FastAPI依赖注入实践:工厂模式与实例复用的优化策略
笔记哥 /
04-06 /
11点赞 /
0评论 /
336阅读
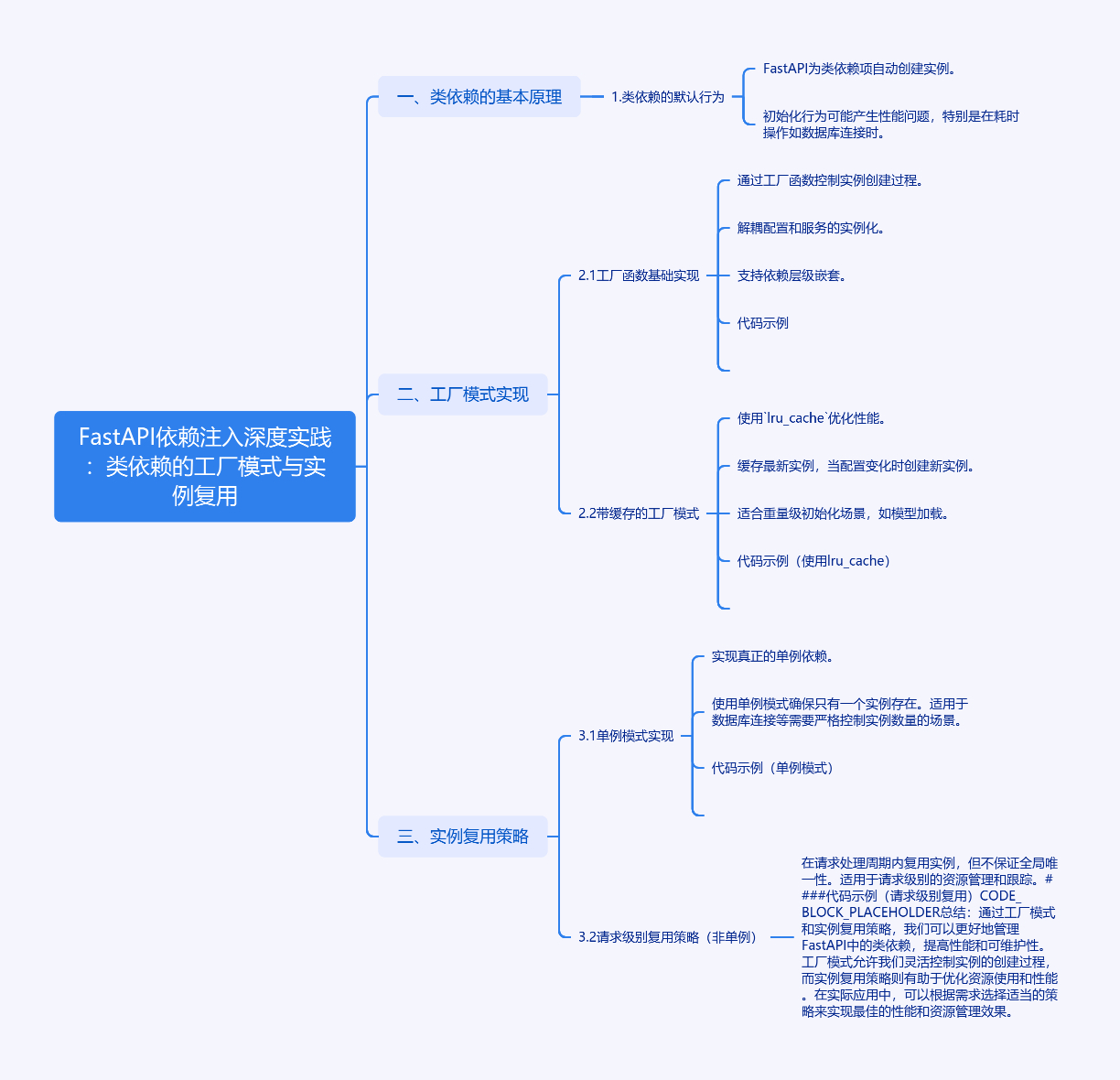
FastAPI依赖注入系统中,类依赖的默认行为是为每个请求创建新实例,可能导致性能问题。通过工厂模式控制实例创建过程,可解耦配置和服务实例化,支持依赖层级嵌套,符合单一职责原则。使用lru\_cache实现带缓存的工厂模式,优化高频调用场景性能。单例模式实现真正的单例依赖,请求级别复用策略在请求处理周期内复用实例。实际应用场景包括配置中心集成和多租户系统,动态配置加载和租户感知的依赖注入。常见报错解决方案涉及422 Validation Error和依赖项初始化失败。
categories:
- 后端开发
- FastAPI
tags:
- FastAPI
- 依赖注入
- 工厂模式
- 实例复用
- 单例模式
- 多租户系统
- 性能优化
探索数千个预构建的 AI 应用,开启你的下一个伟大创意
# FastAPI依赖注入深度实践:类依赖的工厂模式与实例复用
## 一、类依赖的基本原理
在FastAPI的依赖注入系统中,类作为依赖项使用时,框架会自动创建类的实例。当我们这样定义一个路由处理函数时:
```csharp
@app.get("/items/")
def read_items(service: ItemService = Depends()):
return service.get_items()
```
FastAPI会为每个请求创建一个新的ItemService实例。这种默认行为在某些场景下可能产生性能问题,特别是当依赖类需要执行初始化数据库连接、加载大文件等耗时操作时。
## 二、工厂模式实现
### 2.1 工厂函数基础实现
通过工厂模式控制实例创建过程:
```csharp
class DatabaseConfig:
def __init__(self, url: str = "sqlite:///test.db"):
self.url = url
class DatabaseService:
def __init__(self, config: DatabaseConfig):
self.connection = self.create_connection(config.url)
def create_connection(self, url):
# 模拟数据库连接
print(f"Creating new connection to {url}")
return f"Connection_{id(self)}"
def get_db_service(config: DatabaseConfig = Depends()) -> DatabaseService:
return DatabaseService(config)
@app.get("/users/")
def get_users(service: DatabaseService = Depends(get_db_service)):
return {"connection": service.connection}
```
这个实现的特点:
- 解耦配置和服务的实例化
- 支持依赖层级嵌套(DatabaseConfig自动注入到工厂函数)
- 符合单一职责原则
### 2.2 带缓存的工厂模式
优化高频调用场景的性能:
```csharp
from fastapi import Depends
from functools import lru_cache
class AnalysisService:
def __init__(self, config: dict):
self.model = self.load_ai_model(config["model_path"])
def load_ai_model(self, path):
print(f"Loading AI model from {path}")
return f"Model_{id(self)}"
@lru_cache(maxsize=1)
def get_analysis_service(config: dict = {"model_path": "models/v1"}) -> AnalysisService:
return AnalysisService(config)
@app.get("/predict")
def make_prediction(service: AnalysisService = Depends(get_analysis_service)):
return {"model": service.model}
```
缓存机制说明:
- 使用lru\_cache实现内存缓存
- maxsize=1表示只缓存最新实例
- 当配置参数变化时会自动创建新实例
- 适合模型加载等重量级初始化场景
## 三、实例复用策略
### 3.1 单例模式实现
实现真正的单例依赖:
```csharp
from contextlib import contextmanager
