探秘 MySQL 索引底层原理,解锁数据库优化的关键密码(下)
笔记哥 /
04-01 /
15点赞 /
0评论 /
552阅读
但之前都是基于单值索引,由于文章篇幅原因也只是在文末略提了一下`联合索引`,并没有大篇幅的展开讨论,所以这篇文章就单独去讲一下联合索引在B+树上的存储结构。
本文主要讲解的内容有:
- 联合索引在B+树上的存储结构
- 联合索引的查找方式
- 为什么会有最左前缀匹配原则?
- 实战
在分享这篇文章之前,我在网上查了关于MySQL联合索引在B+树上的存储结构这个问题,翻阅了很多博客和技术文章,其中有几篇讲述的与事实相悖。庆幸的是看到搜索引擎列出的有一条是来自思否社区的问答,有答主回答了这个问题,贴出一篇文章和一张图以及一句简单的描述。PS:贴出的文章链接已经打不开了。
所以在这样的条件下这篇文章就诞生了。
## 联合索引的存储结构
下面就引用思否社区的这个问答来展开我们今天要讨论的联合索引的存储结构的问题。
来自思否的提问,联合索引的存储结构(https://segmentfault.com/q/1010000017579884)有码友回答如下:
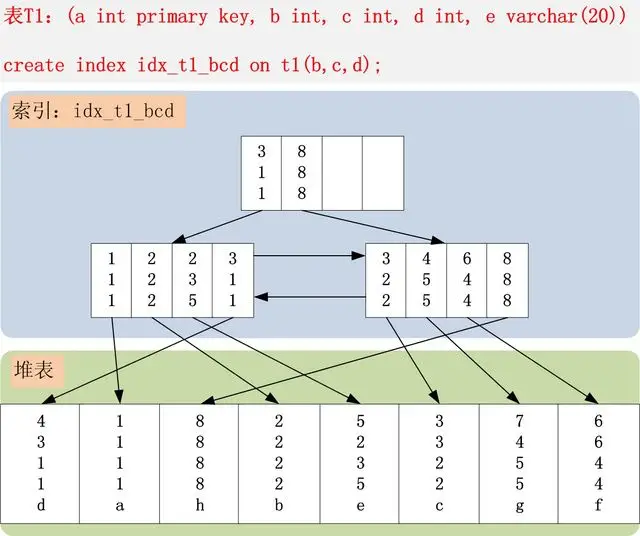
> 联合索引 bcd , 在索引树中的样子如图 , 在比较的过程中 ,先判断 b 再判断 c 然后是 d
由于回答只有一张图一句话,可能会让你有点看不懂,所以我们就借助前人的肩膀用这个例子来更加细致的讲探寻一下联合索引在B+树上的存储结构吧。
首先,表T1有字段`a,b,c,d,e`,其中a是主键,除e为`varchar`其余为`int`类型,并创建了一个联合索引`idx_t1_bcd(b,c,d)`。上图树高只有两层不容易理解,下面是假设的表数据以及我对其联合索引在B+树上的结构图的改进。PS:基于`InnoDB`存储引擎。
假设T1表有如下数据:
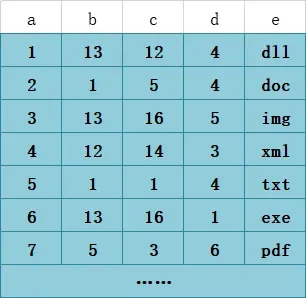
*T1表*
那么基于联合索引`(b、c、d)`构建的B+树大致如下图所示(拿根节点的第一个来说,1 1 4即是b=1,c=1,d=4)
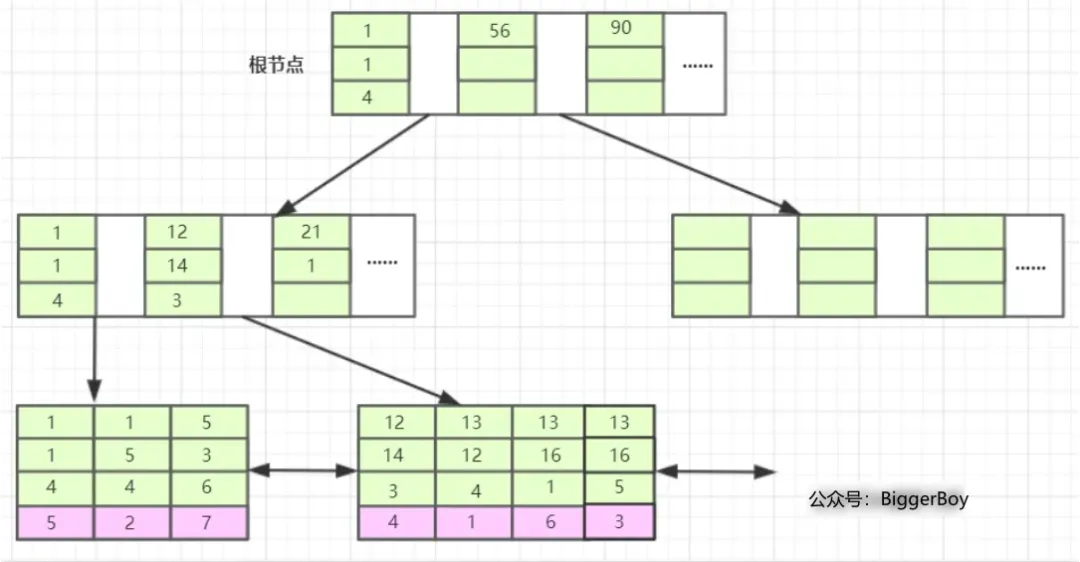
*bcd联合索引在B+树上的结构图*
通过这两张图我们脑海里对联合索引在B+树上的存储结构应该就有了个大概的认识。
