探秘MySQL索引底层原理,解锁数据库优化的关键密码(上)
笔记哥 /
04-01 /
10点赞 /
0评论 /
740阅读
大家有没有遇到过慢查询的情况?比如执行一条 SQL 需要几秒,甚至十几、几十秒,这时候 DBA 就会建议你去把查询的 SQL 优化一下,怎么优化呢?你第一时间想到的就是加索引吧?
为什么加索引就查得快了?
索引底层是怎么实现的?
为什么有时候加了索引还是很慢?
这就要从索引的本质以及它的底层原理说起了。接下来我们一起探秘 MySQL 索引底层原理,由于内容比较多,将分为上中下三篇,欢迎关注持续获取文章推送~
* * *
这篇文章主要内容:
- 索引的定义
- 索引的好处
- 深入探讨索引的底层数据结构
- B+Tree的特点
- 索引的优化
* * *
索引是什么?
索引到底是什么呢?你是不是还停留在大学时期《数据库原理》课上老师讲的“索引就像字典的目录”这样的概念?没错!索引就是数据的“目录”,有了目录我们可以很快定位到想找的数据。
不要把索引想得那么神秘,索引其实就是一种用于快速查找数据的数据结构,它不仅包含排好序的键值,还包含指向实际数据的指针。索引帮助MySQL高效获取数据,类似于字典的目录,通过目录可以快速定位到具体的数据页。
### 索引的好处
举例说明索引的好处以及是怎么加快查询的。
假设我们有一个表t,它有两个字段,Col1和Col2,如下:
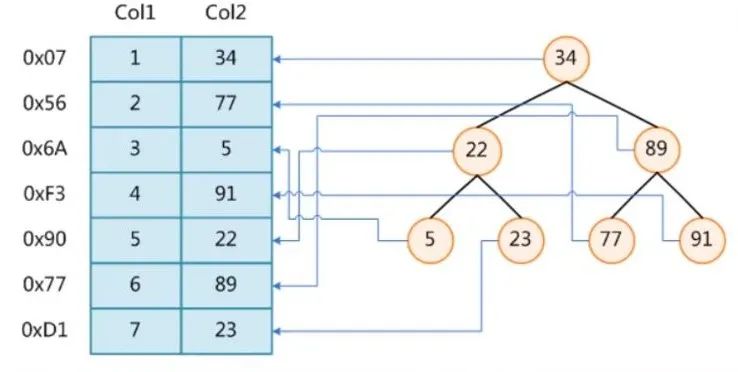
- 不加索引的情况
- 不加索引的情况下,SQL:
`select * from t where t.col2 = 89`
- 我们看上图左半部分,要找到 col2=89 的数据就需要从表的第一行开始遍历比对 col2 的值是否等于 89 ,这样需要比对 6 次才能查到。这只是只有几行记录的表,那如果是百万级、千万级的表呢?比较的次数就更多了,那查询速度可想而知。
- 加索引的情况
- 如果 col2 这列加了索引,MySQL 内部会维护一个数据结构。假设 MySQL 索引用的数据结构是红黑树(右子树的元素大于根节点,左子树的元素小于根节点),就像上图右半部分那样。
- 这样的话,刚才的那条 SQL 显然只需要两次磁盘 IO 就查到了,是不是快很多!(查找过程:先和根节点34比较,要找的数据大于34,则和34右子树对比,刚好是89,对比两次就找到了)
- 这就是索引的好处。索引使用比较巧妙的数据结构,利用数据结构的特性来大大减少查找遍历次数。
* * *
### 索引底层数据结构的探索
既然索引底层原理是利用一些巧妙的数据结构维护我们的数据,使得查询效率很高,那索引底层使用的什么数据结构呢?又是怎样来维护我们的数据呢?下面就带着大家一起探索一下索引的底层数据结构。
索引可选的数据结构 :
- 二叉树
- 红黑树
- HASH
- B-Tree
但 MySQL 索引的底层用的并不是二叉树和红黑树。因为二叉树和红黑树在某些场景下都会暴露出一些弊端或者说缺点。
