 效率黑洞:逐条操作事务
- **实测数据**:MySQL单线程逐条插入≈200条/秒 → 处理20万行≈16分钟
- **幕后黑手**:每次insert都涉及事务提交、索引维护、日志写入
## 2 性能优化四板斧
### 第一招:流式解析
使用POI的SAX模式替代DOM模式:
```java
// 正确写法:分段读取(以HSSF为例)
OPCPackage pkg = OPCPackage.open(file);
XSSFReader reader = new XSSFReader(pkg);
SheetIterator sheets = (SheetIterator) reader.getSheetsData();
while (sheets.hasNext()) {
try (InputStream stream = sheets.next()) {
Sheet sheet = new XSSFSheet(); // 流式解析
RowHandler rowHandler = new RowHandler();
sheet.onRow(row -> rowHandler.process(row));
sheet.process(stream); // 不加载全量数据
}
}
```
⚠️ **避坑指南**:
- 不同Excel版本需适配(HSSF/XSSF/SXSSF)
- 避免在解析过程中创建大量对象,需复用数据容器
### 第二招:分页批量插入
基于MyBatis的批量插入+连接池优化:
```java
// 分页批量插入(每1000条提交一次)
public void batchInsert(List list) {
SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH);
ProductMapper mapper = sqlSession.getMapper(ProductMapper.class);
int pageSize = 1000;
for (int i = 0; i < list.size(); i += pageSize) {
List subList = list.subList(i, Math.min(i + pageSize, list.size()));
mapper.batchInsert(subList);
sqlSession.commit();
sqlSession.clearCache(); // 清理缓存
}
}
```
**关键参数调优**:
```yml
# MyBatis配置
mybatis.executor.batch.size=1000
# 连接池(Druid)
spring.datasource.druid.maxActive=50
spring.datasource.druid.initialSize=10
```
### 第三招:异步化处理
架构设计:
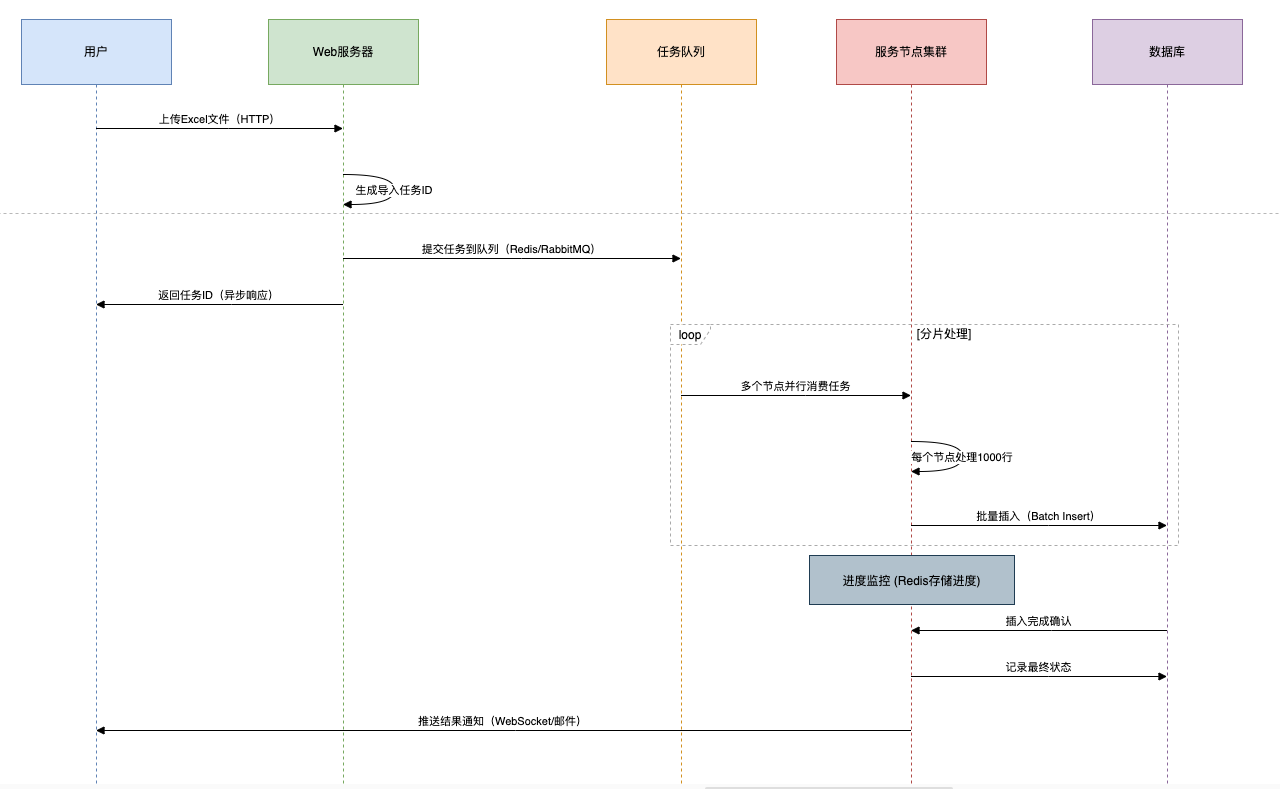
1. **前端上传**:客户端使用WebUploader等分片上传工具
2. **服务端**:
- 生成唯一任务ID
- 写入任务队列(Redis Stream/RabbitMQ)
3. **异步线程池**:
- 多线程消费队列
- 处理进度存储在Redis中
4. **结果通知**:通过WebSocket或邮件推送完成状态
### 第四招:并行导入
对于千万级数据,可采用分治策略:
| **阶段** | **操作** | **耗时对比** |
| --- | --- | --- |
| 单线程 | 逐条读取+逐条插入 | 基准值100% |
| 批处理 | 分页读取+批量插入 | 时间降至5% |
| 多线程分片 | 按Sheet分片,并行处理 | 时间降至1% |
| 分布式分片 | 多节点协同处理(如Spring Batch集群) | 时间降至0.5% |
## 3 代码之外的关键经验
### 3.1 数据校验必须前置
典型代码缺陷:
```java
// 错误:边插入边校验,可能污染数据库
public void validateAndInsert(Product product) {
if (product.getPrice() < 0) {
throw new Exception("价格不能为负");
}
productMapper.insert(product);
}
```
✅ **正确实践**:
1. 在流式解析阶段完成基础校验(格式、必填项)