我们先看T1表,它的主键a我们暂且将它设为**整型自增**的(PS:至于为什么是整型自增上两篇文章有详细介绍这里不再赘述),`InnoDB`会使用主键索引在B+树维护索引和数据文件,然后我们创建了一个联合索引`(b,c,d)`也会生成一个索引树,同样也是B+树的结构,只不过它的叶子节点data部分存储的是联合索引所在行的主键值(上图叶子节点紫色背景部分),至于**为什么辅助索引data部分存储主键值**上篇文章也有介绍,感兴趣或还没看的可以去看一下。
好了大致情况都介绍完了,下面我们结合这两张图来解释一下。
与单列索引相比,联合索引只不过比其多了几列,而且这些索引列全部都出现在索引树上。对于联合索引,存储引擎首先会根据第一个索引列排序,如上图我们可以看B+树的最后一层,单看第一个索引列,即叶子节点的第一行`1、1、5、12、13、13、13`显然是趋势递增的。即:**如果第一列相等则再根据第二列排序**,依此类推就构成了上图的索引树。
另外,我们看,第二行和第三行,即联合索引的c列和d列,分别是`1、5、3、14、12、16、16`和`4、4、6、3、4、1、5`,这里就又没有了**趋势递增**。而在b列相同时,c列才会趋势递增,如b=1时的`1、5`,b=13时的`12、16、16`,同理c列相同时,d列才会趋势递增。这也就是为什么要遵循最左前缀原则。
### 小结
#### 基于B+树的多列键值组织
联合索引将多个字段组合成一个键值,按照字段定义的顺序构建B+树。例如,联合索引`(b, c, d)`的每个节点中,键值按b→c→d的顺序排列:
- **非叶子节点**:存储所有字段的键值(如b, c, d的组合)及指向子节点的指针。
- **叶子节点**:存储完整的联合索引键值(b, c, d)和对应的主键值(用于回表查询)。
#### 排序规则
- **全局有序性**:所有节点按第一列(最左列)排序,若第一列值相同,则按第二列排序,依此类推。例如,(b=1, c=2)会排在(b=1, c=3)之前
- **局部有序性**:同一层级内,每个节点存储的键值按顺序排列,支持快速范围查询。
#### 物理存储优化
- B+树的非叶子节点不存储实际数据,仅存储键值和指针,单个磁盘页(如16KB)可容纳更多键值,减少树的高度(通常3-4层即可支持千万级数据)。
- 叶子节点通过双向链表连接,便于范围遍历。
## 联合索引的查找方式
### 精确匹配查询
- **最左前缀匹配原则**:查询条件必须从联合索引的最左列开始。例如,索引 `(b, c, d) `的查询:
- **有效条件**: `WHERE b=1`、 `WHERE b=1 AND c=2` 、 `WHERE b=1 AND c=2 AND d=3`。
- **失效条件**: `WHERE c=2` 、 `WHERE d=3` (因无法利用全局有序性。