### 二叉树
我们看一下二叉树如果作为索引的底层数据结构在什么样的场景下有怎么样的缺点和不足。
假设把刚才的SQL改一下,用 col1 作为条件来查找,SQL:
`select * from t where t.col1 = 6`
假如把 col1 作为索引,col1 这列的数据特点是从上到下依次递增,类似于自增主键,那么在每插入一行数据后 MySQL 在维护二叉树这样一个数据结构的时候,我们看一下二叉树维护成什么样子了。
打开这个网址(https://www.cs.usfca.edu/~galles/visualization/Algorithms.html),可以演示数据结构维护的过程。依次插入1、2、3、4、5…
通过这个网站的演示插入这些数据,如下图所示,我们可以看到这样的一个二叉树:一直在单边增长,没有左子树。再仔细看一下和我们学过的链表是不是很像,也就是说二叉树在某些场景下退化成了链表。
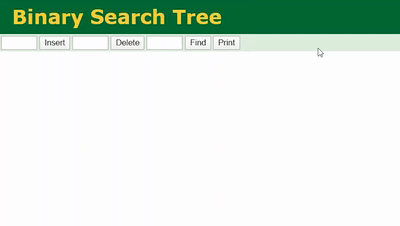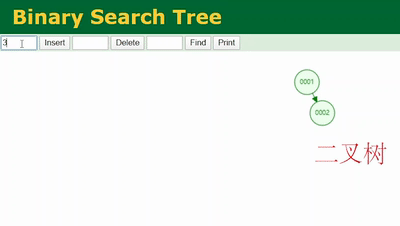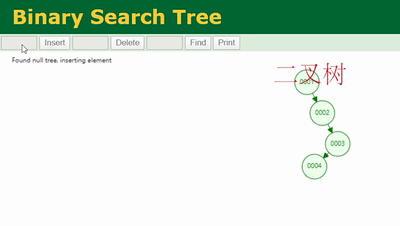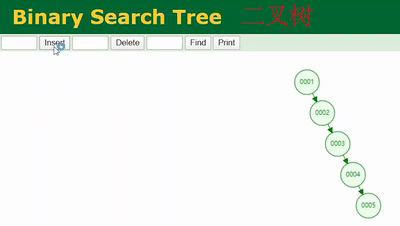
而链表的查找需要从头部遍历,这时候和没加索引从表的第一行遍历没什么太大区别!
即,当二叉树像上图一样退化成链表后,我们去查 col1=6 的记录需要从二叉树的根节点依次遍历,遍历 6 次才能查到,和不加索引从表里一行行的遍历没太大差别。这是二叉树作为索引底层数据结构的弊端之一。
关注公众号【`BiggerBoy`】获取更多优质文章~
### 红黑树
那有没有更好的数据结构用来存储索引,帮助我们更快的查找呢?比方说红黑树或HASH表。我们先看下红黑树。
红黑树是什么?
红黑树是一种自平衡的二叉查找树,JDK1.8的 HashMap 在链表长度超过一定阈值时会转换为红黑树,以提高查找效率。红黑树通过颜色标记和旋转操作保持树的平衡,确保在最坏情况下也能有较好的查找性能。
那我们把和刚才一样的数据用红黑树来看一下是什么样的效果,同样打开刚才的网址,我们选择红黑树。

依次插入1、2、3、4、5、6、7看一下效果。如下图所示,可以看到,当有单边增长的趋势时红黑树会进行一个平衡(旋转)。这时,我们查询 col1=6 的数据时,查了 3 次,比二叉树有了一些改进。

最终结构:
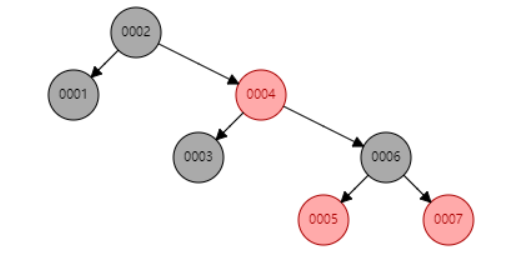
先剧透下一,MySQL 索引用的数据结构也不是红黑树,而是B+Tree(B-Tree的变种)。那为什么MySQL也没用红黑树做索引的数据结构呢?归根结底红黑树还是有缺陷的。
### 使用红黑树做索引底层数据结构的缺陷
我们可以想象一下,上述例子只有 7 条记录,树的高度就达到了 4 层,而当你的表数据量达到数百万、数千万的级别时,这颗红黑树的高度会有高?