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
class DatabaseSingleton:
_instance = None
def __new__(cls, dsn: str):
if not cls._instance:
cls._instance = super().__new__(cls)
cls._instance.engine = create_engine(dsn)
cls._instance.Session = sessionmaker(bind=cls._instance.engine)
return cls._instance
@contextmanager
def get_db_session(dsn: str = "sqlite:///test.db"):
db = DatabaseSingleton(dsn)
session = db.Session()
try:
yield session
session.commit()
except Exception as e:
session.rollback()
raise e
finally:
session.close()
@app.get("/transactions")
def get_transactions(session=Depends(get_db_session)):
return {"status": "success"}
```
### 3.2 请求级别复用
在请求处理周期内复用实例:
```csharp
from fastapi import Request
class RequestTracker:
def __init__(self, request: Request):
self.request = request
self.start_time = time.time()
@property
def duration(self):
return time.time() - self.start_time
def get_tracker(request: Request) -> RequestTracker:
if not hasattr(request.state, "tracker"):
request.state.tracker = RequestTracker(request)
return request.state.tracker
@app.get("/status")
def get_status(tracker: RequestTracker = Depends(get_tracker)):
return {"duration": tracker.duration}
```
## 四、实际应用场景
### 4.1 配置中心集成
动态配置加载示例:
```csharp
from pydantic import BaseSettings
class AppSettings(BaseSettings):
env: str = "dev"
api_version: str = "v1"
class Config:
env_file = ".env"
def config_factory() -> AppSettings:
return AppSettings()
def get_http_client(settings: AppSettings = Depends(config_factory)):
timeout = 30 if settings.env == "prod" else 100
return httpx.Client(timeout=timeout)
```
### 4.2 多租户系统
租户感知的依赖注入:
```csharp
class TenantContext:
def __init__(self, tenant_id: str):
self.tenant_id = tenant_id
self.config = self.load_tenant_config()
def load_tenant_config(self):
# 模拟从数据库加载配置
return {
"db_url": f"sqlite:///tenant_{self.tenant_id}.db",
"theme": "dark" if self.tenant_id == "acme" else "light"
}
def tenant_factory(tenant_id: str = Header(...)) -> TenantContext:
return TenantContext(tenant_id)
@app.get("/dashboard")
def get_dashboard(ctx: TenantContext = Depends(tenant_factory)):
return {"theme": ctx.config["theme"]}
```
## 五、课后Quiz
1. 工厂模式在依赖注入中的主要作用是?