- **查询优化器调整**:即使条件顺序与索引不同(如 `WHERE c=2 AND b=1` ),优化器会自动调整为 `b=1 AND c=2` 以匹配索引 。
### 范围查询
- 范围查询(如 b>10 )会利用索引,但后续字段无法继续匹配。例如, `WHERE b>10 AND c=2` 中,只有 b>10 走索引, c=2 需在结果集中过滤 。
- 范围查询后的字段索引失效(如 `WHERE b=1 AND c>2 AND d=3` , d 无法使用索引)。
### 覆盖索引与回表
- **覆盖索引**:若查询字段全部在联合索引中(如 `SELECT a, b FROM T1` ),无需回表,直接从叶子节点获取数据。
- **回表查询**:若需获取非索引字段(如 `SELECT * `),需通过叶子节点的主键值回聚簇索引获取完整数据
* * *
下面咱们一起来详细看一下精确匹配查询过程。
当我们的SQL可以应用到索引的时候,比如 `select * from T1 where b = 12 and c = 14 and d = 3` 也就是T1表中a列为4的这条记录。
存储引擎首先从根节点(一般常驻内存)开始查找,第一个索引的第一个索引列为1,由于12大于1,第二个索引的第一个索引列为56,又因12小于56,所以从这俩索引的中间读到下一个节点的磁盘文件地址,从磁盘上加载这个节点,通常伴随一次磁盘IO,然后在内存里去查找。当加载叶子节点的第二个节点时又是一次磁盘IO,从该节点的第一个元素开始匹配,`b=12,c=14,d=3`完全符合。由于咱们Select \*,所以还需要拿到该索引下的data元素即ID值,再从主键索引树上找到最终数据(回表)。
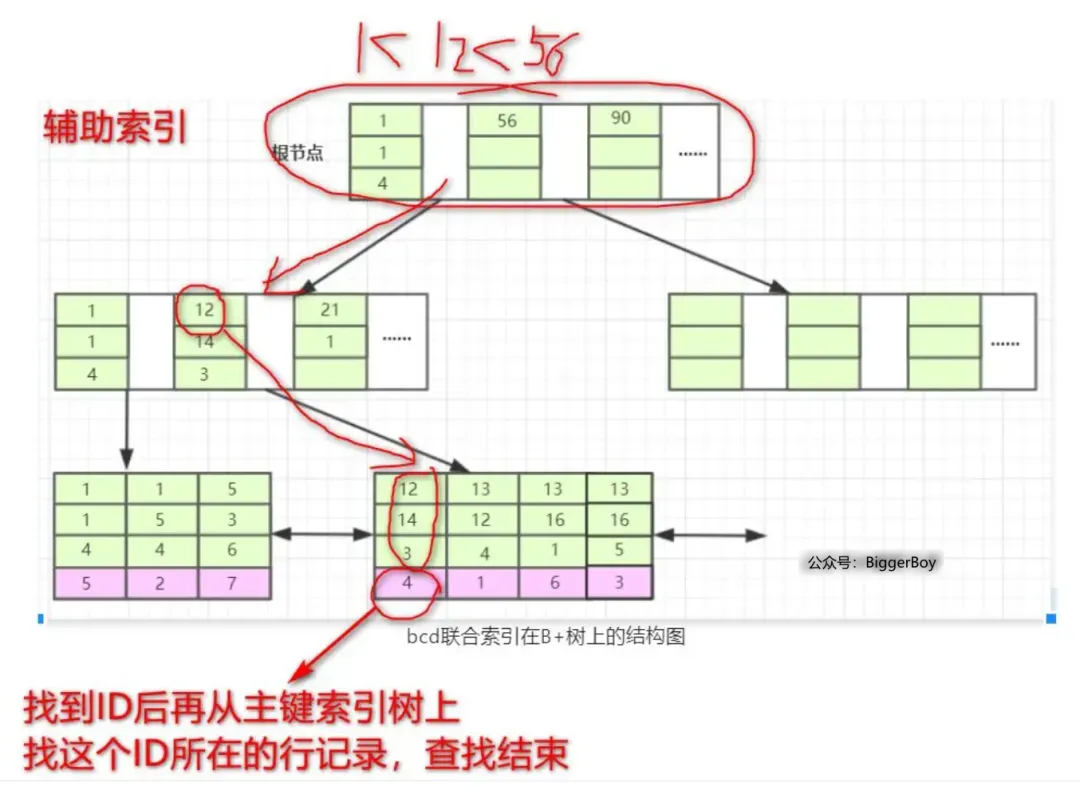
而如果Select后只有a,那么要查询的列就都存在于这颗联合索引的B+树上,此时无需回表,这即是覆盖索引。
## 最左前缀匹配原则
之所以会有最左前缀匹配原则,其实和联合索引的索引构建方式及存储结构是密不可分的。
首先我们创建的`idx_t1_bcd(b,c,d)`索引,相当于创建了`(b)`、`(b、c)`、`(b、c、d)`三个索引,下面将会详细解析。
联合索引将多个字段组合成一个键值,按照字段定义的顺序构建B+树。
上面`idx_t1_bcd(b,c,d)`的例子就是优先使用b列构建,当b列值相等时再以c列排序,若c列的值也相等则以d列排序。我们可以取出索引树的叶子节点看一下。
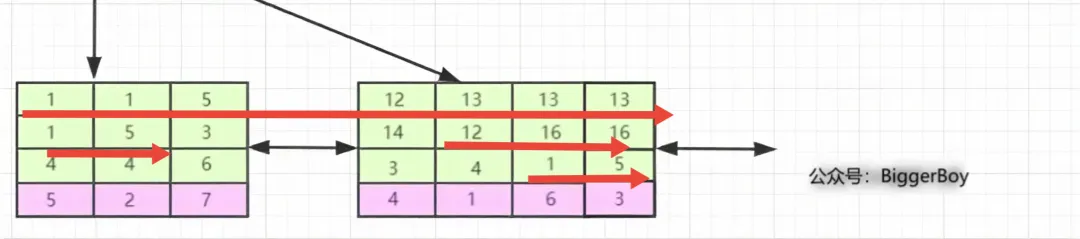