假如说查找的数据在最后一层的叶子节点上(一般来说都是从根节点开始查找),假如树的高度是 50,那就要进行 50 次查找!50次磁盘IO开销已经非常大了。这就是红黑树作为索引数据结构的弊端:**树的高度过高导致查询效率变慢。**
那能不能做一点改造呢?我们看,红黑树的树越高查找次数会越多,会因为**树的高度影响查询效率**。所以我们要解决的问题就是降低树的高度,尽量控制它的高度在一个阈值范围内。比如说不大于 5,这样的话即使数据达到上千,最多也就 5 次磁盘 IO 就能查找到。对于千万级别的数据量,5 次磁盘 IO 也是可以接受的吧。
怎么改造能达到这个效果呢?想一下,既然要控制树的高度,又想存很多数据。也就是说限制了纵向发展,那就横向发展呗(身高已经增长不了了,长胖还是可以的😂)
对于上图的红黑树来说每个节点的子节点最多就两个,那基于横向增长的思想,就让它的树杈变成三杈、四杈…..让子节点增加,让每一层存储更多的索引元素,每个节点又分杈,分出来的杈又有很多个节点,每层的节点数指数级增长。那么存储同等数量级别的数据,横向存储的越多,树高就越小了。这样的一个改造结果就是B-Tree。
### B-Tree
- 叶子节点具有相同的深度,叶子节点的指针为空(因为是最后一层)
- 所有索引元素不重复(即每个节点数据都不一样)
- 每层节点中的数据索引从左到右递增排序
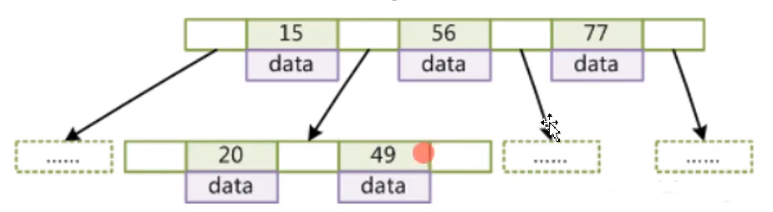
对比红黑树,这样的结构在一个节点上可以存储更多的元素,类似上图,根节点有三个元素,k-v 结构,key 就是索引字段,data 就是索引字段所在的那一行的数据或数据所在的磁盘文件地址、指针。这样的话,我们再去查找元素的时候不是一次性加载一个小元素,而是把一个大的节点的数据一次性全部加载到内存,然后再在内存里去对比(在内存里操作是相当快的)。
如果我们要查找49这个元素,它会从根节点开始查找,一次性将根节点这个大节点加载到内存里,然后用要查找的元素去比对。我们要找的 49,大于 15 小于 56,在 15 和 56 之间有一个节点存储的是下一个节点的磁盘地址,指向下一个节点(这个节点的索引都是大于15小于56的),然后再将这个节点一次性加载到内存去找这个元素,然后比对就找到了。
>
> 注意:一次加载节点是一次磁盘 IO,一次磁盘 IO 操作通常需要几毫秒的时间,而内存操作仅需几纳秒。因此,将数据从磁盘加载到内存后,在内存中进行查找操作的时间可以忽略不计。为了减少磁盘IO次数,B+Tree通过增加每个节点的键值数量来降低树的高度,从而减少查找过程中需要的磁盘IO次数。
那按这种说法树的高度越小越好,按这种思路可不可以把一个表的数据都放到一个大的节点上?然后把这个节点一次性加载到内存里,然后在内存里一个个去比对可以吗?因为内存里去比较查找元素是非常的快嘛,跟一次磁盘IO去比对快的多。不可以这样吗?
**答案是否定的。**
凡事都有个度。试想一下,假如我们有几千万数据,在磁盘上面全部放到一个节点上是不可能的!
原因很简单,数据表是一行行插入的,存储在磁盘上要占用几百兆甚至几个G,一次性加载到内存中显然不合适。内存本来就有限,一次性加载这么多的数据是不现实的。而且磁盘 IO 跟内存打交道的单位是 4KB,一次可能也就读取 4KB 的数据(有一些局部读取的原理可能会取几十KB(4的整数倍),取个16KB、24KB也是无可厚非的 )。但是一次交互取这么大是搞不定的,这是计算机组成原理决定的,一次磁盘 IO 取那么多数据,对内存也是非常的浪费,而且这样的一次磁盘 IO 将会是灾难级的。
所以这个节点的大小设置要合适,不能太大也不能太小。MySQL 的InnoDB 存储引擎默认使用 16KB 的页大小,可以通过下面的 SQL 语句查询:
`show clobal status like 'Innodb_page_size'`
一个节点16KB ,类比到先前的结构图上就像下图这样:
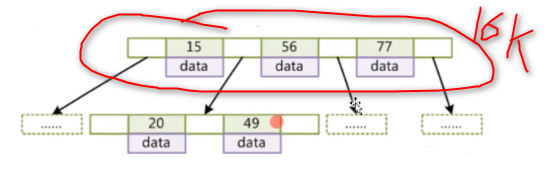
为什么一个节点设置为 16KB 呢?而不是更大的如 16M 呢?