2. 入库前做业务校验(数据关联性、唯一性)
### 3.2 断点续传设计
解决方案:
- 记录每个分片的处理状态
- 失败时根据偏移量(offset)恢复
### 3.3 日志与监控
配置要点:
```java
// Spring Boot配置Prometheus指标
@Bean
public MeterRegistryCustomizer metrics() {
return registry -> registry.config().meterFilter(
new MeterFilter() {
@Override
public DistributionStatisticConfig configure(Meter.Id id, DistributionStatisticConfig config) {
return DistributionStatisticConfig.builder()
.percentiles(0.5, 0.95) // 统计中位数和95分位
.build().merge(config);
}
}
);
}
```
## 四、百万级导入性能实测对比
测试环境:
- 服务器:4核8G,MySQL 8.0
- 数据量:100万行x15列(约200MB Excel)
| **方案** | **内存峰值** | **耗时** | **吞吐量** |
| --- | --- | --- | --- |
| 传统逐条插入 | 2.5GB | 96分钟 | 173条/秒 |
| 分页读取+批量插入 | 500MB | 7分钟 | 2381条/秒 |
| 多线程分片+异步批量 | 800MB | 86秒 | 11627条/秒 |
| 分布式分片(3节点) | 300MB/节点 | 29秒 | 34482条/秒 |
## 总结
Excel高性能导入的11条军规:
1. **决不允许全量加载数据到内存** → 使用SAX流式解析
2. **避免逐行操作数据库** → 批量插入加持
3. **永远不要让用户等待** → 异步处理+进度查询
4. **横向扩展比纵向优化更有效** → 分片+分布式计算
5. **内存管理是生死线** → 对象池+避免临时大对象
6. **合理配置连接池参数** → 杜绝瓶颈在数据源
7. **前置校验绝不动摇** → 脏数据必须拦截在入口
8. **监控务必完善** → 掌握全链路指标
9. **设计必须支持容灾** → 断点续传+幂等处理
10. **抛弃单机思维** → 拥抱分布式系统设计
11. **测试要覆盖极端场景** → 百万数据压测不可少
如果你正在为Excel导入性能苦恼,希望这篇文章能为你的系统打开一扇新的大门。
本文来自投稿,不代表本站立场,如若转载,请注明出处:http//www.knowhub.vip/share/2/1928
- 热门的技术博文分享
- 1 . ESP实现Web服务器
- 2 . 从零到一:打造高效的金仓社区 API 集成到 MCP 服务方案
- 3 . 使用C#构建一个同时问多个LLM并总结的小工具
- 4 . .NET 原生驾驭 AI 新基建实战系列Milvus ── 大规模 AI 应用的向量数据库首选
- 5 . 在Avalonia/C#中使用依赖注入过程记录
- 6 . [设计模式/Java] 设计模式之工厂方法模式
- 7 . 5. RabbitMQ 消息队列中 Exchanges(交换机) 的详细说明
- 8 . SQL 中的各种连接 JOIN 的区别总结!
- 9 . JavaScript 中防抖和节流的多种实现方式及应用场景
- 10 . SaltStack 远程命令执行中文乱码问题
- 11 . 推荐10个 DeepSeek 神级提示词,建议搜藏起来使用
- 12 . C#基础:枚举、数组、类型、函数等解析
- 13 . VMware平台的Ubuntu部署完全分布式Hadoop环境
- 14 . C# 多项目打包时如何将项目引用转为包依赖
- 15 . Chrome 135 版本开发者工具(DevTools)更新内容
- 16 . 从零创建npm依赖,只需执行一条命令
- 17 . 关于 Newtonsoft.Json 和 System.Text.Json 混用导致的的序列化不识别的问题
- 18 . 大模型微调实战之训练数据集准备的艺术与科学
- 19 . Windows快速安装MongoDB之Mongo实战
- 20 . 探索 C# 14 新功能:实用特性为编程带来便利
- 相关联分享
- Excel百万数据如何快速导入?