索引的第一列也就是b列是从左到右趋势递增的,但我们看第二行c列和第三行d列并没有这个特性。仔细观察发现c列只能在b列值相等的情况下小范围内递增,如第一叶子节点的第1、2个元素和第二个叶子节点的后三个元素。d列亦是如此,它只能在c列值相等时递增。
由于联合索引是上述那样的索引构建方式及存储结构,所以联合索引只能从多列索引的第一列开始查找。所以如果你的查找条件不包含b列如`(c,d)`、`(c)`、`(d)`是无法应用索引的,以及跨列也是无法完全用到索引,如(b,d),只会用到b列索引。
这就像我们的电话本一样,有`名`和`姓`以及`电话`,名和姓就是联合索引。首先以姓的首字母排序,姓的首字母相同的情况下,再以名的首字母排序。
如:
```csharp
M 毛 不易 178******** 马 化腾 183******** 马 云 188********Z 张 杰 189******** 张 靓颖 138******** 张 艺兴 176********
```
我们知道`名`和`姓`是很快就能够从姓的首字母索引定位到姓,然后定位到名,进而找到电话号码,因为所有的姓从上到下按照既定的规则(首字母排序)是有序的,而名是在姓的首字母一定的条件下也是按照名的首字母排序的,但是整体来看,所有的名放在一起是无序的,所以如果只知道名查找起来就比较慢,因为无法用已排好的结构快速查找。
到这里大家是否明白了为啥会有最左前缀匹配原则了吧。
* * *
### 设计优化建议
- **列顺序选择**
- 高频查询条件列放在最左,区分度高的列优先 。例如,若 WHERE a=1 AND b=2 更常见,则索引应为 (a, b) 而非 (b, a) 。
- **避免冗余列**
- *联合索引的字段应精简,避免包含低区分度或重复功能的列 。*
- **索引下推(Index Condition Pushdown)**
- MySQL 5.6+支持将WHERE条件中可通过索引过滤的部分下推到存储引擎层,减少回表次数。
*关于索引设计优化之前的文章有更详细的介绍,请看文末文章链接。*
## 实践
如下列举一些SQL的索引使用情况
```csharp
select * from T1 where b =12 and c =14 and d =3;-- 全值索引匹配 三列都用到
select * from T1 where b =12 and c =14 and e ='xml';-- 应用到两列索引
select * from T1 where b =12 and e ='xml';-- 应用到一列索引
select * from T1 where b =12 and c >=14 and e ='xml';-- 应用到一列索引及索引条件下推优化