因为16KB已经足够用了。16KB的页大小在保证一次磁盘IO加载足够数据的同时,避免了内存的过度消耗。这个大小经过优化,能够在大多数场景下提供良好的性能。
MySQL索引选择的不是原生的B-Tree,而是对它进行了改造,得到的是一种叫做B+Tree的数据结构。
* * *
B+Tree(B-Tree的变种)
- 非叶子节点不存储data,只存储索引(冗余),可以放更多的索引
- 叶子节点包含所有索引字段
- 叶子节点用指针连接,提高区间访问的性能

#### 与B-Tree的区别
- B-Tree的每个节点都包含键值和数据指针,而B+Tree的非叶子节点只存储键值,数据指针仅存在于叶子节点。
- B+Tree的叶子节点之间通过指针连接,形成一个有序链表,这使得范围查询更加高效。
- B+Tree的这种设计减少了树的高度,提高了查询性能。
#### 为什么Data元素挪到叶子节点?
- 非叶子节点只存储索引元素
这样非叶子节点的每个节点就可以存储更多的索引元素(等会我们大致估算一下可以存储多少)
- 叶子节点存储了一份完整表的所有行的索引字段
data 元素是每个索引元素所对应的要查找的行记录的位置或行数据
实际上非叶子节点存储的是一些冗余索引,看一下上图,15、20、49,选择的是整张表中处于中间位置的数据作为索引,因为它要用到 B+Tree 比较大小的方式去查找。(B+Tree 本质可以叫做多叉平衡树,单看 B+Tree 的某一小块仍是一个二叉树)
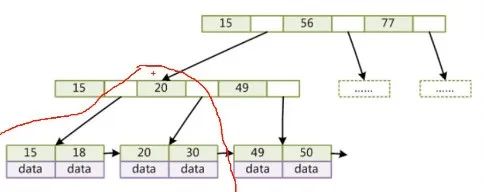
还有一个特点。某一个节点的元素处于一个递增的顺序,会提取叶子节点的一些处于中间位置的数据作为冗余索引,查找的时候从根节点开始查找,先把根节点加载到内存里去,然后在内存里去比对。
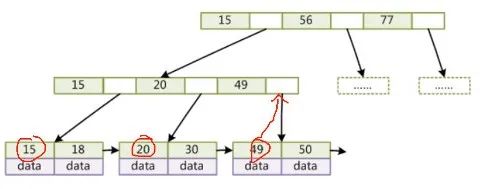
比如要查找索引为 30 的数据,先在根节点跟 15 去比较,发现大于 15 小于 56,然后从它俩中间的指针查找下一个节点把它加载到内存,再在内存里去比对。大于15 大于 20,小于 49,就根据 20 和 49 之间的指针找到下一个节点,然后加载到内存去比对,不等于 20,然后跟下一个 30 对比,发现正好相等,OK找到了。
