全类型文档一键解析:开源效率神器MegaParse
51工具 /
04-13 /
49点赞 /
0评论 /
560阅读
在日常工作中,我们经常需要处理各种格式的文档,比如 PDF、PPT、Word、Excel 等。
有时为了提取文档中的内容,要在多个工具之间来回切换,这不仅费时费力,还可能会丢失一些重要信息。
最近在 GitHub 上,我发现了一个非常实用的开源工具 **MegaParse**,它可以帮助我们轻松解决这些烦恼。
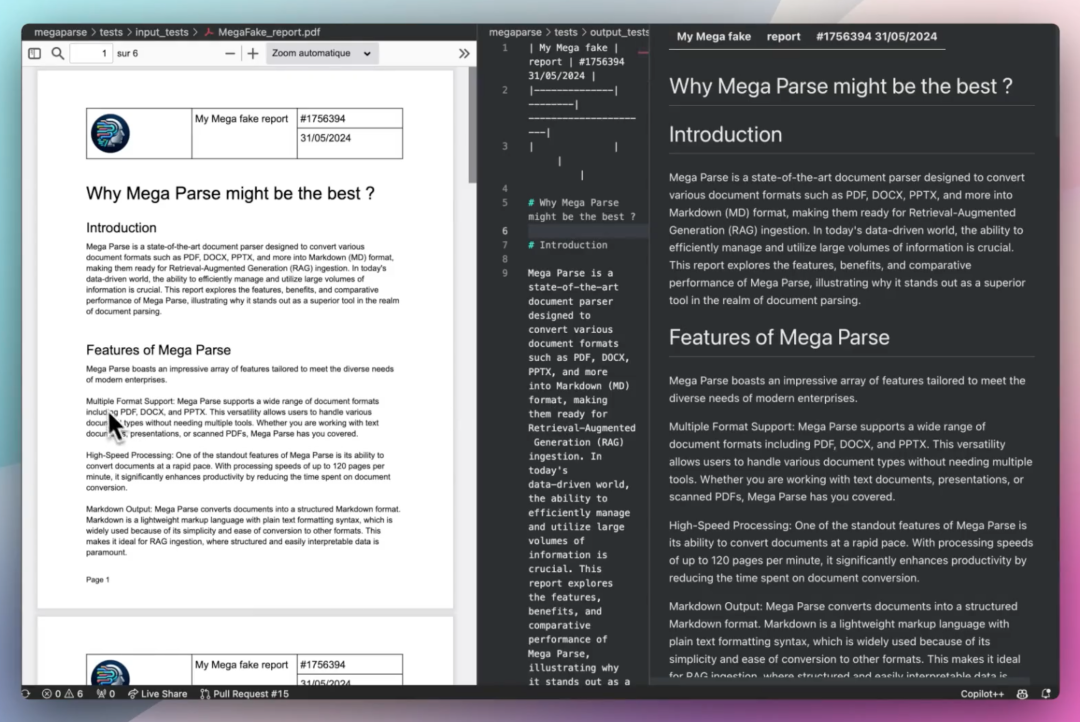
### 项目介绍
MegaParse 是一款功能强大的文档解析工具,它的主要特点包括:
- 支持多种文件格式,包括 PDF、PPT、Word 等常用文档类型;
- 保证解析过程中不会丢失任何信息;
- 能够准确识别文档中的表格、目录、页眉页脚和图片;
- 解析速度快,效率高;
- 完全开源,可以免费使用。
### 安装指南
安装 MegaParse 非常简单,只需要通过 pip 包管理器执行以下命令:
-
```csharp
pip install megaparse
```
此外,在安装 MegaParse 之前,我们还需要:
1. 准备 OpenAI API 密钥;
2. 安装 poppler(用于处理图片和 PDF);
3. 安装 tesseract(用于处理图片和 PDF)。
### 使用指南
MegaParse 的使用方法非常直观。下面是一个基本的示例代码:
-
-
-
-
-
-
-
-
-
-
-
-
-
```csharp
from megaparse import MegaParse# 创建 MegaParse 实例megaparse = MegaParse(file_path="./test.pdf")# 加载并解析文档document = megaparse.load()# 打印解析结果print(document.page_content)# 将结果保存为 Markdown 文件megaparse.save_md(document.page_content, "./test.md")
```
如果想要获得更好的解析效果,我们还可以使用 LlamaParse 服务。
只需要在 Llama Cloud 注册账号获取 API 密钥,然后在创建 MegaParse 实例时传入即可:
-
```csharp
megaparse = MegaParse(file_path="./test.pdf", llama_parse_api_key="llx-your_api_key")
```
### 工具演示
### 写在最后
通过使用 MegaParse,我们再也不用为处理各种格式的文档而烦恼了。
无论是快速提取 PDF 中的表格数据,还是批量转换 PPT 内容,都能更加高效地完成工作。
对于经常需要处理文档的开发者、数据分析师或者文档管理人员来说,MegaParse 绝对是一个不可多错过的效率工具。
本文来自投稿,不代表本站立场,如若转载,请注明出处:http//www.knowhub.vip/share/4/2198
相关资源
文档解析器 MegaParse
查看内容
- 热门的软件工具分享
- 1 . 旷野书屋:满足多元阅读需求的免费小说阅读软件
- 2 . SheetDataMerge: 快速合并Excel工作表数据的小工具
- 3 . 微商管家最新解锁版》:多功能助力社交营销工具
- 4 . AI写作创作家解锁会员版:高效手机文案写作
- 5 . 最新含4K蓝光线路影视APP破解版,免费无码!下饭追剧神器!
- 6 . 趣映APP解锁视频剪辑VIP会员版,无需登录支持高清,支持沙雕视频制作
- 7 . 糖豆广场舞 app 解锁版:锻炼爱好者的视频宝库
- 8 . 逻辑电路模拟器专业版:强大的电路设计与模拟软件
- 9 . 埃文斯成语词典:畅享成语与诗词的免费学习利器
- 10 . 小虎队软件库:丰富多样的免费软件资源库
- 11 . 《无敌驾考解锁版》:助力驾照考试轻松备考
- 12 . 《黑神话:悟空》35项修改器助力游戏体验(风灵月影)
- 13 . 燎原小说:无广告且超百书源的免费阅读神器
- 14 . 七猫免费小说:无广告且会员解锁的优质阅读应用
- 15 . 梨园行戏曲TV修改版,听戏看戏必备(会员以解锁)
- 16 . iPhone限免儿童学习拼图APP,2 - 5岁孩子的趣味学习
- 17 . HideRarInImage: 小巧实用的文件隐藏工具
- 18 . 音编美声:功能强大且操作便捷的音乐剪辑软件
- 19 . 百万软件库:丰富软件资源的在线分享与安全保障平台
- 20 . Souman漫画:分类分区与特色功能