select * from T1 where b =12 and d =3;-- 应用到一列索引 因为不能跨列使用索引 没有c列 连不上
select * from T1 where c =14 and d =3;-- 无法应用索引,违背最左匹配原则
```
## 后记
经过对MySQL联合索引存储结构与查询机制的系统梳理,相信大家对B+Tree索引的工作原理有了更深入的理解。限于篇幅,本文暂未涉及排序优化(ORDER BY)、覆盖索引(Covering Index)以及哈希/全文索引等内容,后续将推出相关系列文章展开探讨。
需要说明的是:数据库优化是理论与实践深度结合的领域,本文侧重于索引机制的底层解析,实际业务中的调优策略还需结合具体场景进行验证。
本文来自投稿,不代表本站立场,如若转载,请注明出处:http//www.knowhub.vip/share/2/1900
- 热门的技术博文分享
- 1 . ESP实现Web服务器
- 2 . 从零到一:打造高效的金仓社区 API 集成到 MCP 服务方案
- 3 . 使用C#构建一个同时问多个LLM并总结的小工具
- 4 . .NET 原生驾驭 AI 新基建实战系列Milvus ── 大规模 AI 应用的向量数据库首选
- 5 . 在Avalonia/C#中使用依赖注入过程记录
- 6 . [设计模式/Java] 设计模式之工厂方法模式
- 7 . 5. RabbitMQ 消息队列中 Exchanges(交换机) 的详细说明
- 8 . SQL 中的各种连接 JOIN 的区别总结!
- 9 . JavaScript 中防抖和节流的多种实现方式及应用场景
- 10 . SaltStack 远程命令执行中文乱码问题
- 11 . 推荐10个 DeepSeek 神级提示词,建议搜藏起来使用
- 12 . C#基础:枚举、数组、类型、函数等解析
- 13 . VMware平台的Ubuntu部署完全分布式Hadoop环境
- 14 . C# 多项目打包时如何将项目引用转为包依赖
- 15 . Chrome 135 版本开发者工具(DevTools)更新内容
- 16 . 从零创建npm依赖,只需执行一条命令
- 17 . 关于 Newtonsoft.Json 和 System.Text.Json 混用导致的的序列化不识别的问题
- 18 . 大模型微调实战之训练数据集准备的艺术与科学
- 19 . Windows快速安装MongoDB之Mongo实战
- 20 . 探索 C# 14 新功能:实用特性为编程带来便利