A) 减少代码量
B) 控制实例创建过程
C) 提高路由处理速度
D) 自动生成API文档
2. 使用lru\_cache装饰器缓存服务实例时,当什么情况下会创建新实例?
A) 每次请求时
B) 输入参数变化时
C) 服务类代码修改时
D) 服务器重启时
3. 在多租户系统中,如何实现不同租户的数据库隔离?
A) 使用不同的路由前缀
B) 基于租户ID动态生成数据库连接
C) 为每个租户创建独立应用实例
D) 使用请求头认证
(答案:1.B 2.B 3.B)
## 六、常见报错解决方案
### 错误1:422 Validation Error
**现象**:
```csharp
{
"detail": [
{
"loc": [
"header",
"x-tenant-id"
],
"msg": "field required",
"type": "value_error.missing"
}
]
}
```
**原因分析**:
- 请求缺少必要的Header参数
- 工厂函数参数类型声明错误
- 依赖项层级结构不匹配
**解决方案**:
1. 检查请求是否包含所有必需的Header
2. 验证工厂函数的参数类型声明
3. 使用依赖关系图工具调试:
```csharp
uvicorn main:app --reload --debug
```
### 错误2:依赖项初始化失败
**现象**:
```csharp
RuntimeError: Unable to initialize service - missing config
```
**排查步骤**:
1. 检查依赖项的参数传递链路
2. 验证配置对象的默认值设置
3. 在工厂函数中添加调试日志:
```csharp
def get_service(config: AppSettings):
print("Current config:", config.dict())
return MyService(config)
```
**预防建议**:
- 为所有配置参数设置合理的默认值
- 使用pydantic的Field验证:
```csharp
class AppSettings(BaseSettings):
db_url: str = Field(..., env="DATABASE_URL")
```
本文来自投稿,不代表本站立场,如若转载,请注明出处:http//www.knowhub.vip/share/2/2026
- 热门的技术博文分享
- 1 . ESP实现Web服务器
- 2 . 从零到一:打造高效的金仓社区 API 集成到 MCP 服务方案
- 3 . 使用C#构建一个同时问多个LLM并总结的小工具
- 4 . .NET 原生驾驭 AI 新基建实战系列Milvus ── 大规模 AI 应用的向量数据库首选
- 5 . 在Avalonia/C#中使用依赖注入过程记录
- 6 . [设计模式/Java] 设计模式之工厂方法模式
- 7 . 5. RabbitMQ 消息队列中 Exchanges(交换机) 的详细说明
- 8 . SQL 中的各种连接 JOIN 的区别总结!
- 9 . JavaScript 中防抖和节流的多种实现方式及应用场景
- 10 . SaltStack 远程命令执行中文乱码问题
- 11 . 推荐10个 DeepSeek 神级提示词,建议搜藏起来使用
- 12 . C#基础:枚举、数组、类型、函数等解析
- 13 . VMware平台的Ubuntu部署完全分布式Hadoop环境
- 14 . C# 多项目打包时如何将项目引用转为包依赖
- 15 . Chrome 135 版本开发者工具(DevTools)更新内容
- 16 . 从零创建npm依赖,只需执行一条命令
- 17 . 关于 Newtonsoft.Json 和 System.Text.Json 混用导致的的序列化不识别的问题
- 18 . 大模型微调实战之训练数据集准备的艺术与科学
- 19 . Windows快速安装MongoDB之Mongo实战
- 20 . 探索 C# 14 新功能:实用特性为编程带来便利