#### 为什么把中间的元素提取出来做冗余元素?
为啥要搞这些冗余索引,而且把这些冗余索引的data元素搞到叶子节点?也就是说 B+Tree 相当于与 B-Tree 来说非叶子节点是不存储data元素的,叶子节点才存储 data 元素。
你想一下,一个节点不能太大也不能太小,默认就是 16KB,把 data 元素挪走以后,是不是这个节点就能存更多的冗余索引了,意味着分叉就更多了,意味着叶子节点就能存储更多的数据了。
#### B+Tree索引数据量估算
假设索引字段类型是Bigint,8bit,每两个元素之间存的是下一个节点的地址,MySQL分配的是 6bit,也就是说一个索引后面配对一个节点地址,成对出现,可以算一下 16KB 的节点可以存多少对,也就是多少个索引,`8b + 6b = 14b`,`16KB /14b = 1170`个索引,叶子节点有索引有data元素,假设占1K,那一个节点就放16K/1K=16个元素,假设树高是3,所有节点都放满,能放多少数据?可以算一下,`1170 * 1170 * 16 = 21902400`,2千多万,MySQL 设置 16KB 的大小,数据就可以存两千多万就已经足够了吧,既能保证一次磁盘 IO 不要加载太多的数据 又能保证一次加载的性能,即便表的数据在几千万的数量也能保证树的高度在一个可控的范围。
可以看一下几千万的数据表加了索引几十毫秒或几百毫秒就能查询出结果,所以就解释了几千万的表精确的使用索引后它的性能依旧比较高。
树的高度只有三层的情况下就能存储两千多万的数据,即便某一个索引在叶子节点,那也就二或三次磁盘 IO 就能查找到,当然很快了。而且 MySQL 底层的索引根节点,是常驻内存的,直接就放到内存。一个两千万的数据放到 B+Tree 上面,要查找叶子节点,就只需要两次磁盘 IO 就搞定了,在内存里比对的时间基本可以忽略。
### 总结
到这里做个总结吧!这篇文章主要讨论了MySQL索引的底层原理和优化方法。
文章的主要内容:
1. **索引的定义**:
- 索引是一种用于快速查找数据的数据结构,类似于字典的目录,帮助MySQL高效获取数据。
2. **索引的好处**:
- 通过索引可以大大减少数据查找的遍历次数,从而提高查询效率。例如,在一个百万级甚至千万级的表中,使用索引可以将查询时间从几秒甚至几十秒减少到几毫秒。
3. **索引的底层数据结构**:
- 文章详细介绍了索引底层可能使用的数据结构,包括二叉树、红黑树、HASH 和 B-Tree,并解释了为什么 MySQL 最终选择了 B+Tree 作为索引的数据结构。
- 二叉树和红黑树在某些场景下会退化成链表,导致查询效率下降。
- B+Tree 通过控制树的高度和增加每个节点的子节点数量,使得在大数据量下依然能保持高效的查询性能。
4. **B+Tree 的特点**:
- B+Tree的非叶子节点只存储索引,叶子节点存储所有数据,并且叶子节点之间有指针连接,这对于范围查询非常重要。
- B+Tree的节点大小通常设置为16K,这样可以保证一次磁盘IO加载的数据量适中,既能减少磁盘IO次数,又能充分利用内存。
5. **索引的优化**:
- 通过合理设计索引,可以显著提高查询性能。例如,对于几千万条数据的表,使用B+Tree索引可以将查询时间控制在几十毫秒内。
本文来自投稿,不代表本站立场,如若转载,请注明出处:http//www.knowhub.vip/share/2/1913
- 热门的技术博文分享
- 1 . ESP实现Web服务器
- 2 . 从零到一:打造高效的金仓社区 API 集成到 MCP 服务方案
- 3 . 使用C#构建一个同时问多个LLM并总结的小工具
- 4 . .NET 原生驾驭 AI 新基建实战系列Milvus ── 大规模 AI 应用的向量数据库首选
- 5 . 在Avalonia/C#中使用依赖注入过程记录
- 6 . [设计模式/Java] 设计模式之工厂方法模式
- 7 . 5. RabbitMQ 消息队列中 Exchanges(交换机) 的详细说明
- 8 . SQL 中的各种连接 JOIN 的区别总结!
- 9 . JavaScript 中防抖和节流的多种实现方式及应用场景
- 10 . SaltStack 远程命令执行中文乱码问题
- 11 . 推荐10个 DeepSeek 神级提示词,建议搜藏起来使用
- 12 . C#基础:枚举、数组、类型、函数等解析
- 13 . VMware平台的Ubuntu部署完全分布式Hadoop环境
- 14 . C# 多项目打包时如何将项目引用转为包依赖
- 15 . Chrome 135 版本开发者工具(DevTools)更新内容
- 16 . 从零创建npm依赖,只需执行一条命令
- 17 . 关于 Newtonsoft.Json 和 System.Text.Json 混用导致的的序列化不识别的问题
- 18 . 大模型微调实战之训练数据集准备的艺术与科学
- 19 . Windows快速安装MongoDB之Mongo实战
- 20 . 探索 C# 14 新功能:实用特性为编程带来便利